Towards Flexible Visual Relationship Segmentation

0

Sign in to get full access
Overview
- This paper proposes a method for flexible visual relationship segmentation, which aims to detect and segment relationships between objects in images.
- The method uses a transformer-based architecture to jointly model object detection, relationship prediction, and segmentation.
- The authors conduct experiments on benchmark datasets and show improvements over prior work.
Plain English Explanation
The paper is focused on a computer vision task called "visual relationship segmentation." This means automatically detecting and outlining the relationships between objects in an image. For example, if an image shows a person sitting on a chair, the goal would be to not only identify the person and chair, but also the specific relationship of "sitting on" between them.
The researchers developed a new approach using a type of neural network called a transformer. This allows the model to jointly consider the objects, their relationships, and how to segment the regions where those relationships occur. Prior methods tended to tackle these steps separately, but the transformer-based architecture can handle them together more effectively.
The key innovation is this flexible, integrated approach to visual relationship understanding. Rather than just classifying the relationships, the model can segment the specific image regions where those relationships are happening. This provides richer, more detailed information about the scene.
The paper demonstrates that this method outperforms previous approaches on benchmark datasets. It's an important step forward in building AI systems that can truly understand the complex web of relationships between objects in visual scenes.
Technical Explanation
The paper proposes a Flexible Visual Relationship Segmentation (FVRS) model that uses a transformer-based architecture to jointly handle object detection, relationship prediction, and segmentation.
The core components are:
- An object detection module to identify the individual objects in the image
- A relationship prediction module to classify the relationships between the detected objects
- A segmentation module to outline the specific regions where those relationships occur
These modules are integrated into a single end-to-end model using a transformer-based backbone. This allows the model to consider the full context and jointly optimize the different subtasks, rather than treating them independently.
The authors conduct experiments on the VRD, Visual Genome, and HICO-DET datasets. They show that their FVRS model outperforms prior work on various metrics, including relationship prediction accuracy and segmentation quality.
Critical Analysis
The paper makes a strong case for the benefits of the flexible, integrated approach to visual relationship understanding. By jointly modeling object detection, relationship prediction, and segmentation, the FVRS model is able to capture more nuanced and contextual information about the scenes.
However, the paper does not deeply explore the limitations or potential issues with this method. For example, it's unclear how the model would scale to more complex scenes with a larger number of objects and relationships. There may also be tradeoffs in terms of computational efficiency or training complexity that are not addressed.
Additionally, the paper does not provide much insight into the types of relationships the model is best at detecting or segmenting. It would be helpful to understand if there are certain relationship categories or visual scenarios that pose particular challenges.
Overall, while the technical contributions are sound, a more critical and nuanced discussion of the method's strengths, weaknesses, and areas for future research would strengthen the paper.
Conclusion
This paper presents a novel approach to visual relationship segmentation that uses a transformer-based architecture to jointly handle object detection, relationship prediction, and segmentation. The authors demonstrate that this flexible, integrated method outperforms prior work on benchmark datasets.
The key innovation is the ability to not only classify the relationships between objects, but also segment the specific image regions where those relationships occur. This provides a richer, more detailed understanding of the visual scene.
While the technical approach is well-executed, the paper could benefit from a more critical analysis of the method's limitations and areas for future research. Nonetheless, this work represents an important step forward in developing AI systems that can truly comprehend the complex web of relationships between objects in the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Flexible Visual Relationship Segmentation
Fangrui Zhu, Jianwei Yang, Huaizu Jiang
Visual relationship understanding has been studied separately in human-object interaction(HOI) detection, scene graph generation(SGG), and referring relationships(RR) tasks. Given the complexity and interconnectedness of these tasks, it is crucial to have a flexible framework that can effectively address these tasks in a cohesive manner. In this work, we propose FleVRS, a single model that seamlessly integrates the above three aspects in standard and promptable visual relationship segmentation, and further possesses the capability for open-vocabulary segmentation to adapt to novel scenarios. FleVRS leverages the synergy between text and image modalities, to ground various types of relationships from images and use textual features from vision-language models to visual conceptual understanding. Empirical validation across various datasets demonstrates that our framework outperforms existing models in standard, promptable, and open-vocabulary tasks, e.g., +1.9 $mAP$ on HICO-DET, +11.4 $Acc$ on VRD, +4.7 $mAP$ on unseen HICO-DET. Our FleVRS represents a significant step towards a more intuitive, comprehensive, and scalable understanding of visual relationships.
Read more8/16/2024

0
Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection
Tim Salzmann, Markus Ryll, Alex Bewley, Matthias Minderer
Visual relationship detection aims to identify objects and their relationships in images. Prior methods approach this task by adding separate relationship modules or decoders to existing object detection architectures. This separation increases complexity and hinders end-to-end training, which limits performance. We propose a simple and highly efficient decoder-free architecture for open-vocabulary visual relationship detection. Our model consists of a Transformer-based image encoder that represents objects as tokens and models their relationships implicitly. To extract relationship information, we introduce an attention mechanism that selects object pairs likely to form a relationship. We provide a single-stage recipe to train this model on a mixture of object and relationship detection data. Our approach achieves state-of-the-art relationship detection performance on Visual Genome and on the large-vocabulary GQA benchmark at real-time inference speeds. We provide ablations, real-world qualitative examples, and analyses of zero-shot performance.
Read more7/22/2024
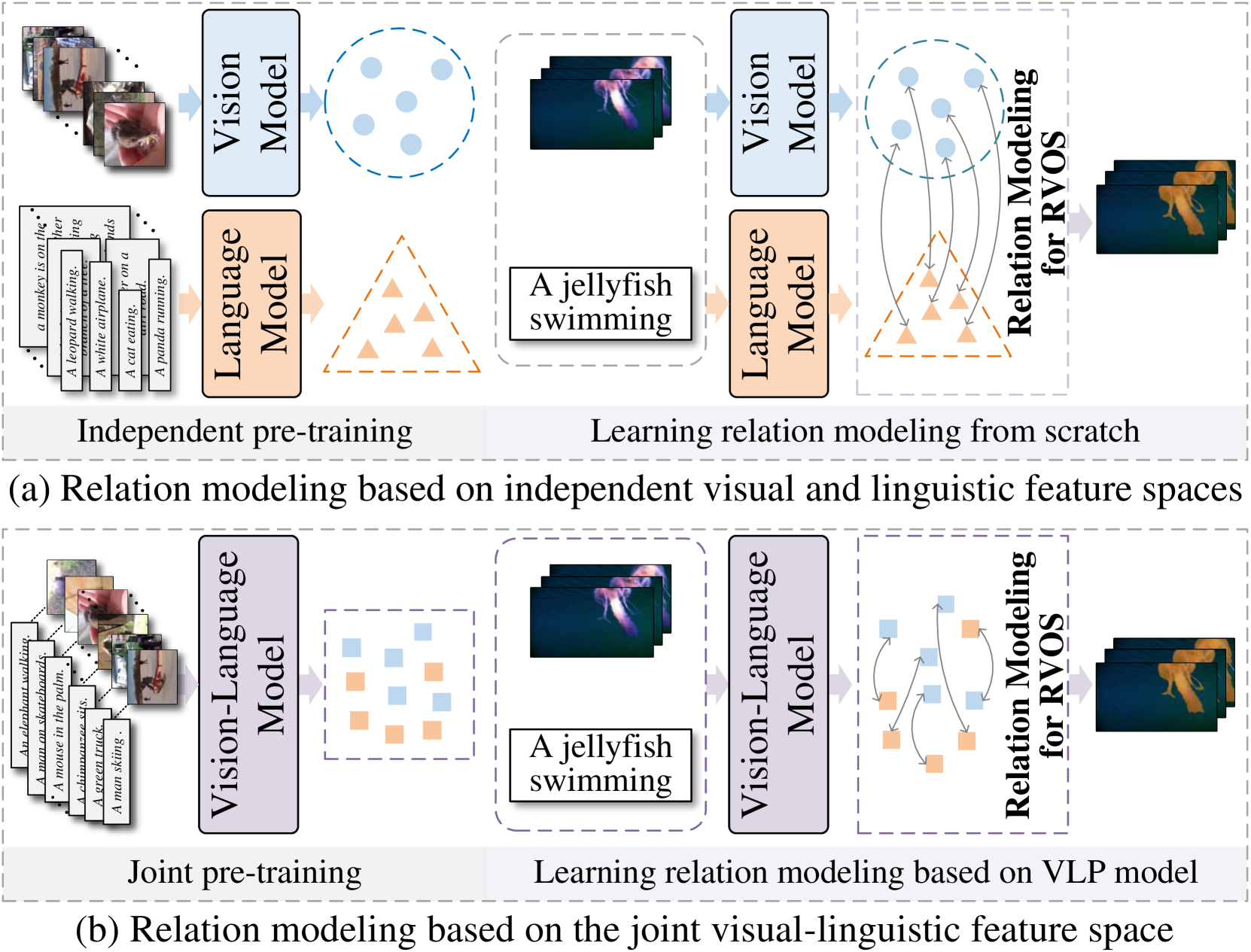
0
Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models
Zikun Zhou, Wentao Xiong, Li Zhou, Xin Li, Zhenyu He, Yaowei Wang
The crux of Referring Video Object Segmentation (RVOS) lies in modeling dense text-video relations to associate abstract linguistic concepts with dynamic visual contents at pixel-level. Current RVOS methods typically use vision and language models pre-trained independently as backbones. As images and texts are mapped to uncoupled feature spaces, they face the arduous task of learning Vision-Language~(VL) relation modeling from scratch. Witnessing the success of Vision-Language Pre-trained (VLP) models, we propose to learn relation modeling for RVOS based on their aligned VL feature space. Nevertheless, transferring VLP models to RVOS is a deceptively challenging task due to the substantial gap between the pre-training task (image/region-level prediction) and the RVOS task (pixel-level prediction in videos). In this work, we introduce a framework named VLP-RVOS to address this transfer challenge. We first propose a temporal-aware prompt-tuning method, which not only adapts pre-trained representations for pixel-level prediction but also empowers the vision encoder to model temporal clues. We further propose to perform multi-stage VL relation modeling while and after feature extraction for comprehensive VL understanding. Besides, we customize a cube-frame attention mechanism for spatial-temporal reasoning. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms and exhibits strong generalization abilities.
Read more5/20/2024

0
ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding
Minghang Zheng, Jiahua Zhang, Qingchao Chen, Yuxin Peng, Yang Liu
Visual grounding aims to localize the object referred to in an image based on a natural language query. Although progress has been made recently, accurately localizing target objects within multiple-instance distractions (multiple objects of the same category as the target) remains a significant challenge. Existing methods demonstrate a significant performance drop when there are multiple distractions in an image, indicating an insufficient understanding of the fine-grained semantics and spatial relationships between objects. In this paper, we propose a novel approach, the Relation and Semantic-sensitive Visual Grounding (ResVG) model, to address this issue. Firstly, we enhance the model's understanding of fine-grained semantics by injecting semantic prior information derived from text queries into the model. This is achieved by leveraging text-to-image generation models to produce images representing the semantic attributes of target objects described in queries. Secondly, we tackle the lack of training samples with multiple distractions by introducing a relation-sensitive data augmentation method. This method generates additional training data by synthesizing images containing multiple objects of the same category and pseudo queries based on their spatial relationships. The proposed ReSVG model significantly improves the model's ability to comprehend both object semantics and spatial relations, leading to enhanced performance in visual grounding tasks, particularly in scenarios with multiple-instance distractions. We conduct extensive experiments to validate the effectiveness of our methods on five datasets. Code is available at https://github.com/minghangz/ResVG.
Read more8/30/2024