Towards Interactively Improving ML Data Preparation Code via Shadow Pipelines

0
📊
Sign in to get full access
Overview
- Data scientists iteratively develop machine learning (ML) pipelines, repeatedly screening for issues, debugging, and revising the code.
- This manual process is tedious and error-prone.
- The proposed approach aims to support data scientists by automatically generating interactive suggestions for pipeline improvements.
- The key idea is to use "shadow pipelines" - hidden variants of the original pipeline that can auto-detect issues, try out modifications, and suggest improvements to the user.
- The researchers plan to apply optimizations based on incremental view maintenance to ensure low-latency computation and maintenance of the shadow pipelines.
- Preliminary experiments demonstrate the feasibility of this approach and the potential benefits of the proposed optimizations.
Plain English Explanation
Building effective machine learning (ML) pipelines is a crucial task for data scientists. This involves repeatedly testing the pipeline, fixing any problems that arise, and improving the code. However, this manual process can be tedious and error-prone.
To address this, the researchers propose a system that can automatically suggest ways to improve the ML pipeline. The key idea is to create "shadow pipelines" - hidden variants of the original pipeline that can test out different modifications and identify potential improvements. For example, a shadow pipeline might try adding a new data preprocessing step or adjusting a model hyperparameter, and then recommend these changes to the data scientist.
The researchers plan to use optimizations based on incremental view maintenance to ensure that these shadow pipelines can be computed and updated quickly, without slowing down the main development process.
In early experiments, the researchers have shown that this approach is feasible and could provide significant benefits to data scientists as they build and refine their ML pipelines.
Technical Explanation
The paper proposes a novel approach to support data scientists in the iterative development of machine learning (ML) pipelines. Typically, data scientists manually screen their pipelines for potential issues, debug problems, and revise the code accordingly. However, this process can be tedious and error-prone.
To address this, the researchers envision a system that can automatically generate interactive suggestions for pipeline improvements. The key technical component is the use of "shadow pipelines" - hidden variants of the original pipeline that can modify and test the pipeline in various ways. For example, a shadow pipeline might try adding a new data preprocessing step or adjusting a model hyperparameter, and then recommend these changes to the user.
To ensure efficient computation and maintenance of the shadow pipelines, the researchers plan to apply optimizations based on incremental view maintenance. This approach allows the system to quickly update the shadow pipelines as changes are made to the original pipeline, without the need for full recomputation.
The researchers conduct preliminary experiments to demonstrate the feasibility of their envisioned approach and the potential benefits of the proposed optimizations. These results suggest that this system could significantly streamline the iterative development of ML pipelines, reducing the manual effort required by data scientists.
Critical Analysis
The proposed approach presents a promising solution to the challenge of iterative ML pipeline development. By automatically generating interactive suggestions for improvements, the system could greatly reduce the manual effort and potential for errors in this process.
However, the paper does not address several important considerations. For example, it is unclear how the system would handle complex, interdependent changes to the pipeline, or how it would deal with issues that require human judgment and creativity to resolve. Additionally, the paper does not discuss potential privacy or security concerns that may arise from the use of "shadow pipelines" to test modifications to sensitive data and models.
Further research is needed to explore the scalability and robustness of this approach, as well as its applicability to a wider range of ML pipeline development scenarios. Incorporating user studies and feedback from data scientists would also be valuable to ensure the system's suggestions are truly helpful and actionable.
Despite these limitations, the core idea of leveraging incremental view maintenance to efficiently maintain and test pipeline variations is a compelling approach that could significantly benefit the ML development process. As the researchers continue to refine and expand their work, it will be interesting to see how this system evolves and the impact it can have on the field.
Conclusion
This paper presents a novel approach to support data scientists in the iterative development of machine learning pipelines. By automatically generating interactive suggestions for pipeline improvements through the use of "shadow pipelines," the proposed system could greatly streamline this typically tedious and error-prone process.
The key technical innovation is the application of incremental view maintenance optimizations to ensure efficient computation and maintenance of the shadow pipelines. Preliminary experiments demonstrate the feasibility and potential benefits of this approach.
While the paper raises some important considerations that require further research, the core idea of leveraging automated pipeline variations to suggest improvements is a promising step towards more efficient and effective machine learning development. As the field continues to evolve, solutions like this that can assist data scientists and reduce manual effort will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Towards Interactively Improving ML Data Preparation Code via Shadow Pipelines
Stefan Grafberger, Paul Groth, Sebastian Schelter
Data scientists develop ML pipelines in an iterative manner: they repeatedly screen a pipeline for potential issues, debug it, and then revise and improve its code according to their findings. However, this manual process is tedious and error-prone. Therefore, we propose to support data scientists during this development cycle with automatically derived interactive suggestions for pipeline improvements. We discuss our vision to generate these suggestions with so-called shadow pipelines, hidden variants of the original pipeline that modify it to auto-detect potential issues, try out modifications for improvements, and suggest and explain these modifications to the user. We envision to apply incremental view maintenance-based optimisations to ensure low-latency computation and maintenance of the shadow pipelines. We conduct preliminary experiments to showcase the feasibility of our envisioned approach and the potential benefits of our proposed optimisations.
Read more5/1/2024
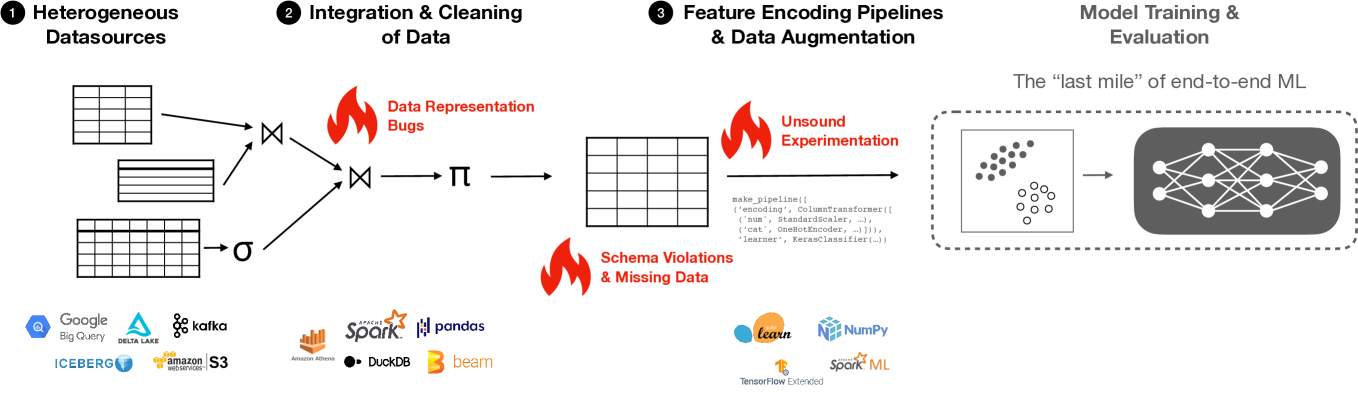
0
Instrumentation and Analysis of Native ML Pipelines via Logical Query Plans
Stefan Grafberger
Machine Learning (ML) is increasingly used to automate impactful decisions, which leads to concerns regarding their correctness, reliability, and fairness. We envision highly-automated software platforms to assist data scientists with developing, validating, monitoring, and analysing their ML pipelines. In contrast to existing work, our key idea is to extract logical query plans from ML pipeline code relying on popular libraries. Based on these plans, we automatically infer pipeline semantics and instrument and rewrite the ML pipelines to enable diverse use cases without requiring data scientists to manually annotate or rewrite their code. First, we developed such an abstract ML pipeline representation together with machinery to extract it from Python code. Next, we used this representation to efficiently instrument static ML pipelines and apply provenance tracking, which enables lightweight screening for common data preparation issues. Finally, we built machinery to automatically rewrite ML pipelines to perform more advanced what-if analyses and proposed using multi-query optimisation for the resulting workloads. In future work, we aim to interactively assist data scientists as they work on their ML pipelines.
Read more7/11/2024

0
Statistical Test for Data Analysis Pipeline by Selective Inference
Tomohiro Shiraishi, Tatsuya Matsukawa, Shuichi Nishino, Ichiro Takeuchi
A data analysis pipeline is a structured sequence of processing steps that transforms raw data into meaningful insights by effectively integrating various analysis algorithms. In this paper, we propose a novel statistical test designed to assess the statistical significance of data analysis pipelines. Our approach allows for the systematic development of valid statistical tests applicable to any data analysis pipeline configuration composed of a set of data analysis components. We have developed this framework by adapting selective inference, which has gained recent attention as a new statistical inference technique for data-driven hypotheses. The proposed statistical test is theoretically designed to control the type I error at the desired significance level in finite samples. As examples, we consider a class of pipelines composed of three missing value imputation algorithms, three outlier detection algorithms, and three feature selection algorithms. We confirm the validity of our statistical test through experiments with both synthetic and real data for this class of data analysis pipelines. Additionally, we present an implementation framework that facilitates testing across any configuration of data analysis pipelines in this class without extra implementation costs.
Read more6/28/2024

0
Enhancing Psychotherapy Counseling: A Data Augmentation Pipeline Leveraging Large Language Models for Counseling Conversations
Jun-Woo Kim, Ji-Eun Han, Jun-Seok Koh, Hyeon-Tae Seo, Du-Seong Chang
We introduce a pipeline that leverages Large Language Models (LLMs) to transform single-turn psychotherapy counseling sessions into multi-turn interactions. While AI-supported online counseling services for individuals with mental disorders exist, they are often constrained by the limited availability of multi-turn training datasets and frequently fail to fully utilize therapists' expertise. Our proposed pipeline effectively addresses these limitations. The pipeline comprises two main steps: 1) Information Extraction and 2) Multi-turn Counseling Generation. Each step is meticulously designed to extract and generate comprehensive multi-turn counseling conversations from the available datasets. Experimental results from both zero-shot and few-shot generation scenarios demonstrate that our approach significantly enhances the ability of LLMs to produce higher quality multi-turn dialogues in the context of mental health counseling. Our pipeline and dataset are publicly available https://github.com/jwkim-chat/A-Data-Augmentation-Pipeline-Leveraging-Large-Language-Models-for-Counseling-Conversations.
Read more6/14/2024