Towards Realistic Few-Shot Relation Extraction: A New Meta Dataset and Evaluation

0
🎯
Sign in to get full access
Overview
- This paper introduces a new meta dataset for few-shot relation extraction, which includes datasets derived from existing supervised relation extraction datasets as well as a few-shot version of the TACRED dataset.
- The authors conduct a comprehensive evaluation of six recent few-shot relation extraction methods using this dataset, and observe that no method clearly outperforms the others.
- The overall performance on this task is low, indicating a need for further research in this area.
- The authors release all versions of the data, both supervised and few-shot, for future research.
Plain English Explanation
The paper presents a new collection of datasets to evaluate the performance of machine learning models on the task of few-shot relation extraction. Relation extraction is the process of identifying and classifying the relationships between entities (like people, organizations, or locations) in text.
The key idea is to create a more realistic evaluation setup for few-shot relation extraction, where the test relations are different from what the model has seen before during training, and there are many candidate mentions that do not correspond to any of the relations of interest.
The authors take existing supervised relation extraction datasets, like NYT29 and WIKIDATA, and create few-shot versions of them. They also include a few-shot version of the TACRED dataset. This gives them a large collection of datasets to thoroughly evaluate the performance of several recent few-shot relation extraction methods.
Interestingly, the results show that no single method is clearly superior. The overall performance on this task is still quite low, suggesting that there is significant room for improvement and future research in this area.
Technical Explanation
The paper introduces a new meta dataset for few-shot relation extraction, which includes three components:
- Datasets derived from the existing supervised relation extraction datasets NYT29 and WIKIDATA.
- A few-shot version of the TACRED dataset.
These datasets were generated under realistic assumptions, such as:
- The test relations are different from any relations the model might have seen before.
- The training data is limited.
- There are many candidate relation mentions that do not correspond to any of the relations of interest.
Using this meta dataset, the authors conduct a comprehensive evaluation of six recent few-shot relation extraction methods: ProtoNetL, ProtoNetC, MetaNetL, MetaNetC, GMatching, and PAIR.
The results show that no method consistently outperforms the others, and the overall performance on this task is low. This indicates a substantial need for future research to improve few-shot relation extraction capabilities.
The authors release all versions of the data, both supervised and few-shot, for future research. This should enable other researchers to build upon this work and advance the state of the art in few-shot relation extraction.
Critical Analysis
The authors acknowledge several limitations and areas for future research in their paper:
- The performance of the evaluated methods is still quite low, suggesting that significant improvements are needed in few-shot relation extraction.
- The authors do not explore the effects of different few-shot learning setups, such as varying the number of training examples or the number of relations. Investigating these factors could provide valuable insights.
- The paper focuses on binary relation extraction, but many real-world scenarios involve n-ary relations. Extending the evaluation to n-ary facts could be an important next step.
- The authors note that the few-shot datasets they created may not fully capture the complexities of real-world few-shot relation extraction tasks. More realistic evaluation setups could be explored in future research.
Overall, this paper makes a valuable contribution by introducing a new meta dataset and conducting a comprehensive evaluation of few-shot relation extraction methods. However, the low performance of the evaluated methods highlights the need for continued research and innovation in this area.
Conclusion
This paper presents a new meta dataset for evaluating few-shot relation extraction models, which includes datasets derived from existing supervised relation extraction datasets as well as a few-shot version of the TACRED dataset. The authors use this dataset to comprehensively evaluate six recent few-shot relation extraction methods, but find that no single method clearly outperforms the others.
The overall performance on this task is still quite low, indicating a substantial need for future research to improve few-shot relation extraction capabilities. The authors release all versions of the data, both supervised and few-shot, to enable other researchers to build upon this work and advance the state of the art in this important area of natural language processing and few-shot learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
Towards Realistic Few-Shot Relation Extraction: A New Meta Dataset and Evaluation
Fahmida Alam, Md Asiful Islam, Robert Vacareanu, Mihai Surdeanu
We introduce a meta dataset for few-shot relation extraction, which includes two datasets derived from existing supervised relation extraction datasets NYT29 (Takanobu et al., 2019; Nayak and Ng, 2020) and WIKIDATA (Sorokin and Gurevych, 2017) as well as a few-shot form of the TACRED dataset (Sabo et al., 2021). Importantly, all these few-shot datasets were generated under realistic assumptions such as: the test relations are different from any relations a model might have seen before, limited training data, and a preponderance of candidate relation mentions that do not correspond to any of the relations of interest. Using this large resource, we conduct a comprehensive evaluation of six recent few-shot relation extraction methods, and observe that no method comes out as a clear winner. Further, the overall performance on this task is low, indicating substantial need for future research. We release all versions of the data, i.e., both supervised and few-shot, for future research.
Read more4/9/2024
⛏️
0
Document-Level In-Context Few-Shot Relation Extraction via Pre-Trained Language Models
Yilmazcan Ozyurt, Stefan Feuerriegel, Ce Zhang
Document-level relation extraction aims at inferring structured human knowledge from textual documents. State-of-the-art methods for this task use pre-trained language models (LMs) via fine-tuning, yet fine-tuning is computationally expensive and cannot adapt to new relation types or new LMs. As a remedy, we leverage the generalization capabilities of pre-trained LMs and present a novel framework for document-level in-context few-shot relation extraction. Our framework has three strengths: it eliminates the need (1) for named entity recognition and (2) for human annotations of documents, and (3) it can be updated to new LMs without re-training. We evaluate our framework using DocRED, the largest publicly available dataset for document-level relation extraction, and demonstrate that our framework achieves state-of-the-art performance. We further show that our framework actually performs much better than the original labels from the development set of DocRED. Finally, we demonstrate that our complete framework yields consistent performance gains across diverse datasets and across different pre-trained LMs. To the best of our knowledge, we are the first to reformulate the document-level relation extraction task as a tailored in-context few-shot learning paradigm.
Read more5/24/2024
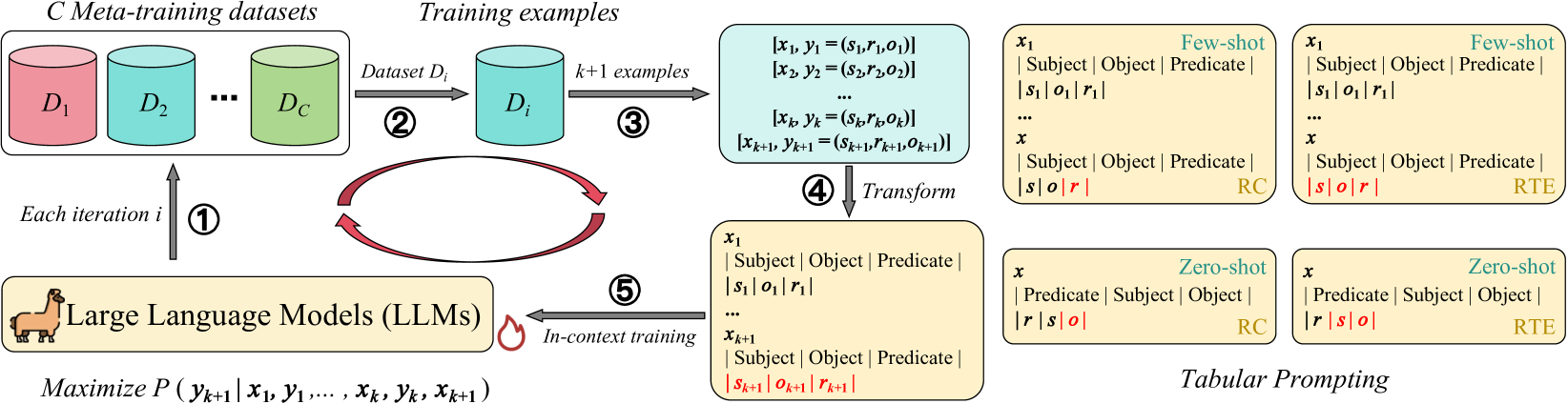
0
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Guozheng Li, Peng Wang, Jiajun Liu, Yikai Guo, Ke Ji, Ziyu Shang, Zijie Xu
Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce textsc{Micre} (textbf{M}eta textbf{I}n-textbf{C}ontext learning of LLMs for textbf{R}elation textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.
Read more4/30/2024

0
Empowering Few-Shot Relation Extraction with The Integration of Traditional RE Methods and Large Language Models
Ye Liu, Kai Zhang, Aoran Gan, Linan Yue, Feng Hu, Qi Liu, Enhong Chen
Few-Shot Relation Extraction (FSRE), a subtask of Relation Extraction (RE) that utilizes limited training instances, appeals to more researchers in Natural Language Processing (NLP) due to its capability to extract textual information in extremely low-resource scenarios. The primary methodologies employed for FSRE have been fine-tuning or prompt tuning techniques based on Pre-trained Language Models (PLMs). Recently, the emergence of Large Language Models (LLMs) has prompted numerous researchers to explore FSRE through In-Context Learning (ICL). However, there are substantial limitations associated with methods based on either traditional RE models or LLMs. Traditional RE models are hampered by a lack of necessary prior knowledge, while LLMs fall short in their task-specific capabilities for RE. To address these shortcomings, we propose a Dual-System Augmented Relation Extractor (DSARE), which synergistically combines traditional RE models with LLMs. Specifically, DSARE innovatively injects the prior knowledge of LLMs into traditional RE models, and conversely enhances LLMs' task-specific aptitude for RE through relation extraction augmentation. Moreover, an Integrated Prediction module is employed to jointly consider these two respective predictions and derive the final results. Extensive experiments demonstrate the efficacy of our proposed method.
Read more7/15/2024