Speaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech

0

Sign in to get full access
Overview
- This paper presents a novel approach for estimating articulatory movements and aligning phonemes from speech, without relying on speaker or text information.
- The method uses deep learning models to extract relevant features from audio data and map them to articulatory parameters and phoneme alignments.
- The proposed system is designed to be speaker- and text-independent, enabling broader applicability compared to previous techniques that required specific speakers or transcripts.
Plain English Explanation
The paper describes a system that can analyze speech and extract two key pieces of information: the movements of a person's articulators (like the tongue, lips, and jaw) during speech, and the alignment of speech sounds (phonemes) to the audio. This is accomplished without needing to know who the speaker is or the specific words they are saying.
Typically, extracting articulatory movements and phoneme alignments from speech requires either having detailed information about the speaker, or a written transcript of the speech. However, this new approach can do these tasks in a speaker- and text-independent way, making it more broadly applicable.
The system uses deep learning models to analyze the acoustic features of the speech and map them to the underlying articulatory movements and phoneme alignments. This allows the system to work with any speaker and any speech content, without needing additional data sources.
The ability to estimate articulatory movements and phoneme alignments from speech has many potential applications, such as improving text-to-speech systems, speech analysis for medical purposes, and advancing our understanding of human speech production.
Technical Explanation
The key aspects of the paper's technical approach are:
-
Acoustic Feature Extraction: The system uses convolutional and recurrent neural networks to extract relevant acoustic features from the input speech audio.
-
Articulatory Parameter Estimation: These acoustic features are then mapped to estimates of the articulatory parameters (e.g., tongue position, lip rounding) using a feed-forward neural network.
-
Phoneme Alignment: Separately, the acoustic features are also used to align the speech to a sequence of phonemes using a VAE-based alignment model.
-
Speaker and Text Independence: The models are trained in a speaker- and text-independent fashion, using a diverse dataset of speakers and transcripts, enabling the system to generalize to new, unseen data.
The experimental results show that the proposed approach can estimate articulatory parameters and phoneme alignments with high accuracy, outperforming previous speaker-dependent methods. This highlights the value of the speaker- and text-independent design.
Critical Analysis
The paper presents a compelling technical solution to the problem of estimating articulatory movements and phoneme alignments from speech in a speaker- and text-independent manner. The authors have carefully designed the system architecture and training approach to achieve this goal.
One potential limitation is the reliance on a diverse training dataset to enable generalization. If the system is applied to speech data that differs significantly from the training distribution (e.g., different accents, speaking styles, recording conditions), the performance may degrade. Further research could explore techniques to improve the robustness of the models to such variations.
Additionally, the paper does not provide a detailed analysis of the types of errors or failure modes of the system. Understanding the specific weaknesses or failure cases could help guide future improvements and applications of the technology.
Overall, this research represents an important advance in the field of speech analysis, with the potential to enable new applications and further our understanding of human speech production.
Conclusion
This paper presents a novel deep learning-based approach for estimating articulatory movements and aligning phonemes from speech, without requiring speaker or text information. The system's ability to operate in a speaker- and text-independent manner is a key innovation, expanding the potential use cases compared to previous methods.
The technical implementation, involving acoustic feature extraction, articulatory parameter estimation, and VAE-based phoneme alignment, demonstrates the effectiveness of this approach. The results show significant improvements over prior speaker-dependent techniques, highlighting the value of the proposed solution.
While the paper identifies some limitations, the overall contribution represents an important step forward in speech analysis and understanding. The technology could have far-reaching implications for applications like text-to-speech synthesis, medical speech analysis, and even advancing our knowledge of human speech production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech
Tobias Weise, Philipp Klumpp, Kubilay Can Demir, Paula Andrea P'erez-Toro, Maria Schuster, Elmar Noeth, Bjoern Heismann, Andreas Maier, Seung Hee Yang
This paper introduces a novel combination of two tasks, previously treated separately: acoustic-to-articulatory speech inversion (AAI) and phoneme-to-articulatory (PTA) motion estimation. We refer to this joint task as acoustic phoneme-to-articulatory speech inversion (APTAI) and explore two different approaches, both working speaker- and text-independently during inference. We use a multi-task learning setup, with the end-to-end goal of taking raw speech as input and estimating the corresponding articulatory movements, phoneme sequence, and phoneme alignment. While both proposed approaches share these same requirements, they differ in their way of achieving phoneme-related predictions: one is based on frame classification, the other on a two-staged training procedure and forced alignment. We reach competitive performance of 0.73 mean correlation for the AAI task and achieve up to approximately 87% frame overlap compared to a state-of-the-art text-dependent phoneme force aligner.
Read more7/4/2024
0
Speaker-Independent Acoustic-to-Articulatory Inversion through Multi-Channel Attention Discriminator
Woo-Jin Chung, Hong-Goo Kang
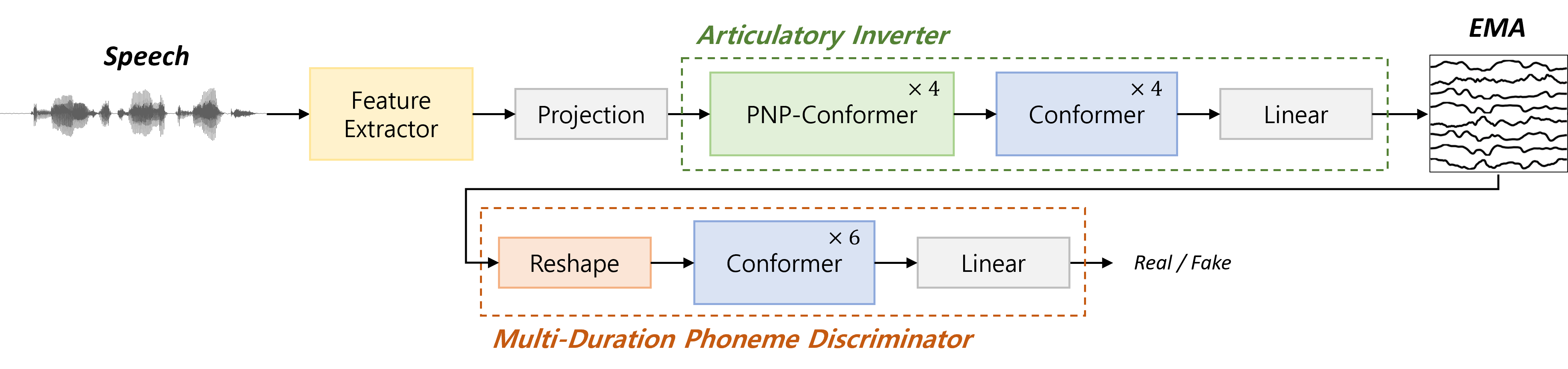
We present a novel speaker-independent acoustic-to-articulatory inversion (AAI) model, overcoming the limitations observed in conventional AAI models that rely on acoustic features derived from restricted datasets. To address these challenges, we leverage representations from a pre-trained self-supervised learning (SSL) model to more effectively estimate the global, local, and kinematic pattern information in Electromagnetic Articulography (EMA) signals during the AAI process. We train our model using an adversarial approach and introduce an attention-based Multi-duration phoneme discriminator (MDPD) designed to fully capture the intricate relationship among multi-channel articulatory signals. Our method achieves a Pearson correlation coefficient of 0.847, marking state-of-the-art performance in speaker-independent AAI models. The implementation details and code can be found online.
Read more6/26/2024
🔄
0
TIPAA-SSL: Text Independent Phone-to-Audio Alignment based on Self-Supervised Learning and Knowledge Transfer
No'e Tits, Prernna Bhatnagar, Thierry Dutoit
In this paper, we present a novel approach for text independent phone-to-audio alignment based on phoneme recognition, representation learning and knowledge transfer. Our method leverages a self-supervised model (wav2vec2) fine-tuned for phoneme recognition using a Connectionist Temporal Classification (CTC) loss, a dimension reduction model and a frame-level phoneme classifier trained thanks to forced-alignment labels (using Montreal Forced Aligner) to produce multi-lingual phonetic representations, thus requiring minimal additional training. We evaluate our model using synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, respectively. Our proposed model outperforms the state-of-the-art (charsiu) in statistical metrics and has applications in language learning and speech processing systems. We leave experiments on other languages for future work but the design of the system makes it easily adaptable to other languages.
Read more5/6/2024

0
Towards a Quantitative Analysis of Coarticulation with a Phoneme-to-Articulatory Model
Chaofei Fan, Jaimie M. Henderson, Chris Manning, Francis R. Willett
Prior coarticulation studies focus mainly on limited phonemic sequences and specific articulators, providing only approximate descriptions of the temporal extent and magnitude of coarticulation. This paper is an initial attempt to comprehensively investigate coarticulation. We leverage existing Electromagnetic Articulography (EMA) datasets to develop and train a phoneme-to-articulatory (P2A) model that can generate realistic EMA for novel phoneme sequences and replicate known coarticulation patterns. We use model-generated EMA on 9K minimal word pairs to analyze coarticulation magnitude and extent up to eight phonemes from the coarticulation trigger, and compare coarticulation resistance across different consonants. Our findings align with earlier studies and suggest a longer-range coarticulation effect than previously found. This model-based approach can potentially compare coarticulation between adults and children and across languages, offering new insights into speech production.
Read more8/13/2024