Towards Efficient Replay in Federated Incremental Learning
2403.05890
0
0

Abstract
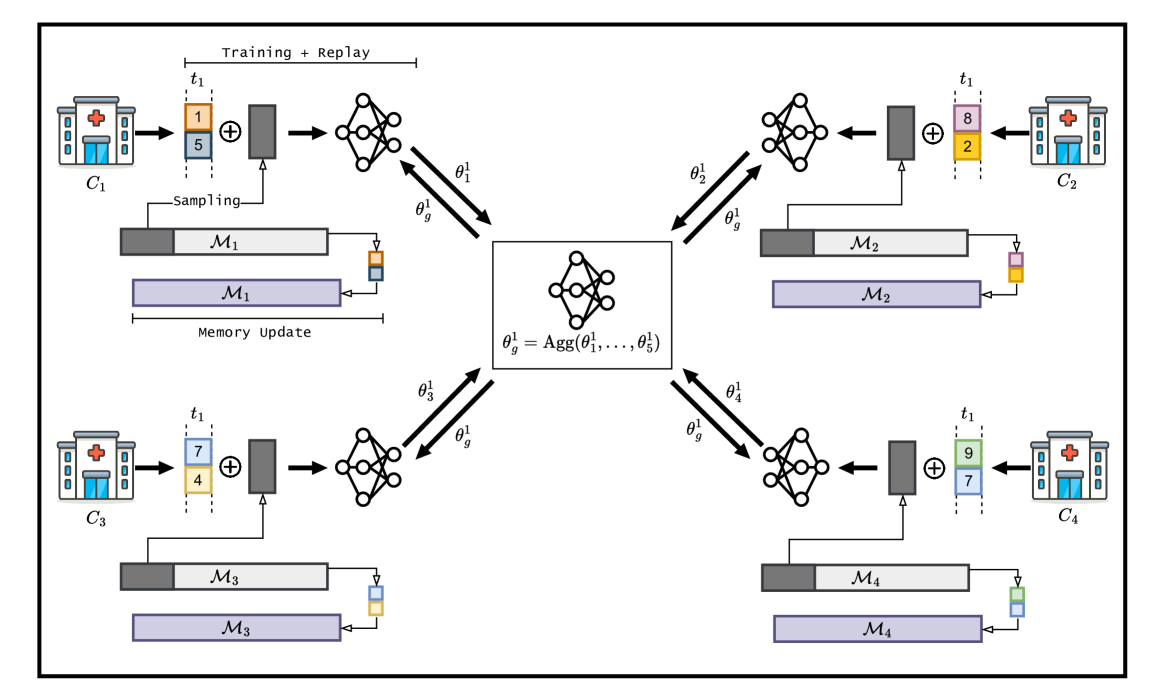
In Federated Learning (FL), the data in each client is typically assumed fixed or static. However, data often comes in an incremental manner in real-world applications, where the data domain may increase dynamically. In this work, we study catastrophic forgetting with data heterogeneity in Federated Incremental Learning (FIL) scenarios where edge clients may lack enough storage space to retain full data. We propose to employ a simple, generic framework for FIL named Re-Fed, which can coordinate each client to cache important samples for replay. More specifically, when a new task arrives, each client first caches selected previous samples based on their global and local importance. Then, the client trains the local model with both the cached samples and the samples from the new task. Theoretically, we analyze the ability of Re-Fed to discover important samples for replay thus alleviating the catastrophic forgetting problem. Moreover, we empirically show that Re-Fed achieves competitive performance compared to state-of-the-art methods.
Create account to get full access
Overview
• This paper presents a method for efficient replay in federated incremental learning, which aims to enable machine learning models to continuously learn and adapt without forgetting previous knowledge.
• The key ideas involve leveraging local client data and personalization to mitigate the challenge of limited memory for storing past data.
• The proposed approach is compared to related techniques like FedMES, Korea-SFL, MIMIC, Aggregation-Free, and Gossiping.
Plain English Explanation
In machine learning, models often struggle to continuously learn and adapt without forgetting what they've learned before. This is known as the "catastrophic forgetting" problem. The paper presents a new approach to address this issue in the context of federated learning, where a central model is trained by aggregating updates from many decentralized client devices.
The key idea is to leverage the local data and personalization capabilities of the client devices to more efficiently store and replay past information, instead of relying on a fixed memory buffer at the central server. By doing this, the model can continuously learn new tasks without completely forgetting previous knowledge.
The proposed method is compared to several related techniques that also aim to combat catastrophic forgetting in federated learning. The authors demonstrate that their approach can outperform these alternatives on a range of benchmarks, highlighting its effectiveness in enabling efficient and continual learning.
Technical Explanation
The paper introduces a novel approach called Efficient Replay in Federated Incremental Learning (ER-FIL), which builds on the concept of federated incremental learning. In this setting, a central model is trained by aggregating updates from client devices, each of which has a local dataset and model.
The key innovation of ER-FIL is its strategy for managing the "replay buffer" - a small subset of past data used to prevent forgetting. Instead of storing this buffer centrally, ER-FIL distributes it across the client devices, allowing them to personalize their models and efficiently replay relevant past information.
Specifically, ER-FIL uses a combination of techniques:
- Personalized Replay Buffers: Each client device maintains its own small replay buffer, tailored to its local data distribution and learning trajectory.
- Knowledge Distillation: When a client receives a new task, it uses knowledge distillation to transfer knowledge from its personalized model to the central model, helping to preserve past learning.
- Selective Replay: Clients selectively replay a subset of their buffer based on the relevance of the data to the current task, improving efficiency.
The paper evaluates ER-FIL against several related methods, including FedMES, Korea-SFL, MIMIC, Aggregation-Free, and Gossiping, on a range of continual learning benchmarks. The results demonstrate the effectiveness of ER-FIL in achieving high performance while maintaining low memory requirements.
Critical Analysis
The paper presents a promising approach to addressing the challenge of catastrophic forgetting in federated incremental learning. The authors' focus on leveraging local client data and personalization is a thoughtful strategy, as it aligns with the decentralized nature of federated learning.
One potential limitation is the reliance on knowledge distillation, which can be computationally expensive and may require careful hyperparameter tuning. Additionally, the paper does not explore the impact of client heterogeneity and dropout, which are common challenges in federated learning.
Further research could investigate the scalability of ER-FIL to larger and more diverse datasets, as well as its robustness to client drift and other federated learning challenges. Exploring potential synergies with techniques like Aggregation-Free and Gossiping could also be a fruitful avenue for future research.
Conclusion
This paper presents an innovative approach called Efficient Replay in Federated Incremental Learning (ER-FIL) that addresses the challenge of catastrophic forgetting in federated learning. By leveraging personalized replay buffers and selective knowledge distillation at the client level, ER-FIL demonstrates strong performance on continual learning benchmarks while maintaining low memory requirements.
The proposed method offers a promising direction for enabling efficient and continual learning in federated settings, where the decentralized nature of the problem requires novel solutions. Further research on scaling, robustness, and potential synergies with other federated learning techniques could help unlock the full potential of ER-FIL and similar approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Rehearsal-free Federated Domain-incremental Learning
Rui Sun, Haoran Duan, Jiahua Dong, Varun Ojha, Tejal Shah, Rajiv Ranjan
0
0
We introduce a rehearsal-free federated domain incremental learning framework, RefFiL, based on a global prompt-sharing paradigm to alleviate catastrophic forgetting challenges in federated domain-incremental learning, where unseen domains are continually learned. Typical methods for mitigating forgetting, such as the use of additional datasets and the retention of private data from earlier tasks, are not viable in federated learning (FL) due to devices' limited resources. Our method, RefFiL, addresses this by learning domain-invariant knowledge and incorporating various domain-specific prompts from the domains represented by different FL participants. A key feature of RefFiL is the generation of local fine-grained prompts by our domain adaptive prompt generator, which effectively learns from local domain knowledge while maintaining distinctive boundaries on a global scale. We also introduce a domain-specific prompt contrastive learning loss that differentiates between locally generated prompts and those from other domains, enhancing RefFiL's precision and effectiveness. Compared to existing methods, RefFiL significantly alleviates catastrophic forgetting without requiring extra memory space, making it ideal for privacy-sensitive and resource-constrained devices.
5/24/2024

Reducing Bias in Federated Class-Incremental Learning with Hierarchical Generative Prototypes
Riccardo Salami, Pietro Buzzega, Matteo Mosconi, Mattia Verasani, Simone Calderara
0
0
Federated Learning (FL) aims at unburdening the training of deep models by distributing computation across multiple devices (clients) while safeguarding data privacy. On top of that, Federated Continual Learning (FCL) also accounts for data distribution evolving over time, mirroring the dynamic nature of real-world environments. In this work, we shed light on the Incremental and Federated biases that naturally emerge in FCL. While the former is a known problem in Continual Learning, stemming from the prioritization of recently introduced classes, the latter (i.e., the bias towards local distributions) remains relatively unexplored. Our proposal constrains both biases in the last layer by efficiently fine-tuning a pre-trained backbone using learnable prompts, resulting in clients that produce less biased representations and more biased classifiers. Therefore, instead of solely relying on parameter aggregation, we also leverage generative prototypes to effectively balance the predictions of the global model. Our method improves on the current State Of The Art, providing an average increase of +7.9% in accuracy.
6/5/2024

FedMeS: Personalized Federated Continual Learning Leveraging Local Memory
Jin Xie, Chenqing Zhu, Songze Li
0
0
We focus on the problem of Personalized Federated Continual Learning (PFCL): a group of distributed clients, each with a sequence of local tasks on arbitrary data distributions, collaborate through a central server to train a personalized model at each client, with the model expected to achieve good performance on all local tasks. We propose a novel PFCL framework called Federated Memory Strengthening FedMeS to address the challenges of client drift and catastrophic forgetting. In FedMeS, each client stores samples from previous tasks using a small amount of local memory, and leverages this information to both 1) calibrate gradient updates in training process; and 2) perform KNN-based Gaussian inference to facilitate personalization. FedMeS is designed to be task-oblivious, such that the same inference process is applied to samples from all tasks to achieve good performance. FedMeS is analyzed theoretically and evaluated experimentally. It is shown to outperform all baselines in average accuracy and forgetting rate, over various combinations of datasets, task distributions, and client numbers.
4/22/2024
Federated Continual Learning Goes Online: Leveraging Uncertainty for Modality-Agnostic Class-Incremental Learning
Giuseppe Serra, Florian Buettner
0
0
Given the ability to model more realistic and dynamic problems, Federated Continual Learning (FCL) has been increasingly investigated recently. A well-known problem encountered in this setting is the so-called catastrophic forgetting, for which the learning model is inclined to focus on more recent tasks while forgetting the previously learned knowledge. The majority of the current approaches in FCL propose generative-based solutions to solve said problem. However, this setting requires multiple training epochs over the data, implying an offline setting where datasets are stored locally and remain unchanged over time. Furthermore, the proposed solutions are tailored for vision tasks solely. To overcome these limitations, we propose a new modality-agnostic approach to deal with the online scenario where new data arrive in streams of mini-batches that can only be processed once. To solve catastrophic forgetting, we propose an uncertainty-aware memory-based approach. In particular, we suggest using an estimator based on the Bregman Information (BI) to compute the model's variance at the sample level. Through measures of predictive uncertainty, we retrieve samples with specific characteristics, and - by retraining the model on such samples - we demonstrate the potential of this approach to reduce the forgetting effect in realistic settings.
5/30/2024