Towards Unified Facial Action Unit Recognition Framework by Large Language Models

0

Sign in to get full access
Overview
- Provides a plain English summary of a technical research paper
- Covers the paper's key ideas, methodology, and findings in an accessible way
- Includes a critical analysis of the research, discussing limitations and areas for further study
- Concludes by highlighting the paper's main takeaways and potential implications
Plain English Explanation
This research paper explores a new approach for recognizing facial expressions, which are known as "facial action units." Facial action units are the individual movements of different parts of the face that combine to create various expressions, like a smile or a frown.
The researchers developed a new deep learning model that can accurately detect these facial action units. Their model, called AUFormer, uses a type of neural network called a "vision transformer" that is more efficient than previous approaches.
The key innovation is the way the model learns to recognize the relationships between different facial action units. By modeling these complex relationships, the model can better understand the underlying facial expressions.
The researchers tested their model on standard datasets of facial expressions and found that it outperformed other state-of-the-art approaches. Their method for learning contrastive features also helps the model generalize better to new situations.
Technical Explanation
The paper presents a new deep learning framework for facial action unit recognition called AUFormer. The key innovation is the use of vision transformers, which are a more parameter-efficient type of neural network compared to traditional convolutional neural networks.
The model learns to recognize the complex relationships between different facial action units using a multi-scale dynamic hierarchical relationship modeling approach. This allows the model to better understand the underlying facial expressions.
The researchers also developed a contrastive feature learning method to improve the model's ability to generalize to new scenarios. This involves training the model to learn features that can distinguish between different facial action units.
Evaluation on standard facial expression datasets shows that the AUFormer model outperforms other state-of-the-art approaches in terms of facial action unit recognition accuracy.
Critical Analysis
The paper provides a compelling new approach for facial action unit recognition that leverages the strengths of vision transformers and advanced relationship modeling techniques. However, the authors acknowledge several limitations and areas for future work:
- The model was only evaluated on standard datasets, and its performance on real-world, in-the-wild scenarios is still unknown.
- The relationship modeling approach, while powerful, may be computationally expensive and could benefit from further optimization.
- The contrastive feature learning method relies on having well-labeled training data, which may not always be available in practical applications.
Additionally, while the paper makes a strong technical contribution, there could be ethical considerations around the use of facial analysis technology, such as concerns about privacy and potential misuse. The authors do not address these issues, which would be important for readers to consider.
Overall, the research represents an important advance in facial expression recognition, but further work is needed to fully understand the model's real-world performance and implications.
Conclusion
This research paper presents a novel deep learning framework called AUFormer for recognizing facial action units, which are the building blocks of facial expressions. The key innovation is the use of vision transformers and advanced relationship modeling techniques to better capture the complex interdependencies between different facial movements.
The results show that the AUFormer model outperforms other state-of-the-art approaches on standard facial expression datasets. This suggests that the proposed methods could lead to more accurate and robust facial analysis systems, with potential applications in areas like human-computer interaction, mental health monitoring, and even autonomous driving.
However, the authors also acknowledge several limitations and areas for future work, such as evaluating the model's performance in real-world scenarios and addressing potential ethical concerns around facial analysis technology. Nonetheless, this research represents an important step forward in the field of facial expression recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Guohong Hu, Xing Lan, Hanyu Jiang, Jiayi Lyu, Jian Xue
Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
Read more9/16/2024
0
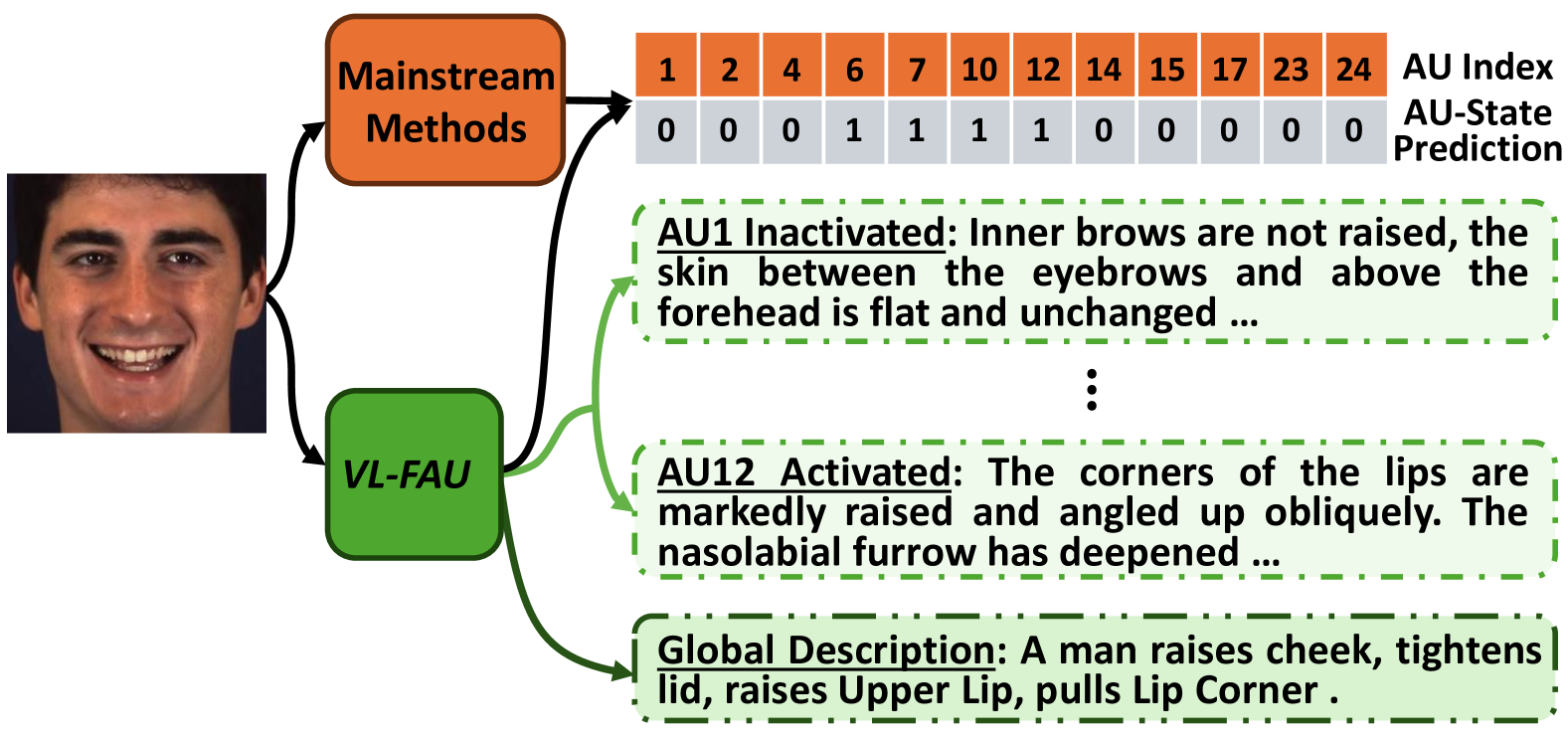
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Xuri Ge, Junchen Fu, Fuhai Chen, Shan An, Nicu Sebe, Joemon M. Jose
Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
Read more8/2/2024

0
AUFormer: Vision Transformers are Parameter-Efficient Facial Action Unit Detectors
Kaishen Yuan, Zitong Yu, Xin Liu, Weicheng Xie, Huanjing Yue, Jingyu Yang
Facial Action Units (AU) is a vital concept in the realm of affective computing, and AU detection has always been a hot research topic. Existing methods suffer from overfitting issues due to the utilization of a large number of learnable parameters on scarce AU-annotated datasets or heavy reliance on substantial additional relevant data. Parameter-Efficient Transfer Learning (PETL) provides a promising paradigm to address these challenges, whereas its existing methods lack design for AU characteristics. Therefore, we innovatively investigate PETL paradigm to AU detection, introducing AUFormer and proposing a novel Mixture-of-Knowledge Expert (MoKE) collaboration mechanism. An individual MoKE specific to a certain AU with minimal learnable parameters first integrates personalized multi-scale and correlation knowledge. Then the MoKE collaborates with other MoKEs in the expert group to obtain aggregated information and inject it into the frozen Vision Transformer (ViT) to achieve parameter-efficient AU detection. Additionally, we design a Margin-truncated Difficulty-aware Weighted Asymmetric Loss (MDWA-Loss), which can encourage the model to focus more on activated AUs, differentiate the difficulty of unactivated AUs, and discard potential mislabeled samples. Extensive experiments from various perspectives, including within-domain, cross-domain, data efficiency, and micro-expression domain, demonstrate AUFormer's state-of-the-art performance and robust generalization abilities without relying on additional relevant data. The code for AUFormer is available at https://github.com/yuankaishen2001/AUFormer.
Read more7/10/2024

0
Multi-scale Dynamic and Hierarchical Relationship Modeling for Facial Action Units Recognition
Zihan Wang, Siyang Song, Cheng Luo, Songhe Deng, Weicheng Xie, Linlin Shen
Human facial action units (AUs) are mutually related in a hierarchical manner, as not only they are associated with each other in both spatial and temporal domains but also AUs located in the same/close facial regions show stronger relationships than those of different facial regions. While none of existing approach thoroughly model such hierarchical inter-dependencies among AUs, this paper proposes to comprehensively model multi-scale AU-related dynamic and hierarchical spatio-temporal relationship among AUs for their occurrences recognition. Specifically, we first propose a novel multi-scale temporal differencing network with an adaptive weighting block to explicitly capture facial dynamics across frames at different spatial scales, which specifically considers the heterogeneity of range and magnitude in different AUs' activation. Then, a two-stage strategy is introduced to hierarchically model the relationship among AUs based on their spatial distribution (i.e., local and cross-region AU relationship modelling). Experimental results achieved on BP4D and DISFA show that our approach is the new state-of-the-art in the field of AU occurrence recognition. Our code is publicly available at https://github.com/CVI-SZU/MDHR.
Read more4/10/2024