Towards Trustworthy Unsupervised Domain Adaptation: A Representation Learning Perspective for Enhancing Robustness, Discrimination, and Generalization

0
Sign in to get full access
Overview
- This paper explores a novel approach to unsupervised domain adaptation, which aims to transfer knowledge from a source domain to a target domain without labeled data in the target domain.
- The authors propose a framework called "Towards Trustworthy Unsupervised Domain Adaptation" that addresses key challenges in this field, including negative transfer, domain shift, and lack of target labels.
- The proposed method leverages techniques like architecture search, style adaptation, and self-training to improve the reliability and trustworthiness of unsupervised domain adaptation.
Plain English Explanation
The paper discusses a way to help machine learning models work better when they are applied to new situations or "domains" that are different from the original training data. This can be a common problem, as models trained on one dataset may not perform as well when used on a different dataset or in a different real-world setting.
The key idea is to develop a framework that can effectively "transfer" the knowledge and capabilities of a model from the original "source" domain to a new "target" domain, without requiring any labeled data from the target domain. This is known as "unsupervised domain adaptation," and it can be challenging because the two domains may have significant differences.
To address this, the proposed method uses techniques like architecture search to automatically find the best model architecture for the target domain, style adaptation to align the visual styles between the source and target domains, and self-training to gradually improve the model's performance on the target domain without labeled data.
The goal is to make the unsupervised domain adaptation process more "trustworthy," meaning that the model's performance and behavior can be reliably predicted and understood, even when applied to new situations. This could have important implications for real-world applications where model reliability and transparency are critical, such as in medical diagnosis or autonomous driving.
Technical Explanation
The paper introduces a framework called "Towards Trustworthy Unsupervised Domain Adaptation" (TTUDA) that aims to address key challenges in unsupervised domain adaptation, such as negative transfer, domain shift, and lack of target labels.
The core components of the TTUDA framework include:
-
Architecture Search: The authors propose an architecture search technique to automatically find the optimal model architecture for the target domain, which can help overcome the domain shift problem.
-
Style Adaptation: The framework incorporates a style adaptation module to align the visual styles between the source and target domains, helping to bridge the gap between the two domains.
-
Self-Training: The authors leverage a self-training approach, where the model is iteratively refined on unlabeled target domain data, gradually improving its performance without requiring any labeled target data.
-
Trustworthiness Evaluation: The framework includes mechanisms to evaluate the trustworthiness of the adapted model, such as measuring its calibration and robustness to distribution shifts.
The authors conduct extensive experiments on several benchmark datasets, comparing the TTUDA framework to state-of-the-art unsupervised domain adaptation methods. The results demonstrate the effectiveness of the proposed approach in achieving reliable and trustworthy domain adaptation, outperforming existing techniques in terms of classification accuracy, calibration, and robustness.
Critical Analysis
The paper presents a comprehensive and well-designed framework for addressing the challenges of unsupervised domain adaptation. The authors have made several important contributions, including the integration of architecture search, style adaptation, and self-training techniques to improve the reliability and trustworthiness of the adapted models.
One potential limitation of the study is that the experiments are primarily conducted on image classification tasks. While this is a common benchmark for domain adaptation research, it would be valuable to evaluate the TTUDA framework on a wider range of tasks, such as language-driven zero-shot domain adaptation or remote sensing, to assess its broader applicability.
Additionally, the authors could have delved deeper into the specific failure modes or edge cases of the TTUDA framework, such as situations where the self-training process might lead to negative transfer or the architecture search may not converge to an optimal solution. Exploring these potential weaknesses could provide valuable insights for future improvements and adaptations of the framework.
Overall, the paper presents a promising and innovative approach to unsupervised domain adaptation, with a strong focus on trustworthiness and reliability. The authors have made a significant contribution to the field, and their work could have important implications for the development of more robust and trustworthy machine learning systems in the real world.
Conclusion
The "Towards Trustworthy Unsupervised Domain Adaptation" paper introduces a novel framework that addresses key challenges in the field of unsupervised domain adaptation. By integrating techniques like architecture search, style adaptation, and self-training, the proposed TTUDA framework aims to improve the reliability and trustworthiness of models when they are applied to new domains without labeled data.
The experimental results demonstrate the effectiveness of the TTUDA approach, with the framework outperforming state-of-the-art unsupervised domain adaptation methods in terms of classification accuracy, calibration, and robustness. This work has important implications for developing more trustworthy and reliable machine learning systems, which could be crucial in real-world applications where model performance and transparency are critical.
While the current focus is on image classification tasks, future research could explore the application of the TTUDA framework to a wider range of domains, such as natural language processing or remote sensing, to further validate its broader utility. Additionally, a deeper analysis of the framework's failure modes and edge cases could provide valuable insights for continued improvement and refinement of the approach.
Overall, the "Towards Trustworthy Unsupervised Domain Adaptation" paper represents a significant contribution to the field of domain adaptation, paving the way for more reliable and trustworthy machine learning systems that can be effectively deployed in diverse real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Trustworthy Unsupervised Domain Adaptation: A Representation Learning Perspective for Enhancing Robustness, Discrimination, and Generalization
Jia-Li Yin, Haoyuan Zheng, Ximeng Liu
Robust Unsupervised Domain Adaptation (RoUDA) aims to achieve not only clean but also robust cross-domain knowledge transfer from a labeled source domain to an unlabeled target domain. A number of works have been conducted by directly injecting adversarial training (AT) in UDA based on the self-training pipeline and then aiming to generate better adversarial examples (AEs) for AT. Despite the remarkable progress, these methods only focus on finding stronger AEs but neglect how to better learn from these AEs, thus leading to unsatisfied results. In this paper, we investigate robust UDA from a representation learning perspective and design a novel algorithm by utilizing the mutual information theory, dubbed MIRoUDA. Specifically, through mutual information optimization, MIRoUDA is designed to achieve three characteristics that are highly expected in robust UDA, i.e., robustness, discrimination, and generalization. We then propose a dual-model framework accordingly for robust UDA learning. Extensive experiments on various benchmarks verify the effectiveness of the proposed MIRoUDA, in which our method surpasses the state-of-the-arts by a large margin.
Read more6/21/2024

0
EUDA: An Efficient Unsupervised Domain Adaptation via Self-Supervised Vision Transformer
Ali Abedi, Q. M. Jonathan Wu, Ning Zhang, Farhad Pourpanah
Unsupervised domain adaptation (UDA) aims to mitigate the domain shift issue, where the distribution of training (source) data differs from that of testing (target) data. Many models have been developed to tackle this problem, and recently vision transformers (ViTs) have shown promising results. However, the complexity and large number of trainable parameters of ViTs restrict their deployment in practical applications. This underscores the need for an efficient model that not only reduces trainable parameters but also allows for adjustable complexity based on specific needs while delivering comparable performance. To achieve this, in this paper we introduce an Efficient Unsupervised Domain Adaptation (EUDA) framework. EUDA employs the DINOv2, which is a self-supervised ViT, as a feature extractor followed by a simplified bottleneck of fully connected layers to refine features for enhanced domain adaptation. Additionally, EUDA employs the synergistic domain alignment loss (SDAL), which integrates cross-entropy (CE) and maximum mean discrepancy (MMD) losses, to balance adaptation by minimizing classification errors in the source domain while aligning the source and target domain distributions. The experimental results indicate the effectiveness of EUDA in producing comparable results as compared with other state-of-the-art methods in domain adaptation with significantly fewer trainable parameters, between 42% to 99.7% fewer. This showcases the ability to train the model in a resource-limited environment. The code of the model is available at: https://github.com/A-Abedi/EUDA.
Read more8/1/2024
🤷
0
Unsupervised Domain Adaptation Architecture Search with Self-Training for Land Cover Mapping
Clifford Broni-Bediako, Junshi Xia, Naoto Yokoya
Unsupervised domain adaptation (UDA) is a challenging open problem in land cover mapping. Previous studies show encouraging progress in addressing cross-domain distribution shifts on remote sensing benchmarks for land cover mapping. The existing works are mainly built on large neural network architectures, which makes them resource-hungry systems, limiting their practical impact for many real-world applications in resource-constrained environments. Thus, we proposed a simple yet effective framework to search for lightweight neural networks automatically for land cover mapping tasks under domain shifts. This is achieved by integrating Markov random field neural architecture search (MRF-NAS) into a self-training UDA framework to search for efficient and effective networks under a limited computation budget. This is the first attempt to combine NAS with self-training UDA as a single framework for land cover mapping. We also investigate two different pseudo-labelling approaches (confidence-based and energy-based) in self-training scheme. Experimental results on two recent datasets (OpenEarthMap & FLAIR #1) for remote sensing UDA demonstrate a satisfactory performance. With only less than 2M parameters and 30.16 GFLOPs, the best-discovered lightweight network reaches state-of-the-art performance on the regional target domain of OpenEarthMap (59.38% mIoU) and the considered target domain of FLAIR #1 (51.19% mIoU). The code is at https://github.com/cliffbb/UDA-NAS}{https://github.com/cliffbb/UDA-NAS.
Read more4/24/2024
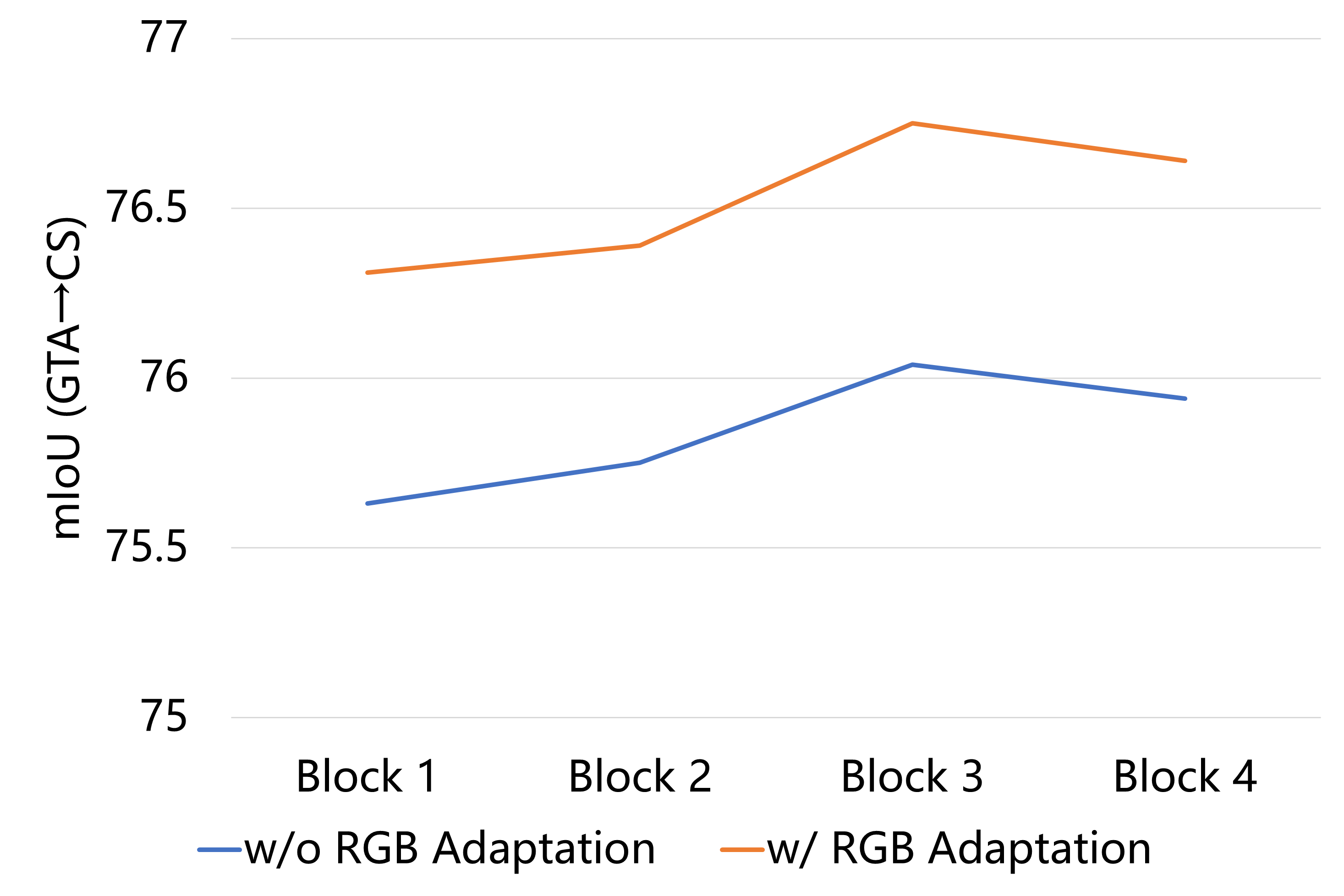
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024