Towards Signal Processing In Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of signal processing techniques in large language models (LLMs) to improve their performance on various tasks.
- The authors propose a new approach that combines LLMs with traditional signal processing methods, which they believe can lead to more robust and efficient language models.
- The paper presents a dataset and experimental results that demonstrate the potential benefits of this approach.
Plain English Explanation
Large language models like GPT-3 and BERT have become increasingly powerful in recent years, showing remarkable abilities in tasks like natural language processing and generation. However, these models can sometimes struggle with certain types of data, such as time-series information or numerical calculations.
The researchers in this paper believe that incorporating signal processing techniques into LLMs could help address these limitations. Signal processing is a field that deals with the analysis and manipulation of signals, such as audio or sensor data. By combining LLMs with signal processing methods, the authors hope to create language models that can better understand and work with different types of data, including time-series information.
To test this idea, the researchers developed a new dataset that includes text data along with associated time-series signals. They then trained LLMs on this dataset using their proposed approach, and compared the performance to traditional LLMs. The results suggest that the signal processing-enhanced LLMs can outperform conventional models on certain tasks, particularly those involving time-series data.
This work could have important implications for applications that require language models to work with a variety of data types, such as wireless application design or mathematical reasoning. By combining the strengths of LLMs and signal processing, the researchers believe they can create more versatile and effective language models for a wide range of real-world problems.
Technical Explanation
The paper begins by reviewing the current state of large language models (LLMs) and their limitations in dealing with certain types of data, such as time-series information. The authors argue that incorporating signal processing techniques into LLMs could help address these shortcomings.
To test this idea, the researchers developed a new dataset called the "Signal-Text" dataset. This dataset consists of text data paired with associated time-series signals, allowing the models to learn the relationship between the two. The authors trained several LLM architectures, including BERT and GPT-2, on this dataset using their proposed signal processing-enhanced approach.
The key aspect of the authors' method is the integration of signal processing modules into the LLM architecture. These modules are designed to extract and process the time-series information in the input data, which is then fed into the language model alongside the textual information. The researchers experimented with different signal processing techniques, such as Fourier analysis and wavelet transforms, to determine the most effective approach.
The experimental results showed that the signal processing-enhanced LLMs outperformed traditional LLMs on a variety of tasks, particularly those involving time-series data. The authors attribute this improvement to the model's ability to better capture and utilize the temporal and numerical information present in the input data.
The paper also discusses potential applications of this approach, such as in wireless application design and mathematical reasoning. The authors believe that by combining the strengths of LLMs and signal processing, they can create more versatile and effective language models for a wide range of real-world problems.
Critical Analysis
The paper presents a promising approach to improving the performance of large language models by incorporating signal processing techniques. The authors have done a thorough job of designing the experiment, creating a novel dataset, and evaluating the performance of their proposed method.
One potential limitation of the research is the specific dataset used. While the "Signal-Text" dataset appears to be well-designed, it may not fully capture the complexity and diversity of real-world data that LLMs would need to handle. It would be interesting to see if the signal processing-enhanced LLMs can maintain their performance advantage on more diverse and challenging datasets.
Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the signal processing modules. As LLMs continue to grow in size and complexity, the additional computational overhead introduced by these modules could be a concern, particularly for deployment in resource-constrained environments.
Further research may also be needed to understand the underlying mechanisms by which the signal processing techniques are improving the LLMs' performance. A deeper analysis of the specific types of information and patterns that are being captured by the signal processing modules could lead to even more effective model architectures and training approaches.
Overall, this paper represents an important step forward in the ongoing efforts to enhance the capabilities of large language models. By exploring the integration of signal processing techniques, the researchers have opened up new avenues for improving the robustness and versatility of these powerful AI systems.
Conclusion
This paper presents a novel approach to improving the performance of large language models by incorporating signal processing techniques. The authors have developed a new dataset and demonstrated that their signal processing-enhanced LLMs can outperform traditional LLMs on tasks involving time-series data.
The potential benefits of this approach are significant, as it could lead to more versatile and effective language models for a wide range of applications, from wireless application design to mathematical reasoning. By combining the strengths of LLMs and signal processing, the researchers believe they can create AI systems that are better equipped to handle the diverse and complex data encountered in the real world.
While the paper raises some interesting questions about the scalability and interpretability of the proposed approach, the overall results are promising and suggest that this line of research warrants further exploration. As the field of large language models continues to evolve, the integration of signal processing techniques could play a crucial role in unlocking new capabilities and driving the next generation of AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Signal Processing In Large Language Models
Prateek Verma, Mert Pilanci
This paper introduces the idea of applying signal processing inside a Large Language Model (LLM). With the recent explosion of generative AI, our work can help bridge two fields together, namely the field of signal processing and large language models. We draw parallels between classical Fourier-Transforms and Fourier Transform-like learnable time-frequency representations for every intermediate activation signal of an LLM. Once we decompose every activation signal across tokens into a time-frequency representation, we learn how to filter and reconstruct them, with all components learned from scratch, to predict the next token given the previous context. We show that for GPT-like architectures, our work achieves faster convergence and significantly increases performance by adding a minuscule number of extra parameters when trained for the same epochs. We hope this work paves the way for algorithms exploring signal processing inside the signals found in neural architectures like LLMs and beyond.
Read more9/19/2024

2
WaveletGPT: Wavelets Meet Large Language Models
Prateek Verma
Large Language Models (LLMs) have ushered in a new wave of artificial intelligence advancements impacting every scientific field and discipline. They are trained on a simple objective: to predict the next token given the previous context. We live in a world where most of the data around us, e.g., text, audio, and music, has a multi-scale structure associated with it. This paper infuses LLMs with traditional signal processing ideas, namely wavelets, during pre-training to take advantage of the structure. Without adding textbf{any extra parameters} to a GPT-style LLM architecture, we achieve the same pre-training performance almost twice as fast in text, raw audio, and symbolic music. This is achieved by imposing a structure on intermediate embeddings. When trained for the same number of training steps, we achieve significant gains in performance, which is comparable to pre-training a larger neural architecture. Our architecture allows every next token prediction access to intermediate embeddings at different temporal resolutions in every Transformer decoder block. This work will hopefully pave the way for incorporating multi-rate signal processing ideas into traditional LLM pre-training. Further, we showcase pushing model performance by improving internal structure instead of just going after scale.
Read more9/20/2024
0
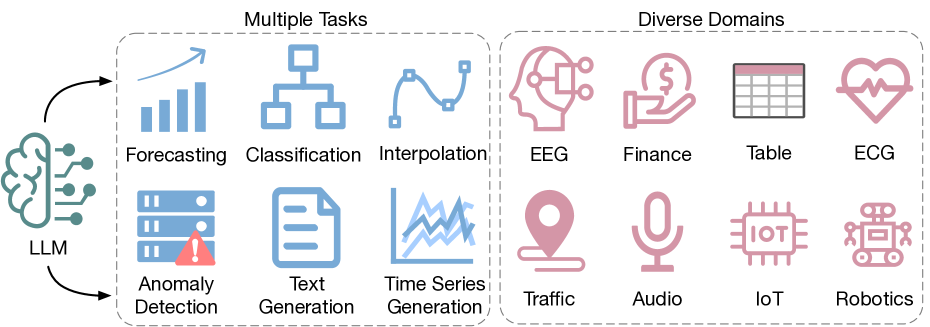
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
Read more5/8/2024

0
Quo Vadis ChatGPT? From Large Language Models to Large Knowledge Models
Venkat Venkatasubramanian, Arijit Chakraborty
The startling success of ChatGPT and other large language models (LLMs) using transformer-based generative neural network architecture in applications such as natural language processing and image synthesis has many researchers excited about potential opportunities in process systems engineering (PSE). The almost human-like performance of LLMs in these areas is indeed very impressive, surprising, and a major breakthrough. Their capabilities are very useful in certain tasks, such as writing first drafts of documents, code writing assistance, text summarization, etc. However, their success is limited in highly scientific domains as they cannot yet reason, plan, or explain due to their lack of in-depth domain knowledge. This is a problem in domains such as chemical engineering as they are governed by fundamental laws of physics and chemistry (and biology), constitutive relations, and highly technical knowledge about materials, processes, and systems. Although purely data-driven machine learning has its immediate uses, the long-term success of AI in scientific and engineering domains would depend on developing hybrid AI systems that use first principles and technical knowledge effectively. We call these hybrid AI systems Large Knowledge Models (LKMs), as they will not be limited to only NLP-based techniques or NLP-like applications. In this paper, we discuss the challenges and opportunities in developing such systems in chemical engineering.
Read more5/31/2024