Counterfactual Debating with Preset Stances for Hallucination Elimination of LLMs

0
Sign in to get full access
Overview
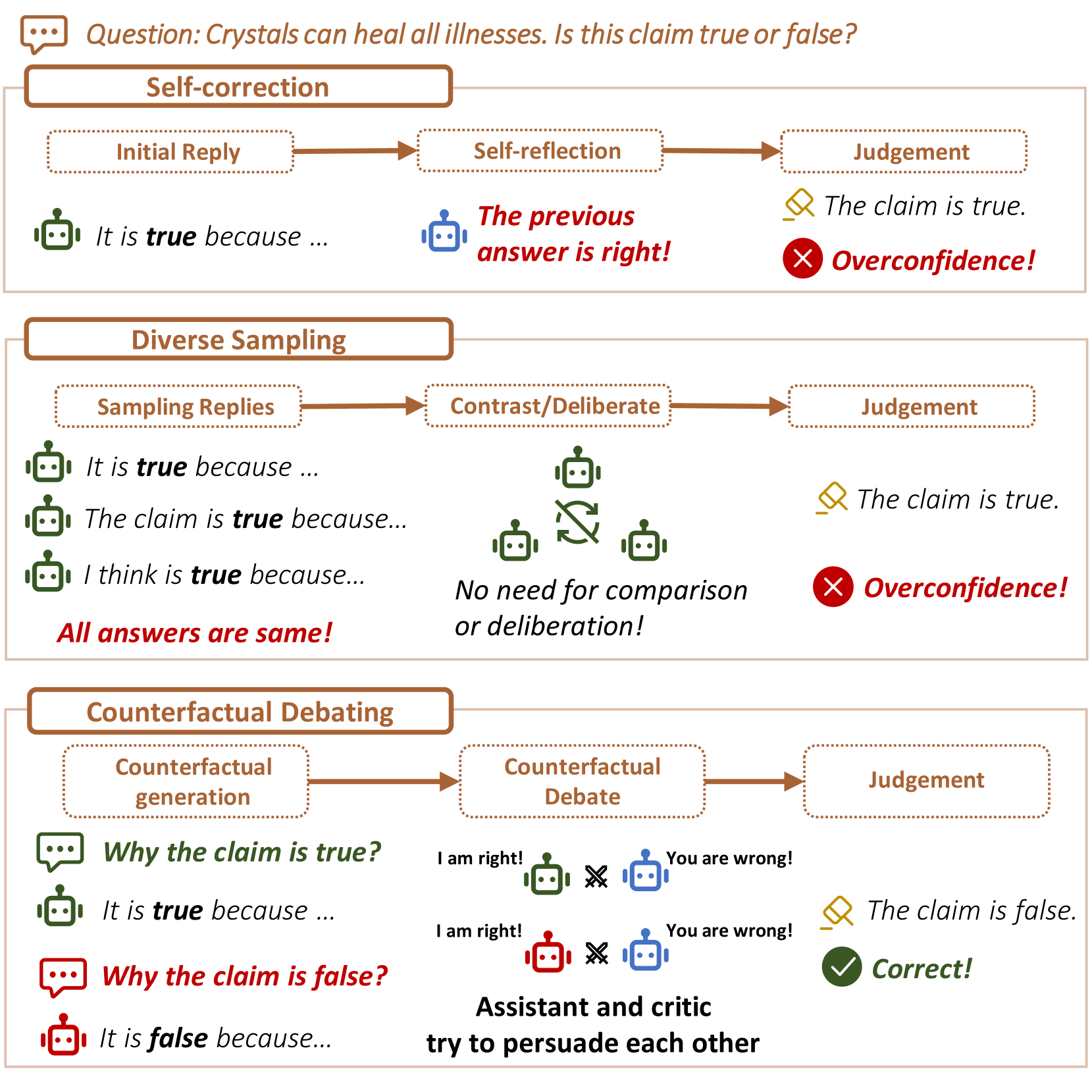
- This paper presents a novel approach called "Counterfactual Debating with Preset Stances" to mitigate hallucinations in large language models (LLMs).
- Hallucination refers to the generation of factually incorrect or nonsensical content by LLMs, which is a significant challenge in the field of natural language processing.
- The proposed method aims to eliminate hallucinations by engaging the LLM in a debate where it is forced to consider and argue for opposing viewpoints on a given topic.
Plain English Explanation
The paper introduces a technique to help prevent large language models (LLMs) from generating false or nonsensical information, a problem known as hallucination. The key idea is to have the LLM engage in a "debate" where it is required to consider and argue for multiple viewpoints on a topic, rather than just generating a single response.
Imagine you ask an LLM a question, and it provides an answer that seems plausible but is actually made up or incorrect. The "Counterfactual Debating" approach would instead present the LLM with a set of pre-defined stances or viewpoints on the topic, and then have the LLM argue for each of those perspectives in turn. Link to paper on comprehensive study of LLMs generating counterfactuals
By forcing the LLM to consider multiple angles on the issue, the researchers hope to reduce the likelihood that it will hallucinate or generate false information. The idea is that the back-and-forth of the debate will help the LLM better understand the topic and provide more grounded, truthful responses. Link to paper on using hallucinating models to reduce human hallucination
Technical Explanation
The paper outlines a novel approach called "Counterfactual Debating with Preset Stances" to address the problem of hallucination in large language models (LLMs). Hallucination refers to the generation of factually incorrect or nonsensical content by LLMs, which is a significant challenge in the field of natural language processing.
The key innovation of the proposed method is to engage the LLM in a debate where it is required to consider and argue for multiple preset stances or viewpoints on a given topic. This is in contrast to the typical approach where the LLM is asked to generate a single response. Link to paper on detecting LLM hallucination via Markov chain
The researchers conduct preliminary experiments to validate the effectiveness of their approach. They compare the performance of the LLM when engaging in counterfactual debating versus generating a single response. The results suggest that the debating approach can significantly reduce the occurrence of hallucinations, while also improving the overall quality and coherence of the LLM's outputs. Link to paper on mitigating LLM hallucination through faithful fine-tuning
Critical Analysis
The paper presents a promising approach to addressing the hallucination problem in large language models, but there are a few potential limitations and areas for further research:
-
The paper focuses on the initial feasibility of the counterfactual debating approach, but does not provide a comprehensive evaluation across a wide range of topics and tasks. More extensive testing would be needed to fully assess the generalizability and robustness of the method.
-
The paper does not explicitly address the potential computational overhead and training complexity introduced by the debating process. Engaging the LLM in multiple rounds of debate could significantly increase the time and resources required, which may limit the practical deployment of this approach.
-
The preset stances used in the debating process are manually curated by the researchers. Developing a systematic way to automatically generate diverse and representative viewpoints could be an important area for future work. Link to paper on benchmarking counterfactual reasoning abilities
Overall, the "Counterfactual Debating with Preset Stances" approach is a promising step towards mitigating hallucinations in large language models, but additional research is needed to fully understand its limitations and potential real-world applications.
Conclusion
This paper presents a novel technique called "Counterfactual Debating with Preset Stances" to address the problem of hallucination in large language models. By forcing the LLM to consider and argue for multiple viewpoints on a given topic, the researchers aim to reduce the likelihood of the model generating factually incorrect or nonsensical content.
The preliminary experiments conducted in the paper suggest that this debating approach can effectively mitigate hallucinations while also improving the overall quality and coherence of the LLM's outputs. However, more extensive evaluation and further research are needed to fully assess the generalizability, scalability, and practical implications of this method.
As large language models continue to play an increasingly important role in various applications, developing robust techniques to address their shortcomings, such as hallucination, will be crucial for ensuring the reliability and trustworthiness of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Counterfactual Debating with Preset Stances for Hallucination Elimination of LLMs
Yi Fang, Moxin Li, Wenjie Wang, Hui Lin, Fuli Feng
Large Language Models (LLMs) excel in various natural language processing tasks but struggle with hallucination issues. Existing solutions have considered utilizing LLMs' inherent reasoning abilities to alleviate hallucination, such as self-correction and diverse sampling methods. However, these methods often overtrust LLMs' initial answers due to inherent biases. The key to alleviating this issue lies in overriding LLMs' inherent biases for answer inspection. To this end, we propose a CounterFactual Multi-Agent Debate (CFMAD) framework. CFMAD presets the stances of LLMs to override their inherent biases by compelling LLMs to generate justifications for a predetermined answer's correctness. The LLMs with different predetermined stances are engaged with a skeptical critic for counterfactual debate on the rationality of generated justifications. Finally, the debate process is evaluated by a third-party judge to determine the final answer. Extensive experiments on four datasets of three tasks demonstrate the superiority of CFMAD over existing methods.
Read more6/18/2024
0
Towards Detecting LLMs Hallucination via Markov Chain-based Multi-agent Debate Framework
Xiaoxi Sun, Jinpeng Li, Yan Zhong, Dongyan Zhao, Rui Yan
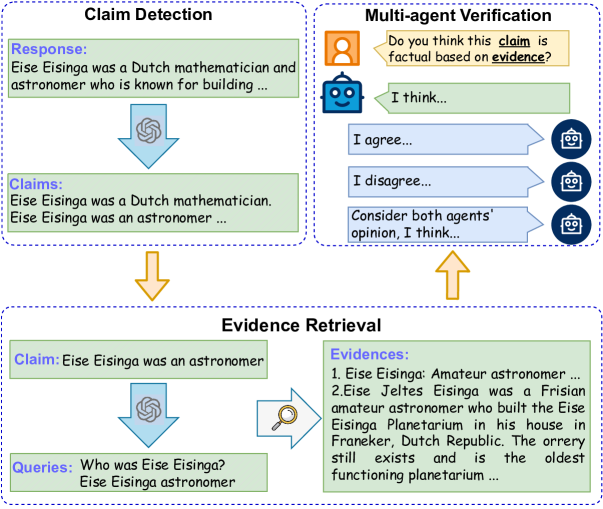
The advent of large language models (LLMs) has facilitated the development of natural language text generation. It also poses unprecedented challenges, with content hallucination emerging as a significant concern. Existing solutions often involve expensive and complex interventions during the training process. Moreover, some approaches emphasize problem disassembly while neglecting the crucial validation process, leading to performance degradation or limited applications. To overcome these limitations, we propose a Markov Chain-based multi-agent debate verification framework to enhance hallucination detection accuracy in concise claims. Our method integrates the fact-checking process, including claim detection, evidence retrieval, and multi-agent verification. In the verification stage, we deploy multiple agents through flexible Markov Chain-based debates to validate individual claims, ensuring meticulous verification outcomes. Experimental results across three generative tasks demonstrate that our approach achieves significant improvements over baselines.
Read more6/6/2024

0
What if...?: Thinking Counterfactual Keywords Helps to Mitigate Hallucination in Large Multi-modal Models
Junho Kim, Yeon Ju Kim, Yong Man Ro
This paper presents a way of enhancing the reliability of Large Multi-modal Models (LMMs) in addressing hallucination, where the models generate cross-modal inconsistent responses. Without additional training, we propose Counterfactual Inception, a novel method that implants counterfactual thinking into LMMs using self-generated counterfactual keywords. Our method is grounded in the concept of counterfactual thinking, a cognitive process where human considers alternative realities, enabling more extensive context exploration. Bridging the human cognition mechanism into LMMs, we aim for the models to engage with and generate responses that span a wider contextual scene understanding, mitigating hallucinatory outputs. We further introduce Plausibility Verification Process (PVP), a simple yet robust keyword constraint that effectively filters out sub-optimal keywords to enable the consistent triggering of counterfactual thinking in the model responses. Comprehensive analyses across various LMMs, including both open-source and proprietary models, corroborate that counterfactual thinking significantly reduces hallucination and helps to broaden contextual understanding based on true visual clues.
Read more6/24/2024

0
LLMs for Generating and Evaluating Counterfactuals: A Comprehensive Study
Van Bach Nguyen, Paul Youssef, Jorg Schlotterer, Christin Seifert
As NLP models become more complex, understanding their decisions becomes more crucial. Counterfactuals (CFs), where minimal changes to inputs flip a model's prediction, offer a way to explain these models. While Large Language Models (LLMs) have shown remarkable performance in NLP tasks, their efficacy in generating high-quality CFs remains uncertain. This work fills this gap by investigating how well LLMs generate CFs for two NLU tasks. We conduct a comprehensive comparison of several common LLMs, and evaluate their CFs, assessing both intrinsic metrics, and the impact of these CFs on data augmentation. Moreover, we analyze differences between human and LLM-generated CFs, providing insights for future research directions. Our results show that LLMs generate fluent CFs, but struggle to keep the induced changes minimal. Generating CFs for Sentiment Analysis (SA) is less challenging than NLI where LLMs show weaknesses in generating CFs that flip the original label. This also reflects on the data augmentation performance, where we observe a large gap between augmenting with human and LLMs CFs. Furthermore, we evaluate LLMs' ability to assess CFs in a mislabelled data setting, and show that they have a strong bias towards agreeing with the provided labels. GPT4 is more robust against this bias and its scores correlate well with automatic metrics. Our findings reveal several limitations and point to potential future work directions.
Read more5/3/2024