Towards Generating Diverse Audio Captions via Adversarial Training

0
🏋️
Sign in to get full access
Overview
- Automated audio captioning is the task of describing the content of audio clips using natural language sentences.
- Existing models generate captions that are faithful to the audio content but often lack diversity, using common words, simple grammar, and similar captions for similar audio.
- The paper proposes an adversarial training framework based on a conditional generative adversarial network (C-GAN) to improve the diversity of audio captioning systems.
Plain English Explanation
The paper is about a task called "automated audio captioning," which is the process of describing the contents of an audio clip using normal, everyday language. For example, if you had an audio recording of a dog barking, an audio captioning system would try to generate a sentence like "A dog is barking" to describe what's happening in the audio.
The problem is that the captions generated by existing audio captioning models are often very basic and similar, even for different audio clips. For instance, the model might generate the same "A dog is barking" caption for several different dog barking sounds. But when humans listen to audio, they tend to focus on different aspects and describe the content in more diverse ways.
To address this, the researchers propose a new training approach that uses an adversarial network, similar to a GAN. This helps the captioning model learn to generate more varied and natural-sounding captions, either for a single audio clip or across similar audio clips. The key idea is to have the captioning model compete against two discriminators that assess the generated captions - one for how natural they sound, and one for how well they capture the semantics of the audio.
Technical Explanation
The paper presents an adversarial training framework based on a conditional generative adversarial network (C-GAN) to improve the diversity of audio captioning systems. The framework consists of a caption generator model, which can be any standard encoder-decoder captioning model, and two hybrid discriminators that assess the generated captions.
The first discriminator evaluates the naturalness of the generated captions, ensuring they sound like natural human-written text. The second discriminator assesses the semantics of the captions, checking that they accurately reflect the content of the corresponding audio clip.
The caption generator and the two discriminators are trained jointly in an adversarial manner. The generator tries to produce captions that can fool the discriminators, while the discriminators strive to accurately distinguish the machine-generated captions from human-written ones.
The authors evaluate their approach on the Clotho dataset, a benchmark for audio captioning. The results show that their proposed model can generate captions with better diversity compared to state-of-the-art methods.
Critical Analysis
The paper presents a novel and promising approach to improve the diversity of audio captioning systems. The use of adversarial training with hybrid discriminators is a clever way to encourage the captioning model to generate more varied and natural-sounding descriptions.
However, the paper does not provide a detailed analysis of the trade-offs between diversity and other important metrics, such as caption quality or caption relevance. It's possible that increasing diversity could come at the cost of reduced accuracy or relevance of the generated captions.
Additionally, the paper does not explore the potential for large language models to further enhance the diversity and quality of audio captions. Incorporating such models could be a promising direction for future research.
Conclusion
The paper proposes an innovative adversarial training approach to improve the diversity of audio captioning systems. By using a caption generator that competes against discriminators evaluating the naturalness and semantics of the generated captions, the model is able to produce more varied and human-like descriptions of audio content.
This research represents an important step forward in the field of audio captioning, which has significant potential applications in areas like accessibility, content discovery, and multimedia understanding. The ability to generate diverse and accurate captions could greatly enhance the user experience and accessibility of audio-based media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Towards Generating Diverse Audio Captions via Adversarial Training
Xinhao Mei, Xubo Liu, Jianyuan Sun, Mark D. Plumbley, Wenwu Wang
Automated audio captioning is a cross-modal translation task for describing the content of audio clips with natural language sentences. This task has attracted increasing attention and substantial progress has been made in recent years. Captions generated by existing models are generally faithful to the content of audio clips, however, these machine-generated captions are often deterministic (e.g., generating a fixed caption for a given audio clip), simple (e.g., using common words and simple grammar), and generic (e.g., generating the same caption for similar audio clips). When people are asked to describe the content of an audio clip, different people tend to focus on different sound events and describe an audio clip diversely from various aspects using distinct words and grammar. We believe that an audio captioning system should have the ability to generate diverse captions, either for a fixed audio clip, or across similar audio clips. To this end, we propose an adversarial training framework based on a conditional generative adversarial network (C-GAN) to improve diversity of audio captioning systems. A caption generator and two hybrid discriminators compete and are learned jointly, where the caption generator can be any standard encoder-decoder captioning model used to generate captions, and the hybrid discriminators assess the generated captions from different criteria, such as their naturalness and semantics. We conduct experiments on the Clotho dataset. The results show that our proposed model can generate captions with better diversity as compared to state-of-the-art methods.
Read more7/2/2024
0
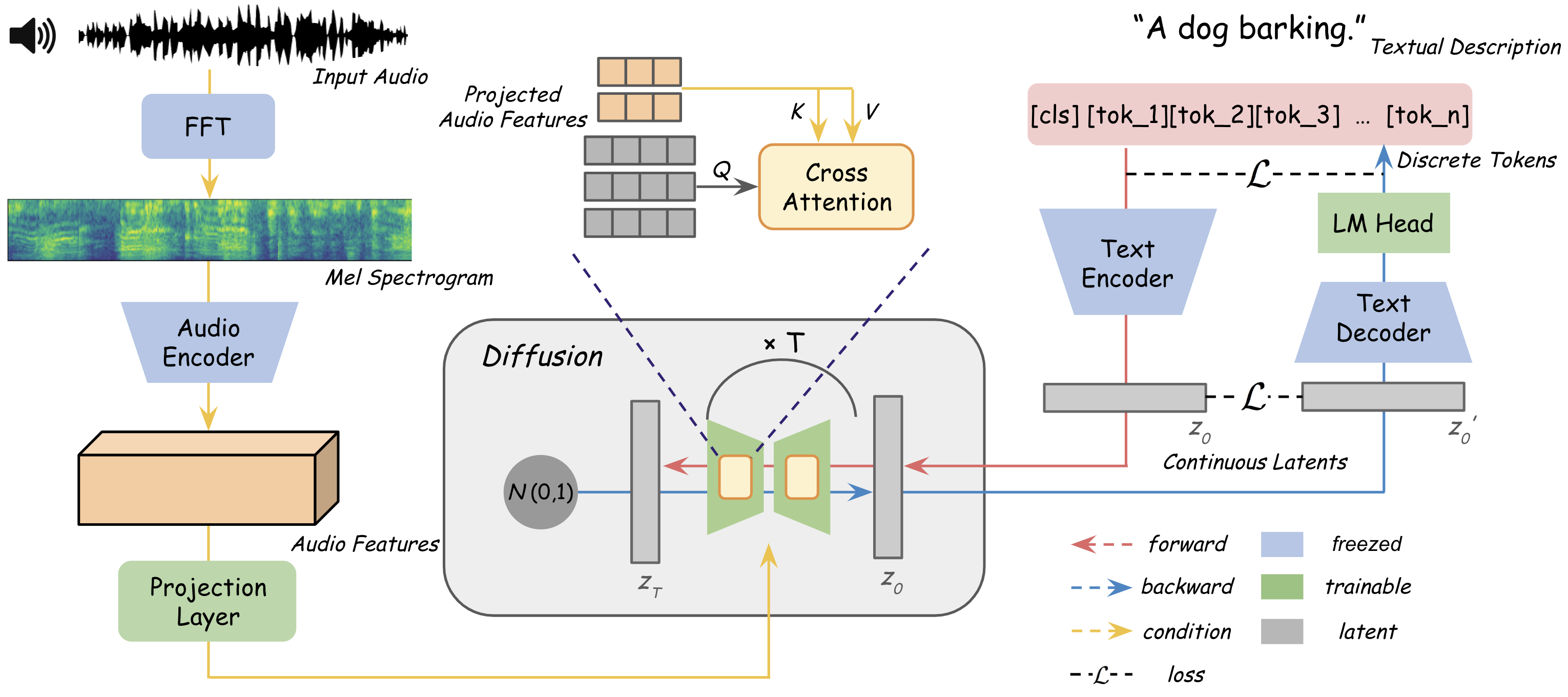
Towards Diverse and Efficient Audio Captioning via Diffusion Models
Manjie Xu, Chenxing Li, Xinyi Tu, Yong Ren, Ruibo Fu, Wei Liang, Dong Yu
We introduce Diffusion-based Audio Captioning (DAC), a non-autoregressive diffusion model tailored for diverse and efficient audio captioning. Although existing captioning models relying on language backbones have achieved remarkable success in various captioning tasks, their insufficient performance in terms of generation speed and diversity impede progress in audio understanding and multimedia applications. Our diffusion-based framework offers unique advantages stemming from its inherent stochasticity and holistic context modeling in captioning. Through rigorous evaluation, we demonstrate that DAC not only achieves SOTA performance levels compared to existing benchmarks in the caption quality, but also significantly outperforms them in terms of generation speed and diversity. The success of DAC illustrates that text generation can also be seamlessly integrated with audio and visual generation tasks using a diffusion backbone, paving the way for a unified, audio-related generative model across different modalities.
Read more9/17/2024

0
Improving Audio Generation with Visual Enhanced Caption
Yi Yuan, Dongya Jia, Xiaobin Zhuang, Yuanzhe Chen, Zhengxi Liu, Zhuo Chen, Yuping Wang, Yuxuan Wang, Xubo Liu, Xiyuan Kang, Mark D. Plumbley, Wenwu Wang
Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the simplicity and scarcity of the training data. This work aims to create a large-scale audio dataset with rich captions for improving audio generation models. We first develop an automated pipeline to generate detailed captions by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). The resulting dataset, Sound-VECaps, comprises 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We then demonstrate that training the text-to-audio generation models with Sound-VECaps significantly improves the performance on complex prompts. Furthermore, we conduct ablation studies of the models on several downstream audio-language tasks, showing the potential of Sound-VECaps in advancing audio-text representation learning. Our dataset and models are available online.
Read more8/16/2024
0
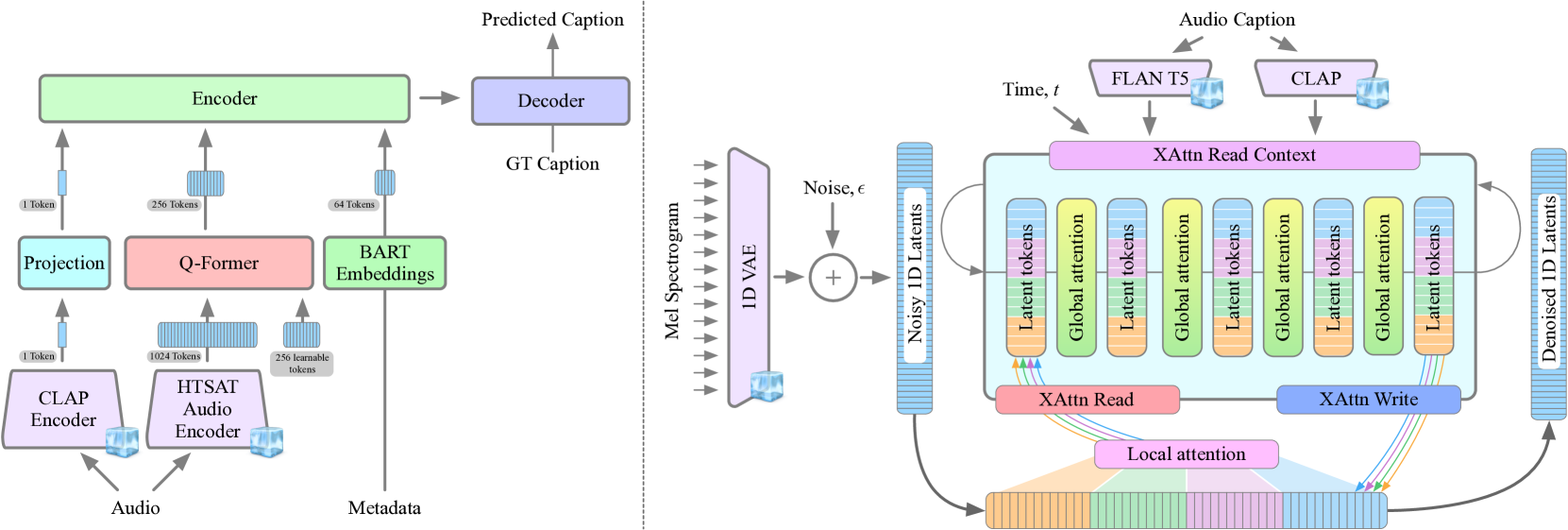
Taming Data and Transformers for Audio Generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, Sergey Tulyakov, Vicente Ordonez
Generating ambient sounds and effects is a challenging problem due to data scarcity and often insufficient caption quality, making it difficult to employ large-scale generative models for the task. In this work, we tackle the problem by introducing two new models. First, we propose AutoCap, a high-quality and efficient automatic audio captioning model. We show that by leveraging metadata available with the audio modality, we can substantially improve the quality of captions. AutoCap reaches CIDEr score of 83.2, marking a 3.2% improvement from the best available captioning model at four times faster inference speed. We then use AutoCap to caption clips from existing datasets, obtaining 761,000 audio clips with high-quality captions, forming the largest available audio-text dataset. Second, we propose GenAu, a scalable transformer-based audio generation architecture that we scale up to 1.25B parameters and train with our new dataset. When compared to state-of-the-art audio generators, GenAu obtains significant improvements of 15.7% in FAD score, 22.7% in IS, and 13.5% in CLAP score, indicating significantly improved quality of generated audio compared to previous works. This shows that the quality of data is often as important as its quantity. Besides, since AutoCap is fully automatic, new audio samples can be added to the training dataset, unlocking the training of even larger generative models for audio synthesis.
Read more6/28/2024