Towards Learning Contrast Kinetics with Multi-Condition Latent Diffusion Models
2403.13890
0
0

Abstract
Contrast agents in dynamic contrast enhanced magnetic resonance imaging allow to localize tumors and observe their contrast kinetics, which is essential for cancer characterization and respective treatment decision-making. However, contrast agent administration is not only associated with adverse health risks, but also restricted for patients during pregnancy, and for those with kidney malfunction, or other adverse reactions. With contrast uptake as key biomarker for lesion malignancy, cancer recurrence risk, and treatment response, it becomes pivotal to reduce the dependency on intravenous contrast agent administration. To this end, we propose a multi-conditional latent diffusion model capable of acquisition time-conditioned image synthesis of DCE-MRI temporal sequences. To evaluate medical image synthesis, we additionally propose and validate the Fr'echet radiomics distance as an image quality measure based on biomarker variability between synthetic and real imaging data. Our results demonstrate our method's ability to generate realistic multi-sequence fat-saturated breast DCE-MRI and uncover the emerging potential of deep learning based contrast kinetics simulation. We publicly share our accessible codebase at https://github.com/RichardObi/ccnet and provide a user-friendly library for Fr'echet radiomics distance calculation at https://pypi.org/project/frd-score.
Create account to get full access
Overview
- This paper introduces a novel multi-condition latent diffusion model for learning contrast agent kinetics from dynamic contrast-enhanced MRI (DCE-MRI) data.
- The model can generate realistic contrast agent concentration curves, which could be useful for tasks like simulating contrast agent dynamics or generating synthetic training data.
- The paper demonstrates the model's ability to capture complex contrast agent behavior across different tissue types and physiological conditions.
Plain English Explanation
The researchers developed a new type of machine learning model called a "multi-condition latent diffusion model" that can learn how contrast agents behave in the body when used with dynamic contrast-enhanced MRI (DCE-MRI) scans. Contrast agents are substances that are injected into the body to help make certain structures more visible in medical imaging.
The model can generate realistic examples of how the concentration of a contrast agent changes over time in different tissues and under different physiological conditions. This could be useful for tasks like simulating contrast agent dynamics or generating synthetic training data for medical imaging analysis algorithms.
The key advantage of this model is its ability to capture the complex and varied ways that contrast agents can behave in the body, depending on factors like the tissue type and the patient's physiology. This is an important advance over simpler models that may not be able to fully replicate real-world contrast agent kinetics.
Technical Explanation
The core of the researchers' approach is a multi-condition latent diffusion model, which is a type of generative machine learning model that can learn to produce realistic samples of contrast agent concentration curves.
The model takes as input a set of conditioning variables that describe the physiological context, such as tissue type, blood flow, and permeability. It then uses a diffusion process to progressively transform a random noise signal into a plausible contrast agent concentration curve that matches the provided conditions.
The key innovations in this work include:
- A novel model architecture that can effectively capture the complex, nonlinear relationships between the conditioning variables and the resulting contrast agent kinetics.
- Training strategies that leverage both real DCE-MRI data and synthetic data generated by other models to improve the model's ability to generalize.
- Techniques for self-distillation that further enhance the model's performance.
Through extensive experiments, the researchers demonstrate that their multi-condition latent diffusion model can generate contrast agent curves that closely match real-world observations, outperforming previous approaches. This suggests the model could be a valuable tool for applications related to contrast agent dynamics in medical imaging.
Critical Analysis
The researchers acknowledge several limitations in their work. First, the model was trained and evaluated on a relatively small dataset of DCE-MRI scans, which may limit its ability to generalize to a wider range of physiological conditions. Expanding the training data, potentially by incorporating multimodal data sources, could help address this issue.
Additionally, the paper does not provide a detailed analysis of the model's robustness to noise or segmentation errors in the input conditioning variables. In a real-world setting, these factors could impact the model's performance and reliability, so further investigation in this area would be valuable.
Finally, while the researchers demonstrate the model's ability to generate plausible contrast agent curves, they do not explore how these synthetic samples could be leveraged for downstream applications, such as DCE-MRI analysis or training other medical imaging models. Assessing the practical utility of the generated samples would be an important next step.
Conclusion
This paper presents a novel multi-condition latent diffusion model for learning contrast agent kinetics from DCE-MRI data. The model's ability to capture the complex, nonlinear relationships between physiological conditions and contrast agent behavior is a significant advance, with potential applications in medical imaging simulation, data augmentation, and analysis.
While the current work has some limitations, the researchers have laid the groundwork for further exploration of this approach. Expanding the training data, evaluating the model's robustness, and investigating practical use cases could help unlock the full potential of this technology to benefit medical imaging and patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Similarity-aware Syncretic Latent Diffusion Model for Medical Image Translation with Representation Learning
Tingyi Lin, Pengju Lyu, Jie Zhang, Yuqing Wang, Cheng Wang, Jianjun Zhu
0
0
Non-contrast CT (NCCT) imaging may reduce image contrast and anatomical visibility, potentially increasing diagnostic uncertainty. In contrast, contrast-enhanced CT (CECT) facilitates the observation of regions of interest (ROI). Leading generative models, especially the conditional diffusion model, demonstrate remarkable capabilities in medical image modality transformation. Typical conditional diffusion models commonly generate images with guidance of segmentation labels for medical modal transformation. Limited access to authentic guidance and its low cardinality can pose challenges to the practical clinical application of conditional diffusion models. To achieve an equilibrium of generative quality and clinical practices, we propose a novel Syncretic generative model based on the latent diffusion model for medical image translation (S$^2$LDM), which can realize high-fidelity reconstruction without demand of additional condition during inference. S$^2$LDM enhances the similarity in distinct modal images via syncretic encoding and diffusing, promoting amalgamated information in the latent space and generating medical images with more details in contrast-enhanced regions. However, syncretic latent spaces in the frequency domain tend to favor lower frequencies, commonly locate in identical anatomic structures. Thus, S$^2$LDM applies adaptive similarity loss and dynamic similarity to guide the generation and supplements the shortfall in high-frequency details throughout the training process. Quantitative experiments confirm the effectiveness of our approach in medical image translation. Our code will release lately.
6/21/2024
🌀
Pre- to Post-Contrast Breast MRI Synthesis for Enhanced Tumour Segmentation
Richard Osuala, Smriti Joshi, Apostolia Tsirikoglou, Lidia Garrucho, Walter H. L. Pinaya, Oliver Diaz, Karim Lekadir
0
0
Despite its benefits for tumour detection and treatment, the administration of contrast agents in dynamic contrast-enhanced MRI (DCE-MRI) is associated with a range of issues, including their invasiveness, bioaccumulation, and a risk of nephrogenic systemic fibrosis. This study explores the feasibility of producing synthetic contrast enhancements by translating pre-contrast T1-weighted fat-saturated breast MRI to their corresponding first DCE-MRI sequence leveraging the capabilities of a generative adversarial network (GAN). Additionally, we introduce a Scaled Aggregate Measure (SAMe) designed for quantitatively evaluating the quality of synthetic data in a principled manner and serving as a basis for selecting the optimal generative model. We assess the generated DCE-MRI data using quantitative image quality metrics and apply them to the downstream task of 3D breast tumour segmentation. Our results highlight the potential of post-contrast DCE-MRI synthesis in enhancing the robustness of breast tumour segmentation models via data augmentation. Our code is available at https://github.com/RichardObi/pre_post_synthesis.
6/3/2024
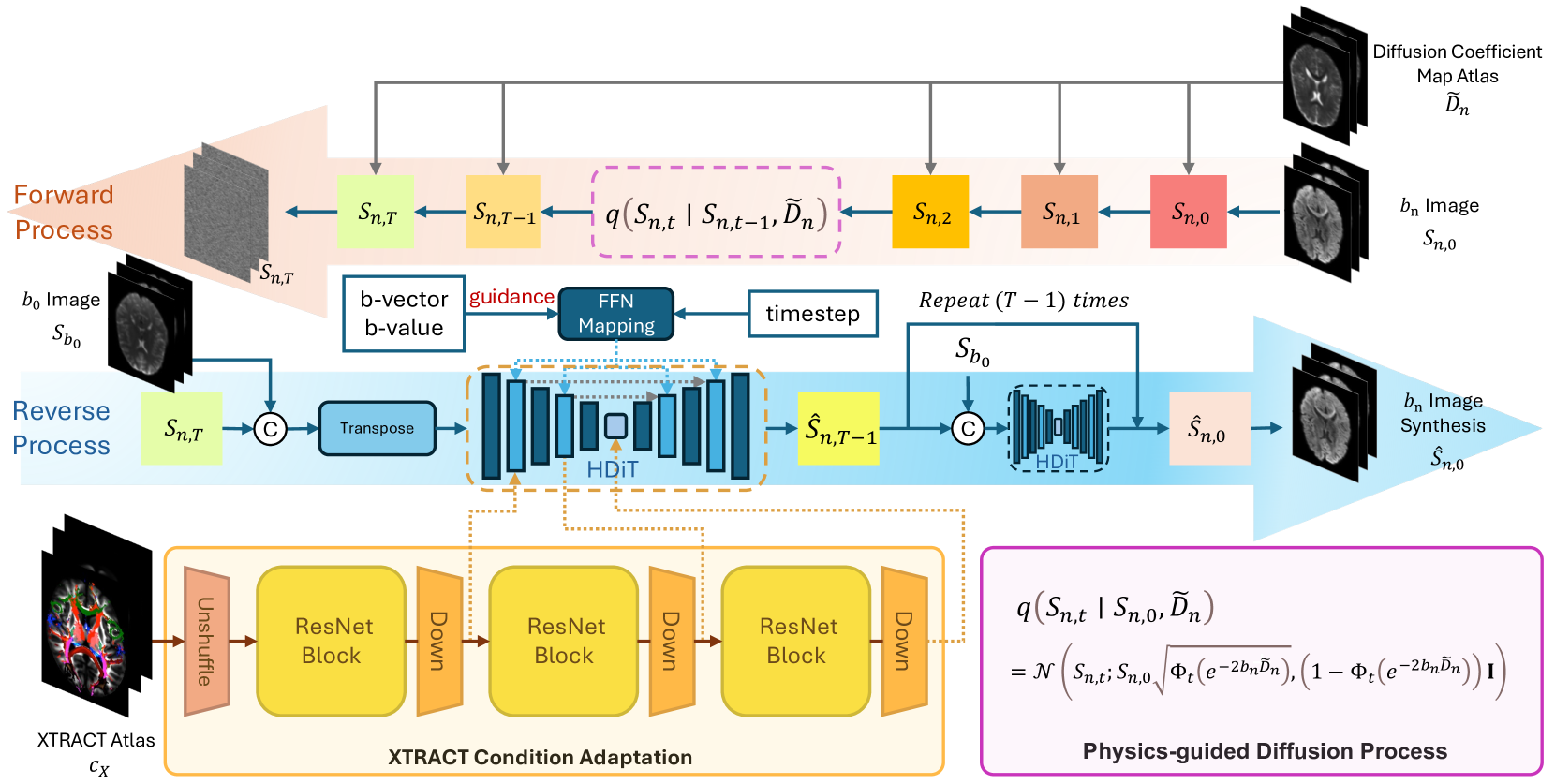
Phy-Diff: Physics-guided Hourglass Diffusion Model for Diffusion MRI Synthesis
Juanhua Zhang, Ruodan Yan, Alessandro Perelli, Xi Chen, Chao Li
0
0
Diffusion MRI (dMRI) is an important neuroimaging technique with high acquisition costs. Deep learning approaches have been used to enhance dMRI and predict diffusion biomarkers through undersampled dMRI. To generate more comprehensive raw dMRI, generative adversarial network based methods are proposed to include b-values and b-vectors as conditions, but they are limited by unstable training and less desirable diversity. The emerging diffusion model (DM) promises to improve generative performance. However, it remains challenging to include essential information in conditioning DM for more relevant generation, i.e., the physical principles of dMRI and white matter tract structures. In this study, we propose a physics-guided diffusion model to generate high-quality dMRI. Our model introduces the physical principles of dMRI in the noise evolution in the diffusion process and introduce a query-based conditional mapping within the difussion model. In addition, to enhance the anatomical fine detials of the generation, we introduce the XTRACT atlas as prior of white matter tracts by adopting an adapter technique. Our experiment results show that our method outperforms other state-of-the-art methods and has the potential to advance dMRI enhancement.
6/6/2024

CAVM: Conditional Autoregressive Vision Model for Contrast-Enhanced Brain Tumor MRI Synthesis
Lujun Gui, Chuyang Ye, Tianyi Yan
0
0
Contrast-enhanced magnetic resonance imaging (MRI) is pivotal in the pipeline of brain tumor segmentation and analysis. Gadolinium-based contrast agents, as the most commonly used contrast agents, are expensive and may have potential side effects, and it is desired to obtain contrast-enhanced brain tumor MRI scans without the actual use of contrast agents. Deep learning methods have been applied to synthesize virtual contrast-enhanced MRI scans from non-contrast images. However, as this synthesis problem is inherently ill-posed, these methods fall short in producing high-quality results. In this work, we propose Conditional Autoregressive Vision Model (CAVM) for improving the synthesis of contrast-enhanced brain tumor MRI. As the enhancement of image intensity grows with a higher dose of contrast agents, we assume that it is less challenging to synthesize a virtual image with a lower dose, where the difference between the contrast-enhanced and non-contrast images is smaller. Thus, CAVM gradually increases the contrast agent dosage and produces higher-dose images based on previous lower-dose ones until the final desired dose is achieved. Inspired by the resemblance between the gradual dose increase and the Chain-of-Thought approach in natural language processing, CAVM uses an autoregressive strategy with a decomposition tokenizer and a decoder. Specifically, the tokenizer is applied to obtain a more compact image representation for computational efficiency, and it decomposes the image into dose-variant and dose-invariant tokens. Then, a masked self-attention mechanism is developed for autoregression that gradually increases the dose of the virtual image based on the dose-variant tokens. Finally, the updated dose-variant tokens corresponding to the desired dose are decoded together with dose-invariant tokens to produce the final contrast-enhanced MRI.
6/26/2024