Multilingual Instruction Tuning With Just a Pinch of Multilinguality
2401.01854
0
0
Abstract
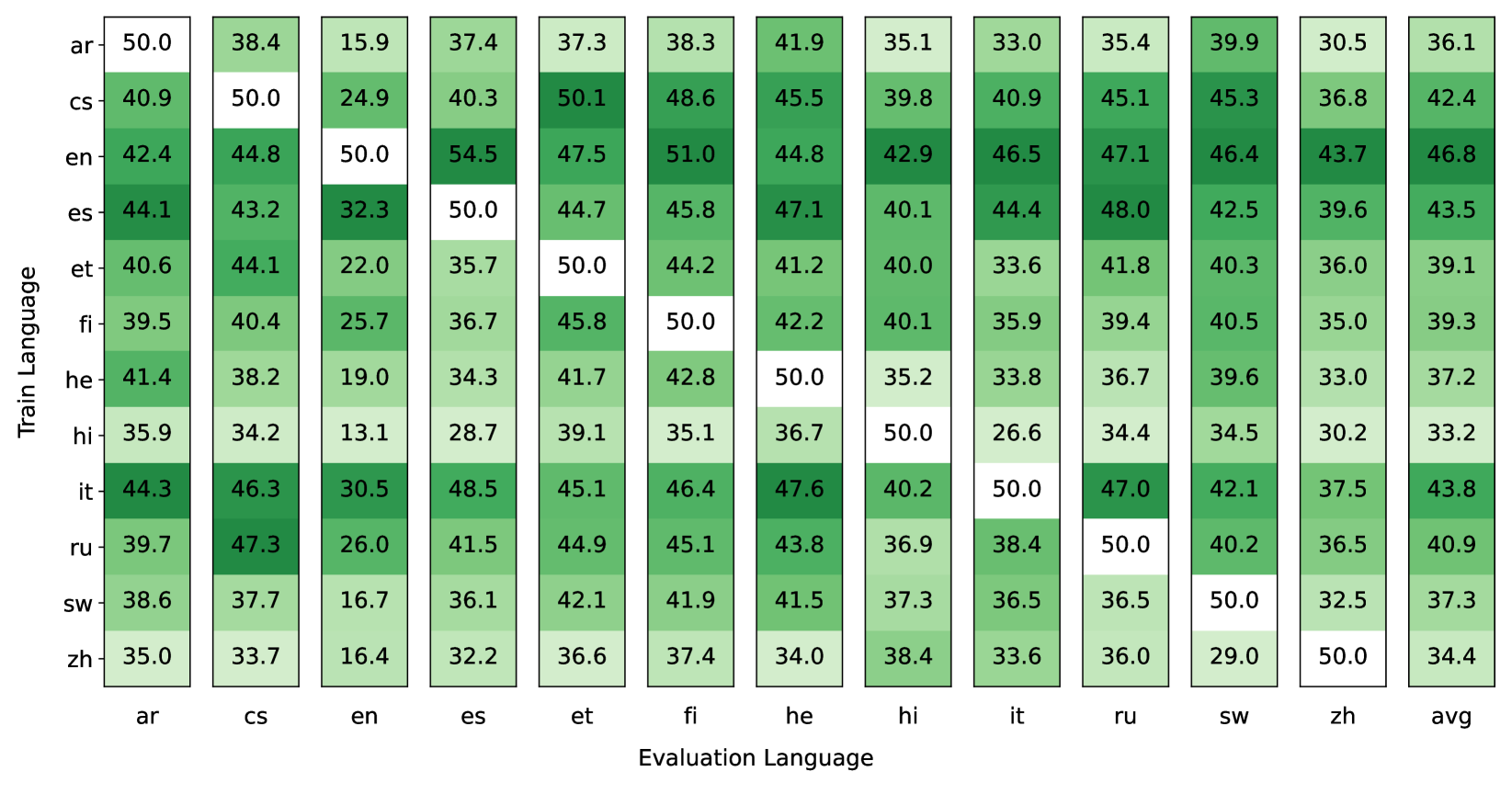
As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages from the pre-training corpus. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples integrated in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in multiple languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that diversifying the instruction tuning set with even just 2-4 languages significantly improves cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
Create account to get full access
Overview
• This paper explores a technique called "Multilingual Instruction Tuning" that can improve the performance of large language models on cross-lingual instruction-following tasks using just a small amount of multilingual data.
• The researchers find that by fine-tuning a pre-trained model on a diverse set of instructions across multiple languages, they can achieve strong results on cross-lingual tasks without requiring extensive multilingual training.
Plain English Explanation
Large language models like GPT-3 have shown impressive abilities to follow instructions and complete tasks. However, these models are usually trained on data primarily in English, which limits their performance on instructions in other languages.
The researchers in this paper propose a technique called "Multilingual Instruction Tuning" to address this challenge. The key idea is to fine-tune the language model on a diverse set of instructions spanning multiple languages, rather than just English. This "Multilingual Instruction Tuning" allows the model to learn the structure and patterns of instructions in different languages, even if it only has a small amount of non-English data.
By using this approach, the researchers were able to achieve strong performance on cross-lingual instruction-following tasks, where the model needs to understand and execute instructions in languages it was not extensively trained on. This is an important step towards building AI systems that can effectively communicate and collaborate with humans from diverse linguistic backgrounds.
Technical Explanation
The researchers used a pre-trained language model as the starting point, and then fine-tuned it on a diverse dataset of instructions in multiple languages, including English, Chinese, and Spanish. The dataset was constructed by combining existing instruction-following datasets, such as CrossFit and XNLI.
To assess the effectiveness of their approach, the researchers evaluated the fine-tuned model on cross-lingual instruction-following benchmarks, where the model needs to understand and execute instructions in languages it was not extensively trained on. They compared the performance of their "Multilingual Instruction Tuning" approach to models that were either trained only on English instructions or on a larger amount of multilingual data.
The results showed that the "Multilingual Instruction Tuning" approach was able to achieve strong performance on the cross-lingual tasks, even when using just a small amount of non-English data. This suggests that the model was able to effectively leverage the shared patterns and structure of instructions across languages, allowing it to generalize to new linguistic contexts.
Critical Analysis
The researchers acknowledge that their approach is limited by the availability and quality of the instruction-following datasets in non-English languages. They note that further improvements could be made by expanding the dataset to cover a wider range of languages and instruction types.
Additionally, while the "Multilingual Instruction Tuning" approach demonstrated promising results, it is still unclear how it would scale to a larger number of languages or how it would perform on more complex, open-ended instructions. Further research is needed to explore the limits and potential of this technique.
It is also worth considering the potential biases and limitations that may be inherited from the pre-trained language model and the instruction-following datasets used in the study. The researchers do not address these concerns in depth, and future work should aim to understand and mitigate any biases or fairness issues that may arise.
Conclusion
This paper presents an interesting approach to improving the cross-lingual instruction-following capabilities of large language models. By fine-tuning on a diverse set of instructions across multiple languages, the researchers were able to achieve strong performance on tasks where the model needs to understand and execute instructions in languages it was not extensively trained on.
This work represents an important step towards building AI systems that can effectively communicate and collaborate with humans from diverse linguistic backgrounds. As language models continue to advance, techniques like "Multilingual Instruction Tuning" will become increasingly important for ensuring these models are accessible and useful to people around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
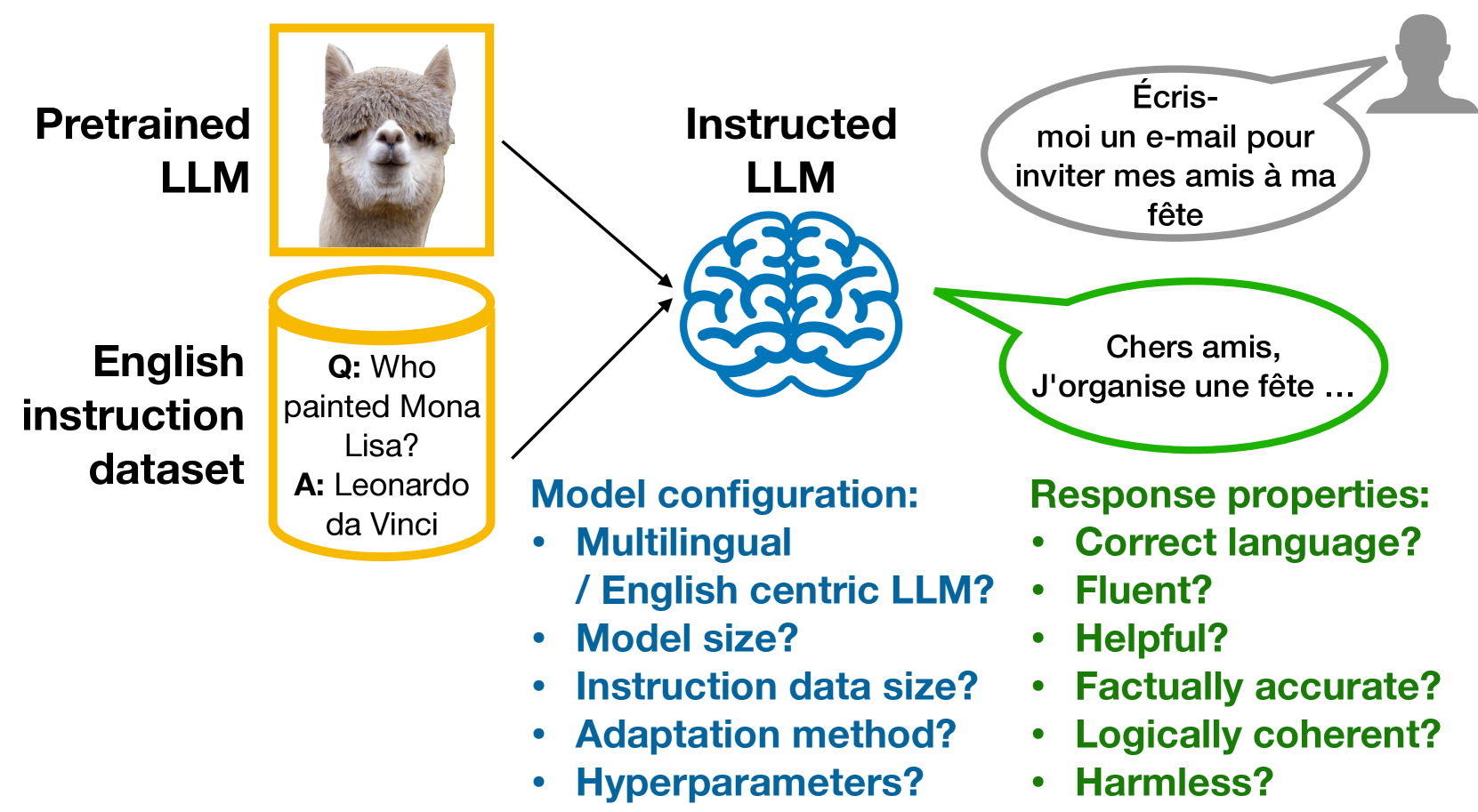
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Changjiang Gao, Hongda Hu, Peng Hu, Jiajun Chen, Jixing Li, Shujian Huang
0
0
Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
4/9/2024
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024
💬
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu
0
0
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
4/5/2024