Towards Attention-based Contrastive Learning for Audio Spoof Detection

0
Sign in to get full access
Overview
- The paper proposes a novel attention-based contrastive learning approach for audio spoof detection.
- The goal is to learn robust and discriminative representations that can distinguish between real and spoofed audio samples.
- The approach leverages attention mechanisms to capture important audio features and contrastive learning to learn a powerful audio representation.
Plain English Explanation
The paper is about a new way to detect if an audio recording is real or fake (spoofed). The researchers developed a method that uses attention mechanisms to identify the important parts of the audio. It then uses contrastive learning to learn a strong representation that can tell the difference between real and spoofed audio. The key idea is to learn features that can clearly distinguish real from fake recordings, which is important for applications like voice authentication and anti-spoofing. By focusing on the relevant parts of the audio and using a clever training approach, the method aims to be more effective at this task compared to previous techniques.
Technical Explanation
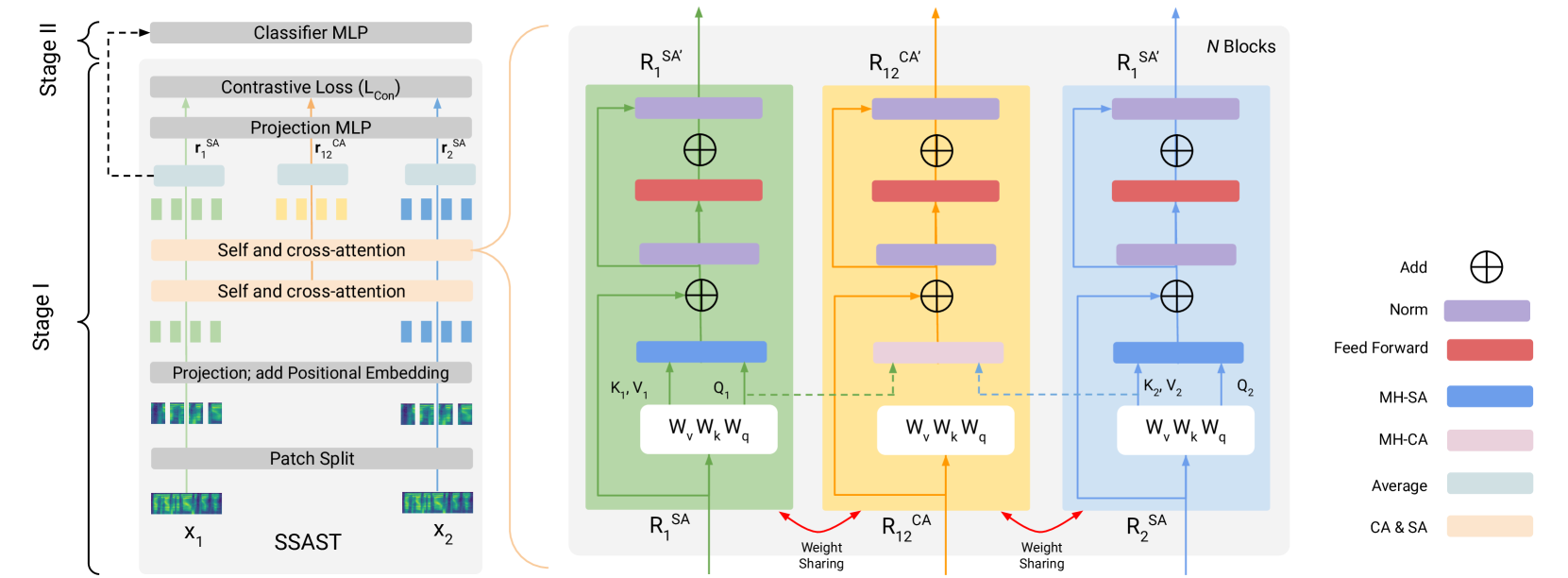
The paper proposes an attention-based contrastive learning approach for audio spoof detection. The core idea is to learn robust and discriminative audio representations that can effectively distinguish between real and spoofed audio samples.
The proposed model uses a temporal convolutional network (TCN) as the backbone to extract audio features. An attention module is then applied to the TCN features to selectively focus on the most informative parts of the audio.
The attended features are then passed through a contrastive learning framework, which aims to learn a powerful audio representation by maximizing the similarity between samples of the same class (real or spoofed) and minimizing the similarity between samples of different classes. This helps the model learn discriminative features that can reliably detect audio spoofing.
The authors evaluate their approach on several audio spoof detection datasets and show that it outperforms previous state-of-the-art methods, demonstrating the effectiveness of the attention-based contrastive learning strategy for this task.
Critical Analysis
The paper presents a well-designed and empirically validated approach for audio spoof detection. The use of attention mechanisms to focus on the most relevant audio features, coupled with the contrastive learning objective, appears to be a promising direction for learning robust and discriminative representations for this problem.
However, the paper does not discuss potential limitations or caveats of the proposed method. For example, the approach may be sensitive to certain types of spoofing attacks or audio distortions, and its generalization to real-world scenarios with diverse spoofing techniques could be further evaluated.
Additionally, the paper could have explored the interpretability of the learned attention weights and representations, as this could provide valuable insights into the model's decision-making process and potentially lead to improvements in the method.
Overall, the paper presents a solid contribution to the field of audio spoof detection, and the attention-based contrastive learning approach is a compelling direction for future research in this area.
Conclusion
This paper introduces a novel attention-based contrastive learning method for audio spoof detection. By leveraging attention mechanisms to focus on the most informative audio features and using contrastive learning to learn a powerful discriminative representation, the proposed approach demonstrates state-of-the-art performance on several benchmark datasets.
The key innovation of this work is the integration of attention and contrastive learning for the audio spoof detection task, which could have broader implications for other audio-related applications that require robust and discriminative representations. As voice authentication and anti-spoofing technologies become increasingly important, this research provides a promising step forward in developing more reliable and secure systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Attention-based Contrastive Learning for Audio Spoof Detection
Chirag Goel, Surya Koppisetti, Ben Colman, Ali Shahriyari, Gaurav Bharaj
Vision transformers (ViT) have made substantial progress for classification tasks in computer vision. Recently, Gong et. al. '21, introduced attention-based modeling for several audio tasks. However, relatively unexplored is the use of a ViT for audio spoof detection task. We bridge this gap and introduce ViTs for this task. A vanilla baseline built on fine-tuning the SSAST (Gong et. al. '22) audio ViT model achieves sub-optimal equal error rates (EERs). To improve performance, we propose a novel attention-based contrastive learning framework (SSAST-CL) that uses cross-attention to aid the representation learning. Experiments show that our framework successfully disentangles the bonafide and spoof classes and helps learn better classifiers for the task. With appropriate data augmentations policy, a model trained on our framework achieves competitive performance on the ASVSpoof 2021 challenge. We provide comparisons and ablation studies to justify our claim.
Read more7/8/2024

0
Toward Improving Synthetic Audio Spoofing Detection Robustness via Meta-Learning and Disentangled Training With Adversarial Examples
Zhenyu Wang, John H. L. Hansen
Advances in automatic speaker verification (ASV) promote research into the formulation of spoofing detection systems for real-world applications. The performance of ASV systems can be degraded severely by multiple types of spoofing attacks, namely, synthetic speech (SS), voice conversion (VC), replay, twins and impersonation, especially in the case of unseen synthetic spoofing attacks. A reliable and robust spoofing detection system can act as a security gate to filter out spoofing attacks instead of having them reach the ASV system. A weighted additive angular margin loss is proposed to address the data imbalance issue, and different margins has been assigned to improve generalization to unseen spoofing attacks in this study. Meanwhile, we incorporate a meta-learning loss function to optimize differences between the embeddings of support versus query set in order to learn a spoofing-category-independent embedding space for utterances. Furthermore, we craft adversarial examples by adding imperceptible perturbations to spoofing speech as a data augmentation strategy, then we use an auxiliary batch normalization (BN) to guarantee that corresponding normalization statistics are performed exclusively on the adversarial examples. Additionally, A simple attention module is integrated into the residual block to refine the feature extraction process. Evaluation results on the Logical Access (LA) track of the ASVspoof 2019 corpus provides confirmation of our proposed approaches' effectiveness in terms of a pooled EER of 0.87%, and a min t-DCF of 0.0277. These advancements offer effective options to reduce the impact of spoofing attacks on voice recognition/authentication systems.
Read more8/27/2024

0
Interpretable Temporal Class Activation Representation for Audio Spoofing Detection
Menglu Li, Xiao-Ping Zhang
Explaining the decisions made by audio spoofing detection models is crucial for fostering trust in detection outcomes. However, current research on the interpretability of detection models is limited to applying XAI tools to post-trained models. In this paper, we utilize the wav2vec 2.0 model and attentive utterance-level features to integrate interpretability directly into the model's architecture, thereby enhancing transparency of the decision-making process. Specifically, we propose a class activation representation to localize the discriminative frames contributing to detection. Furthermore, we demonstrate that multi-label training based on spoofing types, rather than binary labels as bonafide and spoofed, enables the model to learn distinct characteristics of different attacks, significantly improving detection performance. Our model achieves state-of-the-art results, with an EER of 0.51% and a min t-DCF of 0.0165 on the ASVspoof2019-LA set.
Read more6/18/2024

0
EAViT: External Attention Vision Transformer for Audio Classification
Aquib Iqbal, Abid Hasan Zim, Md Asaduzzaman Tonmoy, Limengnan Zhou, Asad Malik, Minoru Kuribayashi
This paper presents the External Attention Vision Transformer (EAViT) model, a novel approach designed to enhance audio classification accuracy. As digital audio resources proliferate, the demand for precise and efficient audio classification systems has intensified, driven by the need for improved recommendation systems and user personalization in various applications, including music streaming platforms and environmental sound recognition. Accurate audio classification is crucial for organizing vast audio libraries into coherent categories, enabling users to find and interact with their preferred audio content more effectively. In this study, we utilize the GTZAN dataset, which comprises 1,000 music excerpts spanning ten diverse genres. Each 30-second audio clip is segmented into 3-second excerpts to enhance dataset robustness and mitigate overfitting risks, allowing for more granular feature analysis. The EAViT model integrates multi-head external attention (MEA) mechanisms into the Vision Transformer (ViT) framework, effectively capturing long-range dependencies and potential correlations between samples. This external attention (EA) mechanism employs learnable memory units that enhance the network's capacity to process complex audio features efficiently. The study demonstrates that EAViT achieves a remarkable overall accuracy of 93.99%, surpassing state-of-the-art models.
Read more8/26/2024