AUFormer: Vision Transformers are Parameter-Efficient Facial Action Unit Detectors

0

Sign in to get full access
Overview
- The paper introduces AUFormer, a vision transformer-based model for efficient facial action unit (AU) detection.
- AUFormer achieves state-of-the-art performance on several AU detection datasets while being more parameter-efficient than previous methods.
- The key innovations include a novel mixture-of-experts architecture and a margin-truncated difficulty-aware loss function.
Plain English Explanation
The researchers have developed a new model called AUFormer that can detect facial action units (AUs) - specific movements of the face that correspond to different emotions or expressions. AUs are an important tool for understanding human behavior and expression.
AUFormer uses a type of artificial intelligence called a vision transformer, which is more efficient than traditional convolutional neural networks while still achieving high accuracy. The researchers designed a unique architecture where AUFormer has multiple "expert" sub-models that each specialize in detecting certain AUs. This mixture-of-experts approach allows the model to efficiently learn the diverse patterns associated with different facial movements.
Additionally, the researchers developed a new loss function that takes into account the varying difficulty of detecting different AUs. This "margin-truncated difficulty-aware" loss encourages the model to focus more on accurately detecting the harder-to-learn AUs, rather than just optimizing for overall accuracy.
The result is a highly parameter-efficient AU detection model that outperforms previous state-of-the-art methods on several benchmark datasets. This could enable more widespread use of AU detection in applications like human-computer interaction, mental health monitoring, and animation.
Technical Explanation
The key technical innovations in AUFormer include:
-
Mixture-of-Experts Architecture: Instead of a single monolithic model, AUFormer has a mixture-of-experts (MoE) design where multiple specialized sub-models ("experts") are combined to detect different facial action units. This allows the model to more efficiently learn the diverse patterns associated with different AUs.
-
Margin-Truncated Difficulty-Aware Loss: The researchers developed a new loss function that takes into account the varying difficulty of detecting different AUs. This "margin-truncated difficulty-aware" loss encourages the model to focus more on accurately detecting the harder-to-learn AUs, rather than just optimizing for overall accuracy.
-
Vision Transformer Backbone: AUFormer uses a vision transformer as its backbone, which is more parameter-efficient than traditional convolutional neural networks while still achieving state-of-the-art performance on AU detection tasks. The transformer architecture allows the model to capture long-range dependencies in facial features.
In experiments, AUFormer outperformed previous state-of-the-art methods on several facial AU detection benchmarks, including DISFA, BP4D, and GFT, while requiring significantly fewer model parameters.
Critical Analysis
The paper provides a thorough evaluation of AUFormer's performance and makes a compelling case for the benefits of its novel architecture and loss function. However, a few potential limitations or areas for future work are worth considering:
-
Generalization to in-the-wild data: The experiments were conducted on relatively constrained, laboratory-collected datasets. More research is needed to assess how well AUFormer would perform on real-world, unconstrained facial data, which can be more challenging due to variations in lighting, occlusions, and head poses.
-
Interpretability: While the mixture-of-experts approach can improve performance, it may also reduce the model's interpretability, as it can be harder to understand how the different sub-models contribute to the final predictions. Developing more interpretable AU detection models could be a valuable direction for future work.
-
Model Complexity: Although AUFormer is more parameter-efficient than previous methods, the MoE architecture still adds a significant amount of complexity compared to a single-model approach. The trade-offs between model complexity, efficiency, and performance should be carefully considered for different application scenarios.
Conclusion
The AUFormer model represents an important advancement in facial action unit detection, demonstrating how vision transformers and novel architectural and loss function designs can lead to more parameter-efficient and high-performing AU detectors. This work could pave the way for more widespread adoption of AU detection in various applications, from human-computer interaction to mental health monitoring and beyond. The critical analysis also suggests fruitful avenues for future research to further improve the generalization, interpretability, and efficiency of these types of models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AUFormer: Vision Transformers are Parameter-Efficient Facial Action Unit Detectors
Kaishen Yuan, Zitong Yu, Xin Liu, Weicheng Xie, Huanjing Yue, Jingyu Yang
Facial Action Units (AU) is a vital concept in the realm of affective computing, and AU detection has always been a hot research topic. Existing methods suffer from overfitting issues due to the utilization of a large number of learnable parameters on scarce AU-annotated datasets or heavy reliance on substantial additional relevant data. Parameter-Efficient Transfer Learning (PETL) provides a promising paradigm to address these challenges, whereas its existing methods lack design for AU characteristics. Therefore, we innovatively investigate PETL paradigm to AU detection, introducing AUFormer and proposing a novel Mixture-of-Knowledge Expert (MoKE) collaboration mechanism. An individual MoKE specific to a certain AU with minimal learnable parameters first integrates personalized multi-scale and correlation knowledge. Then the MoKE collaborates with other MoKEs in the expert group to obtain aggregated information and inject it into the frozen Vision Transformer (ViT) to achieve parameter-efficient AU detection. Additionally, we design a Margin-truncated Difficulty-aware Weighted Asymmetric Loss (MDWA-Loss), which can encourage the model to focus more on activated AUs, differentiate the difficulty of unactivated AUs, and discard potential mislabeled samples. Extensive experiments from various perspectives, including within-domain, cross-domain, data efficiency, and micro-expression domain, demonstrate AUFormer's state-of-the-art performance and robust generalization abilities without relying on additional relevant data. The code for AUFormer is available at https://github.com/yuankaishen2001/AUFormer.
Read more7/10/2024

0
New!Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Guohong Hu, Xing Lan, Hanyu Jiang, Jiayi Lyu, Jian Xue
Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
Read more9/16/2024

0
Learning Contrastive Feature Representations for Facial Action Unit Detection
Ziqiao Shang, Bin Liu, Fengmao Lv, Fei Teng, Tianrui Li
Facial action unit (AU) detection has long encountered the challenge of detecting subtle feature differences when AUs activate. Existing methods often rely on encoding pixel-level information of AUs, which not only encodes additional redundant information but also leads to increased model complexity and limited generalizability. Additionally, the accuracy of AU detection is negatively impacted by the class imbalance issue of each AU type, and the presence of noisy and false AU labels. In this paper, we introduce a novel contrastive learning framework aimed for AU detection that incorporates both self-supervised and supervised signals, thereby enhancing the learning of discriminative features for accurate AU detection. To tackle the class imbalance issue, we employ a negative sample re-weighting strategy that adjusts the step size of updating parameters for minority and majority class samples. Moreover, to address the challenges posed by noisy and false AU labels, we employ a sampling technique that encompasses three distinct types of positive sample pairs. This enables us to inject self-supervised signals into the supervised signal, effectively mitigating the adverse effects of noisy labels. Our experimental assessments, conducted on four widely-utilized benchmark datasets (BP4D, DISFA, GFT and Aff-Wild2), underscore the superior performance of our approach compared to state-of-the-art methods of AU detection. Our code is available at url{https://github.com/Ziqiao-Shang/AUNCE}.
Read more7/15/2024
0
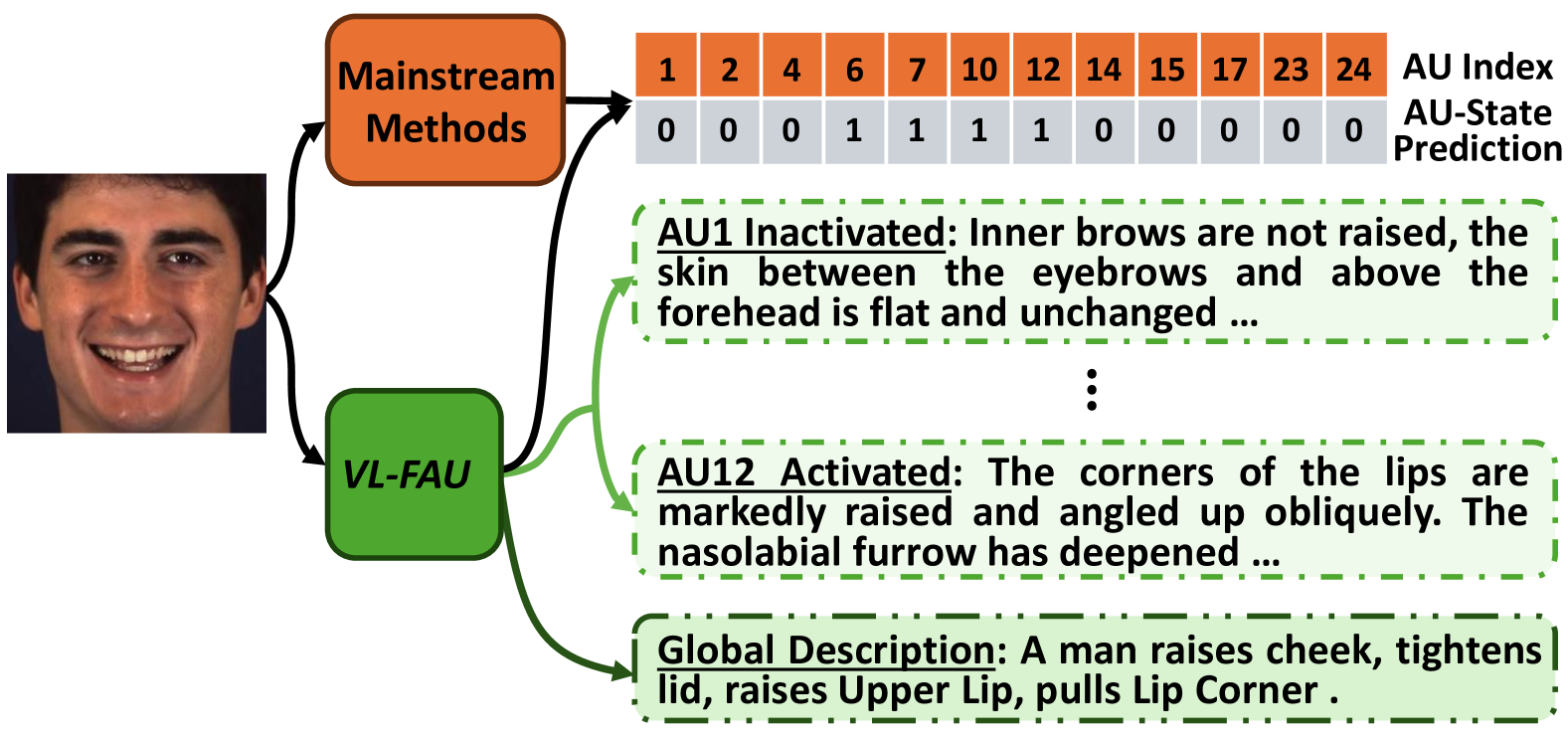
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Xuri Ge, Junchen Fu, Fuhai Chen, Shan An, Nicu Sebe, Joemon M. Jose
Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
Read more8/2/2024