Statistical Test for Data Analysis Pipeline by Selective Inference

0

Sign in to get full access
Overview
- This research paper presents a statistical test for evaluating the validity of data analysis pipelines, which are commonly used in machine learning and data science workflows.
- The key idea is to use selective inference, a technique that accounts for the selection process involved in data analysis, to provide more accurate statistical tests and p-values.
- The proposed method aims to address challenges in pipeline tools for data engineering and improve the reliability of machine learning-assisted inference.
Plain English Explanation
Data analysis pipelines are a common way to process and analyze data in machine learning and data science. These pipelines often involve multiple steps, such as data cleaning, feature engineering, and model building. The problem is that the choices made during these steps can bias the final results, making it difficult to accurately assess the statistical significance of the findings.
The researchers in this paper propose a new statistical test that addresses this issue. Their approach, called "selective inference," takes into account the fact that the data analysis pipeline itself is a kind of "selection process." By modeling this selection process, the researchers can provide more accurate p-values and better assess the validity of the pipeline's results.
Imagine you're trying to figure out if a new drug can improve patient outcomes. You might have a data analysis pipeline that involves cleaning the data, selecting the most relevant features, and building a predictive model. The traditional approach would be to simply look at the p-value of the final model to see if the results are statistically significant.
However, the choices you made during the data cleaning and feature selection steps can influence the final p-value, making it harder to know if the drug is truly effective. The selective inference approach proposed in this paper helps account for those pipeline decisions, giving you a more reliable assessment of the drug's impact.
This is important because it can help researchers and data scientists make more informed decisions about the validity of their analyses, leading to more reliable findings and better-informed decisions in fields like medicine, differential privacy, and interactive machine learning.
Technical Explanation
The key innovation of this paper is the use of selective inference to address the challenge of properly assessing the statistical significance of results from a data analysis pipeline. Selective inference is a technique that models the selection process involved in data analysis, allowing for more accurate p-values and hypothesis testing.
The researchers start by formalizing the data analysis pipeline as a sequence of steps, each of which involves a selection process (e.g., choosing which features to include, deciding on the model architecture). They then develop a statistical framework that accounts for these selection steps, providing a way to compute valid p-values that reflect the true uncertainty in the final results.
The technical details involve deriving the appropriate conditioning and pivot quantities to use in the selective inference framework, as well as implementing efficient computational methods to make the approach scalable and practical for real-world data analysis pipelines.
The authors demonstrate the effectiveness of their approach through a series of experiments, including both simulated data and real-world applications in areas like active statistical inference. The results show that the selective inference-based tests outperform traditional approaches in terms of type I error control and statistical power, leading to more reliable conclusions about the significance of the findings.
Critical Analysis
The main strength of this research is that it provides a principled statistical framework for addressing a fundamental challenge in data analysis pipelines: accounting for the selection bias introduced by the various decisions and choices made during the analysis process.
That said, the paper does acknowledge some limitations and areas for future work. For example, the current approach assumes that the pipeline steps are known and can be modeled explicitly. In practice, the true selection process may be more complex or even unknown, which could limit the applicability of the selective inference framework.
Additionally, the computational complexity of the selective inference approach may be a practical concern, especially for large-scale or highly iterative data analysis pipelines. The authors mention that they have developed efficient algorithms, but further work may be needed to make the approach truly scalable and accessible to a wide range of practitioners.
Another potential issue is the reliance on certain assumptions, such as the availability of complete information about the pipeline steps and the validity of the underlying statistical models. Violations of these assumptions could undermine the reliability of the selective inference-based tests, and more research may be needed to understand the robustness of the approach in the face of real-world data challenges.
Overall, this research represents an important step forward in addressing a critical problem in data analysis pipelines. However, as with any research, there are areas for further exploration and refinement. Continued work in this direction, along with practical applications and case studies, will be crucial for advancing the state of the art in statistical testing for complex data analysis workflows.
Conclusion
This paper presents a novel statistical test for evaluating the validity of data analysis pipelines, which are widely used in machine learning and data science. The key innovation is the use of selective inference, a technique that accounts for the selection process involved in data analysis, to provide more accurate p-values and hypothesis testing.
By modeling the various steps of the data analysis pipeline as a series of selection processes, the proposed approach can better capture the true uncertainty in the final results, leading to more reliable conclusions about the significance of the findings. This is a crucial step in improving the reliability of machine learning-assisted inference and addressing challenges in pipeline tools for data engineering.
The potential impact of this research is wide-ranging, as it can enhance the validity and trustworthiness of data-driven decision-making in fields like medicine, differential privacy, and interactive machine learning. While the proposed approach has some limitations and areas for further refinement, this work represents an important step forward in the ongoing effort to improve the statistical rigor of complex data analysis workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Statistical Test for Data Analysis Pipeline by Selective Inference
Tomohiro Shiraishi, Tatsuya Matsukawa, Shuichi Nishino, Ichiro Takeuchi
A data analysis pipeline is a structured sequence of processing steps that transforms raw data into meaningful insights by effectively integrating various analysis algorithms. In this paper, we propose a novel statistical test designed to assess the statistical significance of data analysis pipelines. Our approach allows for the systematic development of valid statistical tests applicable to any data analysis pipeline configuration composed of a set of data analysis components. We have developed this framework by adapting selective inference, which has gained recent attention as a new statistical inference technique for data-driven hypotheses. The proposed statistical test is theoretically designed to control the type I error at the desired significance level in finite samples. As examples, we consider a class of pipelines composed of three missing value imputation algorithms, three outlier detection algorithms, and three feature selection algorithms. We confirm the validity of our statistical test through experiments with both synthetic and real data for this class of data analysis pipelines. Additionally, we present an implementation framework that facilitates testing across any configuration of data analysis pipelines in this class without extra implementation costs.
Read more6/28/2024
🤯
0
Statistical Test on Diffusion Model-based Generated Images by Selective Inference
Teruyuki Katsuoka, Tomohiro Shiraishi, Daiki Miwa, Vo Nguyen Le Duy, Ichiro Takeuchi
AI technology for generating images, such as diffusion models, has advanced rapidly. However, there is no established framework for quantifying the reliability of AI-generated images, which hinders their use in critical decision-making tasks, such as medical image diagnosis. In this study, we propose a method to quantify the reliability of decision-making tasks that rely on images produced by diffusion models within a statistical testing framework. The core concept of our statistical test involves using a selective inference framework, in which the statistical test is conducted under the condition that the images are produced by a trained diffusion model. As a case study, we study a diffusion model-based anomaly detection task for medical images. With our approach, the statistical significance of medical image diagnostic outcomes can be quantified in terms of a p-value, enabling decision-making with a controlled error rate. We demonstrate the theoretical soundness and practical effectiveness of our statistical test through numerical experiments on both synthetic and brain image datasets.
Read more7/30/2024
📊
0
Towards Interactively Improving ML Data Preparation Code via Shadow Pipelines
Stefan Grafberger, Paul Groth, Sebastian Schelter
Data scientists develop ML pipelines in an iterative manner: they repeatedly screen a pipeline for potential issues, debug it, and then revise and improve its code according to their findings. However, this manual process is tedious and error-prone. Therefore, we propose to support data scientists during this development cycle with automatically derived interactive suggestions for pipeline improvements. We discuss our vision to generate these suggestions with so-called shadow pipelines, hidden variants of the original pipeline that modify it to auto-detect potential issues, try out modifications for improvements, and suggest and explain these modifications to the user. We envision to apply incremental view maintenance-based optimisations to ensure low-latency computation and maintenance of the shadow pipelines. We conduct preliminary experiments to showcase the feasibility of our envisioned approach and the potential benefits of our proposed optimisations.
Read more5/1/2024
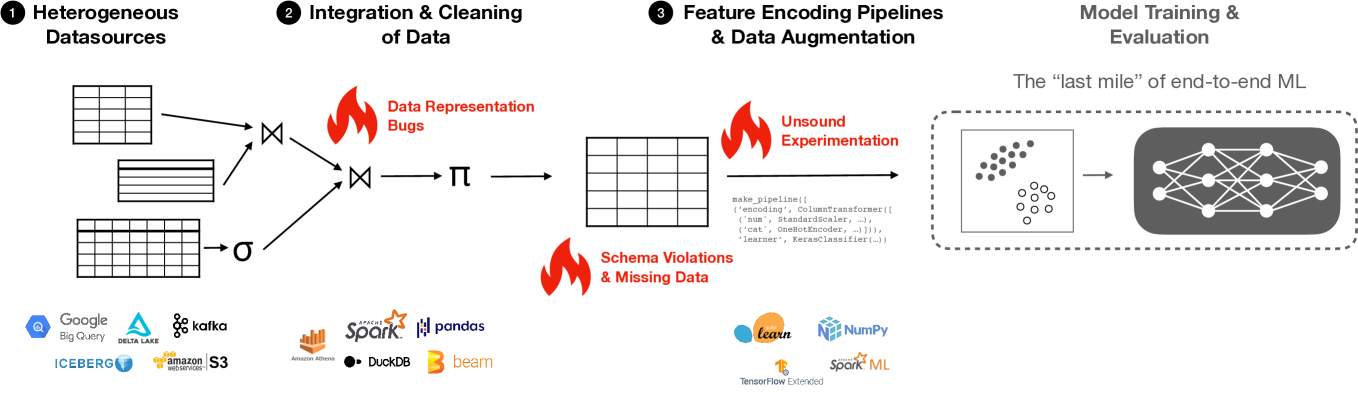
0
Instrumentation and Analysis of Native ML Pipelines via Logical Query Plans
Stefan Grafberger
Machine Learning (ML) is increasingly used to automate impactful decisions, which leads to concerns regarding their correctness, reliability, and fairness. We envision highly-automated software platforms to assist data scientists with developing, validating, monitoring, and analysing their ML pipelines. In contrast to existing work, our key idea is to extract logical query plans from ML pipeline code relying on popular libraries. Based on these plans, we automatically infer pipeline semantics and instrument and rewrite the ML pipelines to enable diverse use cases without requiring data scientists to manually annotate or rewrite their code. First, we developed such an abstract ML pipeline representation together with machinery to extract it from Python code. Next, we used this representation to efficiently instrument static ML pipelines and apply provenance tracking, which enables lightweight screening for common data preparation issues. Finally, we built machinery to automatically rewrite ML pipelines to perform more advanced what-if analyses and proposed using multi-query optimisation for the resulting workloads. In future work, we aim to interactively assist data scientists as they work on their ML pipelines.
Read more7/11/2024