Towards a Quantitative Analysis of Coarticulation with a Phoneme-to-Articulatory Model

0

Sign in to get full access
Overview
- Provides a quantitative analysis of coarticulation using a phoneme-to-articulatory model
- Aims to better understand the complex interplay between speech sounds and articulatory movements
- Presents a model that can generate articulatory trajectories from phoneme sequences
Plain English Explanation
This research paper explores the relationship between the sounds we make when speaking (phonemes) and the movements of our vocal anatomy (articulatory movements). The researchers developed a model that can predict articulatory trajectories from a given sequence of phonemes.
Coarticulation is the phenomenon where the production of one sound is influenced by neighboring sounds. For example, when saying the word "top," the tongue movement for the "p" sound is affected by the preceding "o" sound. The researchers used their phoneme-to-articulatory model to quantify these coarticulatory effects, providing insights into the complex interplay between speech sounds and the physical movements required to produce them.
By better understanding coarticulation, the researchers hope to improve speech synthesis and articulatory-based speech recognition systems, which could have applications in areas like assistive technology and language learning.
Technical Explanation
The researchers developed a phoneme-to-articulatory model that can map a sequence of phonemes to the corresponding articulatory trajectories. The model consists of a recurrent neural network that takes a phoneme sequence as input and outputs the time-varying positions of various articulators, such as the tongue, lips, and velum.
To train and evaluate the model, the researchers used a dataset of articulatory and acoustic recordings from multiple speakers. They analyzed the model's ability to capture coarticulatory effects by comparing the predicted articulatory trajectories to the ground truth data. Specifically, they examined the influence of neighboring phonemes on the articulator movements for a target phoneme.
The results showed that the phoneme-to-articulatory model was able to accurately capture coarticulatory effects, demonstrating its potential for quantitative analysis of speech production. The researchers explored differences in articulatory configurations across genders and speech periods as well, providing further insights into the complex nature of human speech.
Critical Analysis
The researchers acknowledge that their model has limitations, such as its reliance on a relatively small dataset of articulatory recordings. Expanding the dataset, particularly with more diverse speakers and languages, could potentially improve the model's performance and generalization.
Additionally, the researchers note that their analysis focuses on coarticulation at the phoneme level, but speech production involves higher-level linguistic and prosodic factors that could also influence articulatory movements. Incorporating these factors into the model could lead to a more comprehensive understanding of speech production.
While the researchers demonstrate the potential of their phoneme-to-articulatory model for quantitative analysis of coarticulation, further validation and integration with other speech processing tasks, such as acoustic-to-articulatory inversion and articulatory-informed speech synthesis, could expand the practical applications of this research.
Conclusion
This research presents a phoneme-to-articulatory model that can quantify coarticulatory effects, providing valuable insights into the complex relationship between speech sounds and articulatory movements. By better understanding coarticulation, the researchers aim to improve speech-related technologies, such as speech synthesis and recognition, with potential applications in assistive devices, language learning, and beyond.
The model's ability to capture coarticulatory phenomena demonstrates its potential for advancing our understanding of human speech production, which could have broader implications for fields like linguistics, cognitive science, and speech therapy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards a Quantitative Analysis of Coarticulation with a Phoneme-to-Articulatory Model
Chaofei Fan, Jaimie M. Henderson, Chris Manning, Francis R. Willett
Prior coarticulation studies focus mainly on limited phonemic sequences and specific articulators, providing only approximate descriptions of the temporal extent and magnitude of coarticulation. This paper is an initial attempt to comprehensively investigate coarticulation. We leverage existing Electromagnetic Articulography (EMA) datasets to develop and train a phoneme-to-articulatory (P2A) model that can generate realistic EMA for novel phoneme sequences and replicate known coarticulation patterns. We use model-generated EMA on 9K minimal word pairs to analyze coarticulation magnitude and extent up to eight phonemes from the coarticulation trigger, and compare coarticulation resistance across different consonants. Our findings align with earlier studies and suggest a longer-range coarticulation effect than previously found. This model-based approach can potentially compare coarticulation between adults and children and across languages, offering new insights into speech production.
Read more8/13/2024

0
Simulating Articulatory Trajectories with Phonological Feature Interpolation
Angelo Ortiz Tandazo, Thomas Schatz, Thomas Hueber, Emmanuel Dupoux
As a first step towards a complete computational model of speech learning involving perception-production loops, we investigate the forward mapping between pseudo-motor commands and articulatory trajectories. Two phonological feature sets, based respectively on generative and articulatory phonology, are used to encode a phonetic target sequence. Different interpolation techniques are compared to generate smooth trajectories in these feature spaces, with a potential optimisation of the target value and timing to capture co-articulation effects. We report the Pearson correlation between a linear projection of the generated trajectories and articulatory data derived from a multi-speaker dataset of electromagnetic articulography (EMA) recordings. A correlation of 0.67 is obtained with an extended feature set based on generative phonology and a linear interpolation technique. We discuss the implications of our results for our understanding of the dynamics of biological motion.
Read more8/9/2024

0
Speaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech
Tobias Weise, Philipp Klumpp, Kubilay Can Demir, Paula Andrea P'erez-Toro, Maria Schuster, Elmar Noeth, Bjoern Heismann, Andreas Maier, Seung Hee Yang
This paper introduces a novel combination of two tasks, previously treated separately: acoustic-to-articulatory speech inversion (AAI) and phoneme-to-articulatory (PTA) motion estimation. We refer to this joint task as acoustic phoneme-to-articulatory speech inversion (APTAI) and explore two different approaches, both working speaker- and text-independently during inference. We use a multi-task learning setup, with the end-to-end goal of taking raw speech as input and estimating the corresponding articulatory movements, phoneme sequence, and phoneme alignment. While both proposed approaches share these same requirements, they differ in their way of achieving phoneme-related predictions: one is based on frame classification, the other on a two-staged training procedure and forced alignment. We reach competitive performance of 0.73 mean correlation for the AAI task and achieve up to approximately 87% frame overlap compared to a state-of-the-art text-dependent phoneme force aligner.
Read more7/4/2024
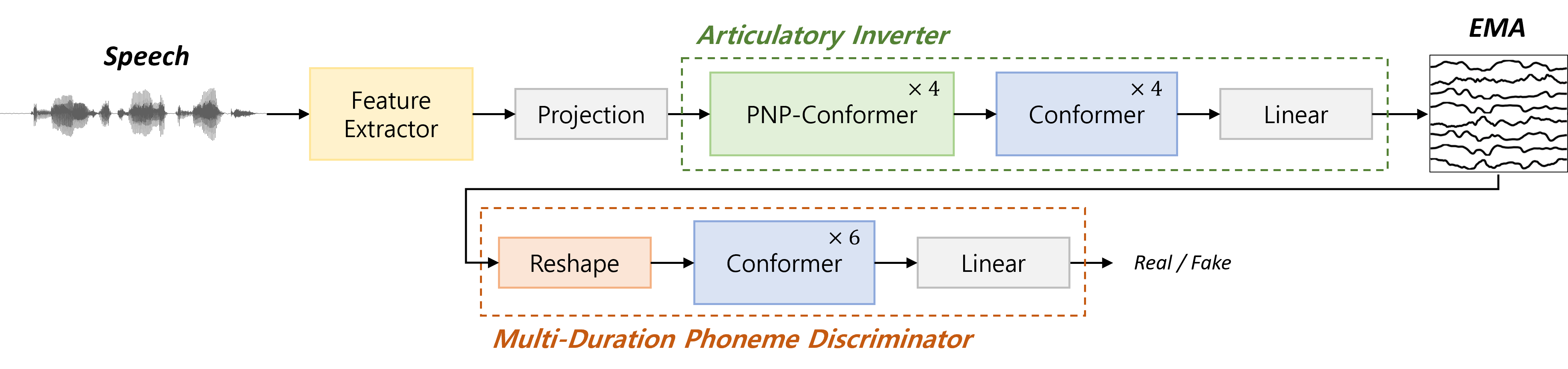
0
Speaker-Independent Acoustic-to-Articulatory Inversion through Multi-Channel Attention Discriminator
Woo-Jin Chung, Hong-Goo Kang
We present a novel speaker-independent acoustic-to-articulatory inversion (AAI) model, overcoming the limitations observed in conventional AAI models that rely on acoustic features derived from restricted datasets. To address these challenges, we leverage representations from a pre-trained self-supervised learning (SSL) model to more effectively estimate the global, local, and kinematic pattern information in Electromagnetic Articulography (EMA) signals during the AAI process. We train our model using an adversarial approach and introduce an attention-based Multi-duration phoneme discriminator (MDPD) designed to fully capture the intricate relationship among multi-channel articulatory signals. Our method achieves a Pearson correlation coefficient of 0.847, marking state-of-the-art performance in speaker-independent AAI models. The implementation details and code can be found online.
Read more6/26/2024