Towards Explainable Test Case Prioritisation with Learning-to-Rank Models

0
📊
Sign in to get full access
Overview
- Test case prioritization (TCP) is a crucial task in regression testing to ensure software quality as it evolves.
- Machine learning, particularly learning-to-rank (LTR) algorithms, provide an effective way to order and prioritize test cases.
- However, the use of LTR algorithms poses a challenge in terms of explainability, both at the global model level and for specific results.
- This paper explores scenarios that require different types of explanations and how the unique characteristics of TCP (e.g., multiple builds over time, test case and test suite variations) can influence those explanations.
- The paper includes a preliminary experiment analyzing the similarity of explanations, showing they can vary depending on both test case-specific predictions and relative rankings.
Plain English Explanation
As software is updated and improved over time, it's important to thoroughly test it to maintain quality. Test case prioritization (TCP) is a key part of this process, where the most important test cases are run first.
Machine learning, particularly learning-to-rank (LTR) algorithms, have become a common way to prioritize test cases effectively. These algorithms can order and prioritize the test cases based on their importance.
However, a challenge with using LTR algorithms is that they can be difficult to understand, both in terms of how the overall model works and why specific test cases are prioritized. This explainability issue is important because stakeholders often want to understand the reasoning behind the prioritization.
This paper explores different scenarios where explanations might be needed, and how the unique aspects of TCP (like changes over multiple software builds) could impact the type of explanation required. It also includes an early experiment looking at how the explanations can vary based on the specific test case predictions and their relative rankings.
Technical Explanation
The paper examines the challenge of providing explanations for the use of learning-to-rank (LTR) algorithms in the context of test case prioritization (TCP). TCP is a critical task in regression testing to ensure software quality as it evolves over multiple builds.
LTR algorithms offer an effective way to order and prioritize test cases, but their use poses a challenge in terms of explainability. The paper explores different scenarios that may require varying types of explanations, both at the global model level and for specific test case prioritization results.
The authors consider how the unique characteristics of TCP, such as the presence of multiple software builds over time and changes to test cases and test suites, could influence the type of explanations needed. They include a preliminary experiment that analyzes the similarity of explanations, demonstrating that the explanations can differ depending on both the specific test case predictions and their relative rankings.
Critical Analysis
The paper raises important points about the need for explainable machine learning models, particularly in the context of test case prioritization. As the authors note, stakeholders often want to understand the reasoning behind the prioritization of test cases, which can be difficult to provide with black-box LTR algorithms.
The exploration of different scenarios that may require varying types of explanations is a valuable contribution. By considering the unique aspects of TCP, such as changes over multiple software builds, the authors highlight the importance of tailoring explanations to the specific use case.
The preliminary experiment on the similarity of explanations is an interesting first step, but more research would be needed to fully understand the factors that influence the variability of explanations. Additional studies could explore the impact of different LTR algorithms, feature sets, and evaluation metrics on the explainability of TCP results.
One potential limitation of the research is the lack of input from end-users or stakeholders on their specific needs and preferences for explanations. Incorporating user feedback could help refine the understanding of what types of explanations are most useful and meaningful in the context of TCP.
Overall, the paper highlights an important challenge in the application of machine learning to software engineering tasks and provides a thoughtful starting point for further research in this area.
Conclusion
This paper examines the challenge of providing explanations for the use of learning-to-rank (LTR) algorithms in the context of test case prioritization (TCP), a critical task in regression testing. The authors explore different scenarios that may require varying types of explanations, both at the global model level and for specific test case prioritization results.
By considering the unique characteristics of TCP, such as changes over multiple software builds and variations in test cases and test suites, the paper underscores the importance of tailoring explanations to the specific use case. The preliminary experiment on the similarity of explanations demonstrates that the explanations can differ depending on both the test case-specific predictions and their relative rankings.
The research highlights the need for more explainable machine learning models, particularly in software engineering applications where stakeholders often require transparency in decision-making processes. Further studies could explore the impact of different algorithms, feature sets, and user preferences on the explainability of TCP results, ultimately contributing to the development of more accountable and trustworthy machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Towards Explainable Test Case Prioritisation with Learning-to-Rank Models
Aurora Ram'irez, Mario Berrios, Jos'e Ra'ul Romero, Robert Feldt
Test case prioritisation (TCP) is a critical task in regression testing to ensure quality as software evolves. Machine learning has become a common way to achieve it. In particular, learning-to-rank (LTR) algorithms provide an effective method of ordering and prioritising test cases. However, their use poses a challenge in terms of explainability, both globally at the model level and locally for particular results. Here, we present and discuss scenarios that require different explanations and how the particularities of TCP (multiple builds over time, test case and test suite variations, etc.) could influence them. We include a preliminary experiment to analyse the similarity of explanations, showing that they do not only vary depending on test case-specific predictions, but also on the relative ranks.
Read more5/24/2024
🤯
0
Fuzzy Inference System for Test Case Prioritization in Software Testing
Aron Karatayev, Anna Ogorodova, Pakizar Shamoi
In the realm of software development, testing is crucial for ensuring software quality and adherence to requirements. However, it can be time-consuming and resource-intensive, especially when dealing with large and complex software systems. Test case prioritization (TCP) is a vital strategy to enhance testing efficiency by identifying the most critical test cases for early execution. This paper introduces a novel fuzzy logic-based approach to automate TCP, using fuzzy linguistic variables and expert-derived fuzzy rules to establish a link between test case characteristics and their prioritization. Our methodology utilizes two fuzzy variables - failure rate and execution time - alongside two crisp parameters: Prerequisite Test Case and Recently Updated Flag. Our findings demonstrate the proposed system capacity to rank test cases effectively through experimental validation on a real-world software system. The results affirm the practical applicability of our approach in optimizing the TCP and reducing the resource intensity of software testing.
Read more4/26/2024
🤿
0
A3Rank: Augmentation Alignment Analysis for Prioritizing Overconfident Failing Samples for Deep Learning Models
Zhengyuan Wei, Haipeng Wang, Qilin Zhou, W. K. Chan
Sharpening deep learning models by training them with examples close to the decision boundary is a well-known best practice. Nonetheless, these models are still error-prone in producing predictions. In practice, the inference of the deep learning models in many application systems is guarded by a rejector, such as a confidence-based rejector, to filter out samples with insufficient prediction confidence. Such confidence-based rejectors cannot effectively guard against failing samples with high confidence. Existing test case prioritization techniques effectively distinguish confusing samples from confident samples to identify failing samples among the confusing ones, yet prioritizing the failing ones high among many confident ones is challenging. In this paper, we propose $A^3$Rank, a novel test case prioritization technique with augmentation alignment analysis, to address this problem. $A^3$Rank generates augmented versions of each test case and assesses the extent of the prediction result for the test case misaligned with these of the augmented versions and vice versa. Our experiment shows that $A^3$Rank can effectively rank failing samples escaping from the checking of confidence-based rejectors, which significantly outperforms the peer techniques by 163.63% in the detection ratio of top-ranked samples. We also provide a framework to construct a detector devoted to augmenting these rejectors to defend these failing samples, and our detector can achieve a significantly higher defense success rate.
Read more7/22/2024
0
Investigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
Zechun Niu, Jiaxin Mao, Qingyao Ai, Ji-Rong Wen
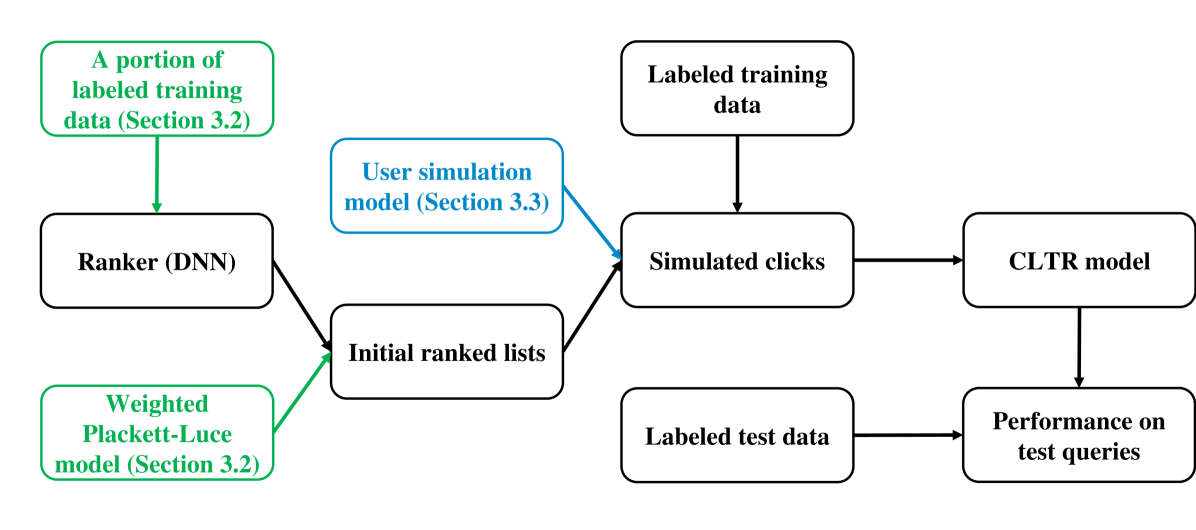
Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.
Read more4/8/2024