Towards Solving Cocktail-Party: The First Method to Build a Realistic Dataset with Ground Truths for Speech Separation

0
🗣️
Sign in to get full access
Overview
- Speech separation is crucial for various real-world applications like human-machine interaction, hearing aids, and automatic meeting transcription.
- Deep learning has led to significant improvements in speech separation, but supervised learning methods using synthetic datasets have limitations in representing real-world mixtures.
- Unsupervised learning methods can handle realistic mixtures directly, but their results are still unconvincing.
- This paper introduces a method to create a realistic dataset with ground truth sources for speech separation.
Plain English Explanation
The paper focuses on the challenge of speech separation, which is the process of separating individual voices from a recorded audio that contains multiple speakers. This is an important task for various real-world applications, such as human-machine interaction, hearing aids, and automatic meeting transcription.
The researchers found that while deep learning has significantly improved speech separation, the supervised learning methods that use synthetic datasets have limitations in representing real-world audio mixtures. This is because it's challenging to create a realistic dataset with ground truth information for each speaker's signal.
To address this issue, the researchers propose a method to simultaneously record two speakers and obtain the ground truth for each person's voice. They then use this realistic dataset to evaluate the performance of a deep learning model based on Bidirectional Gated Recurrent Units (BGRU) and a clustering algorithm.
The results show that the proposed dataset improved the Signal-to-Distortion Ratio (SI-SDR) by 1.65 dB and the Perceptual Evaluation of Speech Quality (PESQ) by approximately 0.5. Additionally, the researchers found that their method improved the stability of the learned model at different distances between the microphone and the speakers.
Technical Explanation
The key technical aspects of the paper are:
-
Dataset Creation: The researchers propose a method to simultaneously record two speakers and obtain the ground truth for each person's voice. This is a crucial step, as the main challenge in designing a realistic dataset is the unavailability of ground truths for speaker signals in real-world audio mixtures.
-
Model Architecture: The researchers use a deep learning model based on Bidirectional Gated Recurrent Units (BGRU) and a clustering algorithm to benchmark their realistic dataset.
-
Evaluation Metrics: The researchers use two metrics to evaluate the performance of their method: Signal-to-Distortion Ratio (SI-SDR) and Perceptual Evaluation of Speech Quality (PESQ).
-
Experimental Results: The experiments show that the proposed dataset improved SI-SDR by 1.65 dB and PESQ by approximately 0.5 compared to previous methods. The researchers also found that their method improved the stability of the learned model at different distances between the microphone and the speakers.
Critical Analysis
The paper addresses an important challenge in speech separation by proposing a method to create a realistic dataset with ground truth sources. This is a significant contribution, as the lack of such datasets has been a major obstacle in the development of effective speech separation models.
However, the paper does not discuss any potential limitations or caveats of the proposed method. For example, it's unclear how scalable the simultaneous recording setup is and whether it can be easily replicated by other researchers. Additionally, the paper does not explore the performance of the method on a wider range of audio conditions or speaker characteristics.
Further research could investigate the generalizability of the proposed dataset and method, as well as explore ways to automate the dataset creation process to make it more accessible to the research community.
Conclusion
This paper introduces a novel method to create a realistic dataset with ground truth sources for speech separation, a crucial task for various real-world applications. The researchers demonstrate that their dataset can improve the performance of a deep learning model based on Bidirectional Gated Recurrent Units (BGRU) and a clustering algorithm, as measured by Signal-to-Distortion Ratio (SI-SDR) and Perceptual Evaluation of Speech Quality (PESQ).
The proposed approach represents an important step towards developing more effective speech separation systems that can handle real-world audio mixtures. The insights and dataset provided by this research have the potential to drive further advancements in the field and enable more robust human-machine interaction, hearing aid devices, and automated meeting transcription.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Towards Solving Cocktail-Party: The First Method to Build a Realistic Dataset with Ground Truths for Speech Separation
Rawad Melhem, Assef Jafar, Oumayma Al Dakkak
Speech separation is very important in real-world applications such as human-machine interaction, hearing aids devices, and automatic meeting transcription. In recent years, a significant improvement occurred towards the solution based on deep learning. In fact, much attention has been drawn to supervised learning methods using synthetic mixtures datasets despite their being not representative of real-world mixtures. The difficulty in building a realistic dataset led researchers to use unsupervised learning methods, because of their ability to handle realistic mixtures directly. The results of unsupervised learning methods are still unconvincing. In this paper, a method is introduced to create a realistic dataset with ground truth sources for speech separation. The main challenge in designing a realistic dataset is the unavailability of ground truths for speakers signals. To address this, we propose a method for simultaneously recording two speakers and obtaining the ground truth for each. We present a methodology for benchmarking our realistic dataset using a deep learning model based on Bidirectional Gated Recurrent Units (BGRU) and clustering algorithm. The experiments show that our proposed dataset improved SI-SDR (Scale Invariant Signal to Distortion Ratio) by 1.65 dB and PESQ (Perceptual Evaluation of Speech Quality) by approximately 0.5. We also evaluated the effectiveness of our method at different distances between the microphone and the speakers and found that it improved the stability of the learned model.
Read more8/29/2024

0
Improving Generalization of Speech Separation in Real-World Scenarios: Strategies in Simulation, Optimization, and Evaluation
Ke Chen, Jiaqi Su, Taylor Berg-Kirkpatrick, Shlomo Dubnov, Zeyu Jin
Achieving robust speech separation for overlapping speakers in various acoustic environments with noise and reverberation remains an open challenge. Although existing datasets are available to train separators for specific scenarios, they do not effectively generalize across diverse real-world scenarios. In this paper, we present a novel data simulation pipeline that produces diverse training data from a range of acoustic environments and content, and propose new training paradigms to improve quality of a general speech separation model. Specifically, we first introduce AC-SIM, a data simulation pipeline that incorporates broad variations in both content and acoustics. Then we integrate multiple training objectives into the permutation invariant training (PIT) to enhance separation quality and generalization of the trained model. Finally, we conduct comprehensive objective and human listening experiments across separation architectures and benchmarks to validate our methods, demonstrating substantial improvement of generalization on both non-homologous and real-world test sets.
Read more8/30/2024

0
Neural Blind Source Separation and Diarization for Distant Speech Recognition
Yoshiaki Bando, Tomohiko Nakamura, Shinji Watanabe
This paper presents a neural method for distant speech recognition (DSR) that jointly separates and diarizes speech mixtures without supervision by isolated signals. A standard separation method for multi-talker DSR is a statistical multichannel method called guided source separation (GSS). While GSS does not require signal-level supervision, it relies on speaker diarization results to handle unknown numbers of active speakers. To overcome this limitation, we introduce and train a neural inference model in a weakly-supervised manner, employing the objective function of a statistical separation method. This training requires only multichannel mixtures and their temporal annotations of speaker activities. In contrast to GSS, the trained model can jointly separate and diarize speech mixtures without any auxiliary information. The experiments with the AMI corpus show that our method outperforms GSS with oracle diarization results regarding word error rates. The code is available online.
Read more6/13/2024
0
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
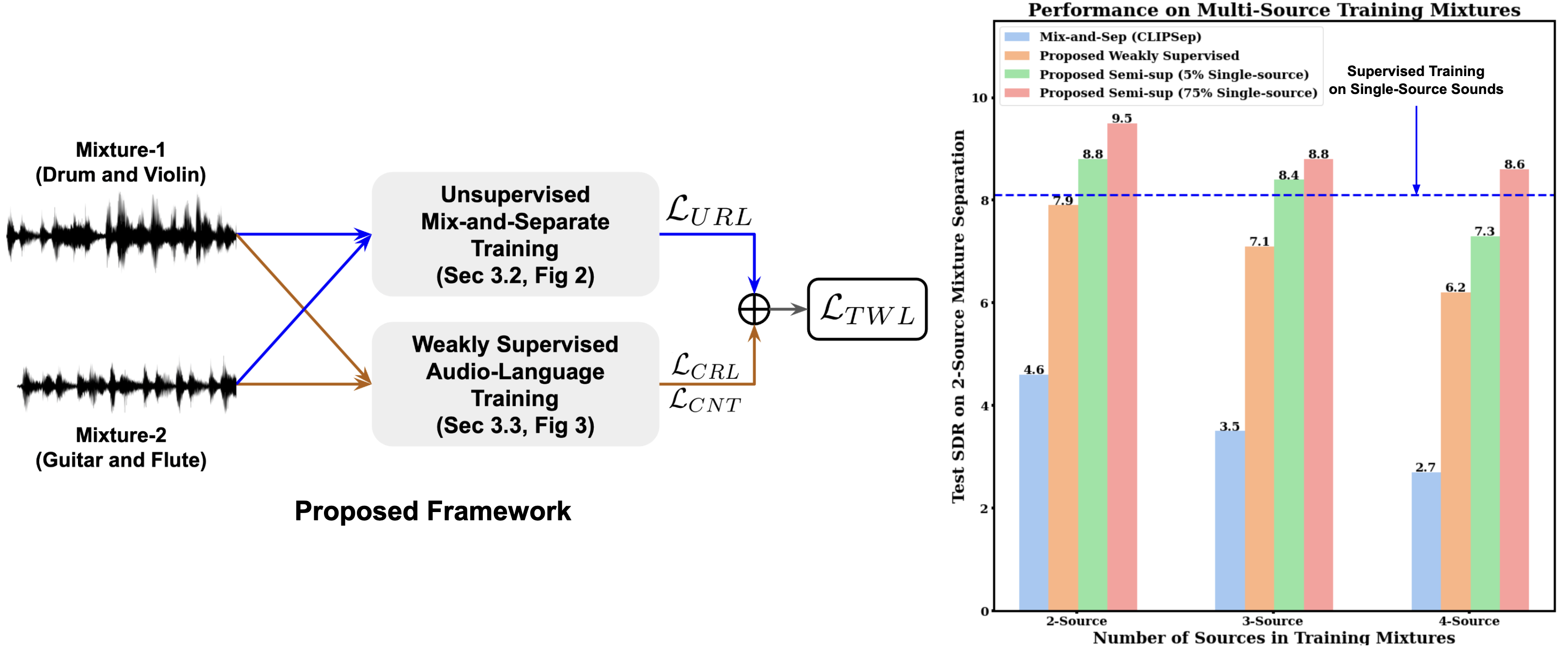
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Read more4/3/2024