Instrumentation and Analysis of Native ML Pipelines via Logical Query Plans

0
Sign in to get full access
Overview
- This paper presents a novel approach for instrumenting and analyzing native machine learning (ML) pipelines using logical query plans.
- The proposed method allows for introspection and optimization of ML pipelines by leveraging relational algebra concepts.
- The authors demonstrate the effectiveness of their approach on several real-world ML use cases, showcasing its ability to provide detailed insights and enable pipeline improvements.
Plain English Explanation
The paper discusses a new way to understand and optimize the inner workings of machine learning (ML) systems. ML pipelines are the series of steps involved in training and deploying an ML model, such as data preprocessing, model training, and model evaluation. Typically, these pipelines can be complex and difficult to analyze.
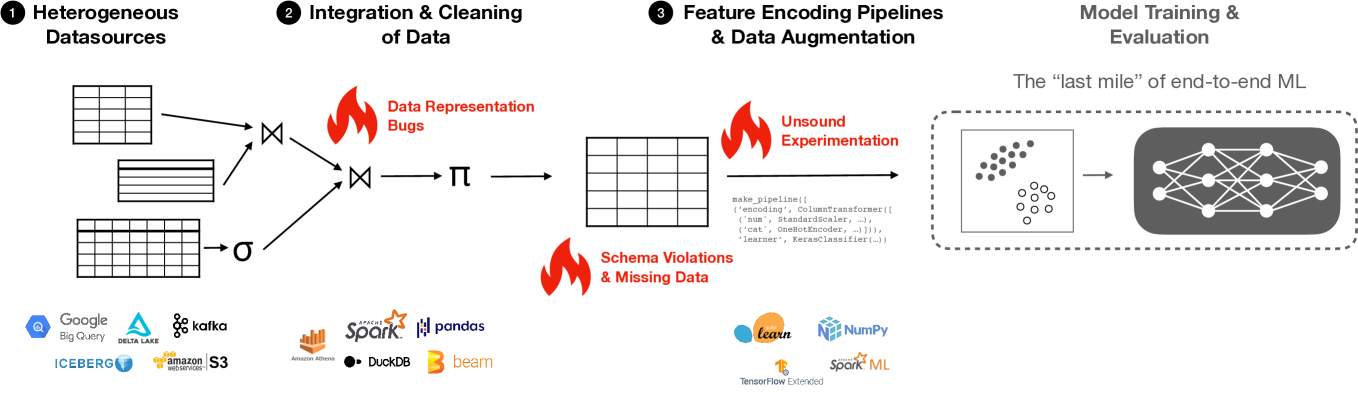
The researchers developed a technique that represents the ML pipeline as a logical query plan - a way of breaking down the pipeline into its fundamental relational algebra operations, similar to how a database query is executed. This allows them to instrument the pipeline and gather detailed information about each step, such as the data flowing through it and the computational resources it uses.
By analyzing this logical query plan representation, the researchers can identify performance bottlenecks, debug issues, and find opportunities to optimize the pipeline. For example, they may discover that a certain data transformation step is taking too long and suggest a more efficient alternative.
The paper demonstrates the effectiveness of this approach on several real-world ML use cases, showing how it can provide valuable insights and enable improvements to the ML pipeline. This could be particularly useful for large-scale ML systems where the pipelines are complex and difficult to understand.
Technical Explanation
The paper presents a novel approach for instrumenting and analyzing native ML pipelines using logical query plans. The key idea is to represent the ML pipeline as a set of relational algebra operations, which allows the researchers to leverage well-established concepts from database query optimization to gain insights into the pipeline's behavior.
The authors first define a formal abstraction for ML pipelines, where each step in the pipeline is modeled as a relational operator (e.g., filter, map, join). They then show how this representation can be used to construct a logical query plan for the entire pipeline, capturing the data transformations and computations performed at each stage.
Using this logical query plan, the researchers develop techniques for instrumenting the pipeline and collecting detailed performance and provenance data. This includes tracking the data flowing through each operator, monitoring resource utilization, and identifying performance bottlenecks. The authors demonstrate how this information can be used to optimize the pipeline, such as by rewriting the logical plan to improve efficiency or by recommending alternative implementations for specific operators.
The paper evaluates the proposed approach on several real-world ML use cases, including natural language processing, image classification, and recommendation systems. The results show that the logical query plan representation provides valuable insights that enable both fine-grained analysis and high-level optimization of the ML pipelines.
Critical Analysis
The paper presents a promising approach for improving the transparency and optimization of ML pipelines, but it also raises some potential concerns and areas for further research.
One key limitation is the reliance on a specific ML framework (in this case, PyTorch) to extract the necessary information for constructing the logical query plan. While the authors discuss the potential for extending the approach to other frameworks, the current implementation may not be easily applicable to ML systems built using different tools and libraries.
Additionally, the paper focuses on the instrumentation and analysis of the ML pipeline itself, but it does not delve deeply into the broader implications of this technique. For example, the authors do not discuss how the insights gained from the logical query plan representation could be used to improve the overall ML model development process or to enhance the interpretability of the final model.
Further research could explore ways to generalize the proposed approach to work across a wider range of ML frameworks and to integrate it more seamlessly into the end-to-end ML lifecycle. Investigating the potential privacy and security implications of the detailed pipeline instrumentation would also be a valuable area of study.
Conclusion
The paper presents a novel approach for instrumenting and analyzing native ML pipelines using logical query plans. By representing the ML pipeline as a set of relational algebra operations, the researchers are able to leverage established concepts from database query optimization to gain detailed insights into the pipeline's behavior and performance.
The authors demonstrate the effectiveness of their approach on several real-world ML use cases, showing how the logical query plan representation can enable fine-grained analysis, identification of performance bottlenecks, and optimization of the ML pipeline. This work has the potential to significantly improve the transparency and efficiency of large-scale ML systems, which are often complex and difficult to understand.
While the current implementation is limited to a specific ML framework, the underlying concepts could be extended to a wider range of tools and libraries. Further research is needed to explore the broader implications of this technique and to address potential concerns around privacy and security.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Instrumentation and Analysis of Native ML Pipelines via Logical Query Plans
Stefan Grafberger
Machine Learning (ML) is increasingly used to automate impactful decisions, which leads to concerns regarding their correctness, reliability, and fairness. We envision highly-automated software platforms to assist data scientists with developing, validating, monitoring, and analysing their ML pipelines. In contrast to existing work, our key idea is to extract logical query plans from ML pipeline code relying on popular libraries. Based on these plans, we automatically infer pipeline semantics and instrument and rewrite the ML pipelines to enable diverse use cases without requiring data scientists to manually annotate or rewrite their code. First, we developed such an abstract ML pipeline representation together with machinery to extract it from Python code. Next, we used this representation to efficiently instrument static ML pipelines and apply provenance tracking, which enables lightweight screening for common data preparation issues. Finally, we built machinery to automatically rewrite ML pipelines to perform more advanced what-if analyses and proposed using multi-query optimisation for the resulting workloads. In future work, we aim to interactively assist data scientists as they work on their ML pipelines.
Read more7/11/2024
📊
0
Towards Interactively Improving ML Data Preparation Code via Shadow Pipelines
Stefan Grafberger, Paul Groth, Sebastian Schelter
Data scientists develop ML pipelines in an iterative manner: they repeatedly screen a pipeline for potential issues, debug it, and then revise and improve its code according to their findings. However, this manual process is tedious and error-prone. Therefore, we propose to support data scientists during this development cycle with automatically derived interactive suggestions for pipeline improvements. We discuss our vision to generate these suggestions with so-called shadow pipelines, hidden variants of the original pipeline that modify it to auto-detect potential issues, try out modifications for improvements, and suggest and explain these modifications to the user. We envision to apply incremental view maintenance-based optimisations to ensure low-latency computation and maintenance of the shadow pipelines. We conduct preliminary experiments to showcase the feasibility of our envisioned approach and the potential benefits of our proposed optimisations.
Read more5/1/2024

0
Statistical Test for Data Analysis Pipeline by Selective Inference
Tomohiro Shiraishi, Tatsuya Matsukawa, Shuichi Nishino, Ichiro Takeuchi
A data analysis pipeline is a structured sequence of processing steps that transforms raw data into meaningful insights by effectively integrating various analysis algorithms. In this paper, we propose a novel statistical test designed to assess the statistical significance of data analysis pipelines. Our approach allows for the systematic development of valid statistical tests applicable to any data analysis pipeline configuration composed of a set of data analysis components. We have developed this framework by adapting selective inference, which has gained recent attention as a new statistical inference technique for data-driven hypotheses. The proposed statistical test is theoretically designed to control the type I error at the desired significance level in finite samples. As examples, we consider a class of pipelines composed of three missing value imputation algorithms, three outlier detection algorithms, and three feature selection algorithms. We confirm the validity of our statistical test through experiments with both synthetic and real data for this class of data analysis pipelines. Additionally, we present an implementation framework that facilitates testing across any configuration of data analysis pipelines in this class without extra implementation costs.
Read more6/28/2024

0
Generating Analytic Specifications for Data Visualization from Natural Language Queries using Large Language Models
Subham Sah, Rishab Mitra, Arpit Narechania, Alex Endert, John Stasko, Wenwen Dou
Recently, large language models (LLMs) have shown great promise in translating natural language (NL) queries into visualizations, but their black-box nature often limits explainability and debuggability. In response, we present a comprehensive text prompt that, given a tabular dataset and an NL query about the dataset, generates an analytic specification including (detected) data attributes, (inferred) analytic tasks, and (recommended) visualizations. This specification captures key aspects of the query translation process, affording both explainability and debuggability. For instance, it provides mappings from the detected entities to the corresponding phrases in the input query, as well as the specific visual design principles that determined the visualization recommendations. Moreover, unlike prior LLM-based approaches, our prompt supports conversational interaction and ambiguity detection capabilities. In this paper, we detail the iterative process of curating our prompt, present a preliminary performance evaluation using GPT-4, and discuss the strengths and limitations of LLMs at various stages of query translation. The prompt is open-source and integrated into NL4DV, a popular Python-based natural language toolkit for visualization, which can be accessed at https://nl4dv.github.io.
Read more8/28/2024