EAViT: External Attention Vision Transformer for Audio Classification

0

Sign in to get full access
Overview
- EAViT is a new audio classification model that uses an "external attention" mechanism to improve performance.
- The model combines a Vision Transformer architecture with an external attention module to capture long-range dependencies in audio data.
- Experiments show EAViT outperforms standard Vision Transformers and other state-of-the-art audio classification models.
Plain English Explanation
EAViT: External Attention Vision Transformer for Audio Classification is a new deep learning model designed for classifying audio data. It builds upon the successful Vision Transformer architecture, which has shown impressive performance on image recognition tasks.
The key innovation in EAViT is the addition of an "external attention" module. This module allows the model to capture long-range dependencies in the audio input, which is important for many audio classification problems. By incorporating this external attention mechanism, EAViT is able to outperform standard Vision Transformers and other state-of-the-art audio models on benchmark datasets.
The external attention module works by taking the output features from the Vision Transformer and passing them through an additional attention layer. This allows the model to learn relationships between different parts of the audio input, which can be crucial for accurately classifying things like speech, music, or environmental sounds.
Overall, EAViT demonstrates how techniques from computer vision can be effectively applied to audio data, leading to improved performance on a range of audio classification tasks. The external attention mechanism is a key innovation that helps the model better understand the complex structure of audio signals.
Technical Explanation
The EAViT model is built upon the Vision Transformer (ViT) architecture, which has shown state-of-the-art performance on various image recognition tasks. To adapt ViT for audio classification, the authors introduce an "External Attention" module that captures long-range dependencies in the audio input.
The overall EAViT architecture consists of:
- Audio Preprocessing: The raw audio waveform is first transformed into a time-frequency representation using a short-time Fourier transform (STFT).
- Vision Transformer: The STFT representation is then fed into a standard ViT model, which applies a series of self-attention and feed-forward layers to extract high-level features.
- External Attention: The ViT output features are passed through an additional attention mechanism, which learns to capture long-range dependencies in the audio data.
- Classification Head: The output of the external attention module is then used for the final audio classification task.
The key advantage of the external attention module is that it allows the model to explicitly model relationships between different parts of the audio input, which is crucial for many audio classification problems. This is in contrast to the standard ViT self-attention, which only considers local neighborhoods.
The authors evaluate EAViT on several audio classification benchmarks, including AudioSet and ESC-50. Their results show that EAViT outperforms both standard ViT and other state-of-the-art audio classification models, demonstrating the effectiveness of the external attention mechanism.
Critical Analysis
The EAViT paper presents a promising approach for adapting Vision Transformer models to audio classification tasks. The external attention module is a well-motivated addition that allows the model to better capture the long-range dependencies in audio data.
However, the paper does not provide a deep analysis of the limitations or potential issues with the EAViT approach. For example, it would be interesting to understand how the external attention module compares to other attention mechanisms, such as those used in Transformer-based audio models or contrastive learning methods for audio.
Additionally, the paper focuses on relatively simple audio classification tasks and does not explore more complex audio understanding problems, such as audio-visual learning or audio source separation. Expanding the evaluation to a wider range of audio-related tasks could provide more insight into the strengths and weaknesses of the EAViT approach.
Overall, the EAViT paper presents an interesting and effective way to adapt Vision Transformers for audio classification. However, further research is needed to fully understand the capabilities and limitations of this approach, especially compared to other state-of-the-art audio models.
Conclusion
The EAViT: External Attention Vision Transformer for Audio Classification paper introduces a new deep learning model that combines the power of Vision Transformers with an external attention mechanism to improve audio classification performance. By explicitly modeling long-range dependencies in the audio input, EAViT is able to outperform standard Vision Transformers and other state-of-the-art audio models on benchmark datasets.
This work demonstrates the potential for techniques developed in computer vision to be successfully applied to audio data, opening up new avenues for innovation in audio machine learning. The external attention module is a key contribution that could inspire further research into effective attention mechanisms for audio understanding tasks.
While the paper focuses on relatively simple audio classification problems, the EAViT approach could potentially be extended to tackle more complex audio-related challenges, such as audio-visual learning or audio source separation. Further research in these areas could unlock even greater advances in the field of audio machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EAViT: External Attention Vision Transformer for Audio Classification
Aquib Iqbal, Abid Hasan Zim, Md Asaduzzaman Tonmoy, Limengnan Zhou, Asad Malik, Minoru Kuribayashi
This paper presents the External Attention Vision Transformer (EAViT) model, a novel approach designed to enhance audio classification accuracy. As digital audio resources proliferate, the demand for precise and efficient audio classification systems has intensified, driven by the need for improved recommendation systems and user personalization in various applications, including music streaming platforms and environmental sound recognition. Accurate audio classification is crucial for organizing vast audio libraries into coherent categories, enabling users to find and interact with their preferred audio content more effectively. In this study, we utilize the GTZAN dataset, which comprises 1,000 music excerpts spanning ten diverse genres. Each 30-second audio clip is segmented into 3-second excerpts to enhance dataset robustness and mitigate overfitting risks, allowing for more granular feature analysis. The EAViT model integrates multi-head external attention (MEA) mechanisms into the Vision Transformer (ViT) framework, effectively capturing long-range dependencies and potential correlations between samples. This external attention (EA) mechanism employs learnable memory units that enhance the network's capacity to process complex audio features efficiently. The study demonstrates that EAViT achieves a remarkable overall accuracy of 93.99%, surpassing state-of-the-art models.
Read more8/26/2024
0
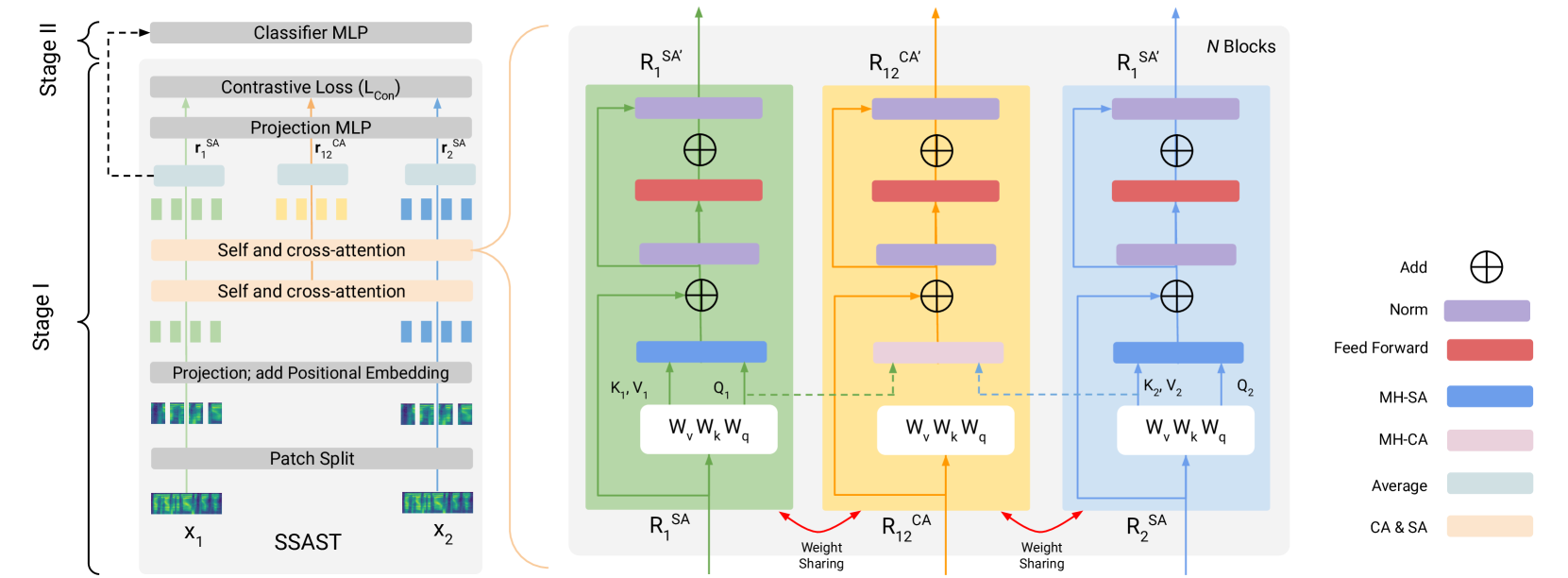
Towards Attention-based Contrastive Learning for Audio Spoof Detection
Chirag Goel, Surya Koppisetti, Ben Colman, Ali Shahriyari, Gaurav Bharaj
Vision transformers (ViT) have made substantial progress for classification tasks in computer vision. Recently, Gong et. al. '21, introduced attention-based modeling for several audio tasks. However, relatively unexplored is the use of a ViT for audio spoof detection task. We bridge this gap and introduce ViTs for this task. A vanilla baseline built on fine-tuning the SSAST (Gong et. al. '22) audio ViT model achieves sub-optimal equal error rates (EERs). To improve performance, we propose a novel attention-based contrastive learning framework (SSAST-CL) that uses cross-attention to aid the representation learning. Experiments show that our framework successfully disentangles the bonafide and spoof classes and helps learn better classifiers for the task. With appropriate data augmentations policy, a model trained on our framework achieves competitive performance on the ASVSpoof 2021 challenge. We provide comparisons and ablation studies to justify our claim.
Read more7/8/2024
👁️
0
Multimodal Emotion Recognition using Audio-Video Transformer Fusion with Cross Attention
Joe Dhanith P R, Shravan Venkatraman, Modigari Narendra, Vigya Sharma, Santhosh Malarvannan, Amir H. Gandomi
Understanding emotions is a fundamental aspect of human communication. Integrating audio and video signals offers a more comprehensive understanding of emotional states compared to traditional methods that rely on a single data source, such as speech or facial expressions. Despite its potential, multimodal emotion recognition faces significant challenges, particularly in synchronization, feature extraction, and fusion of diverse data sources. To address these issues, this paper introduces a novel transformer-based model named Audio-Video Transformer Fusion with Cross Attention (AVT-CA). The AVT-CA model employs a transformer fusion approach to effectively capture and synchronize interlinked features from both audio and video inputs, thereby resolving synchronization problems. Additionally, the Cross Attention mechanism within AVT-CA selectively extracts and emphasizes critical features while discarding irrelevant ones from both modalities, addressing feature extraction and fusion challenges. Extensive experimental analysis conducted on the CMU-MOSEI, RAVDESS and CREMA-D datasets demonstrates the efficacy of the proposed model. The results underscore the importance of AVT-CA in developing precise and reliable multimodal emotion recognition systems for practical applications.
Read more8/16/2024

0
MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
Read more6/10/2024