Towards White Box Deep Learning

0

Sign in to get full access
Overview
- Introduces a conceptual framework for "white box" neural networks, where the inner workings of the network are made transparent and interpretable.
- Proposes the idea of "semantic features" that capture high-level, human-understandable concepts within neural network activations.
- Discusses potential applications of this framework in areas like explainable AI, few-shot learning, and neural network analysis.
Plain English Explanation
The paper introduces a new way of thinking about neural networks, where the inner workings of the network are made more transparent and understandable to humans. The key idea is the concept of "semantic features" - these are high-level, human-understandable concepts that the network has learned to recognize, like "dog", "car", or "happy face".
Normally, neural networks are kind of like black boxes - you put data in, get a result out, but it's hard to understand how the network arrived at that result. With this new framework, the authors propose making the network more "white box", where you can peer inside and see the specific concepts the network is using to make its decisions.
This could be really useful in a few different ways. First, it could help with explaining AI systems and making them more transparent and trustworthy. Rather than just getting a classification result, you'd be able to see the specific high-level features the AI is focusing on.
It could also potentially help with few-shot learning - the ability to learn new tasks from just a few examples. If the network has already learned semantic features like "dog" or "chair", it might be able to more quickly learn to recognize new objects by relating them to those familiar concepts.
And finally, this framework could enable new ways of analyzing and understanding neural networks themselves. By looking at the specific semantic features the network has learned, researchers might be able to gain deeper insights into how neural networks work and how they can be improved.
Overall, the core idea is about making neural networks more interpretable and transparent, which could have important implications for making AI systems more reliable, capable, and trustworthy.
Technical Explanation
The paper proposes a conceptual framework for "white box" neural networks, where the internal representations and activations of the network are designed to correspond to high-level, human-understandable "semantic features".
The authors define semantic features as "abstract concepts that can be recognized by a neural network, and that can be described using natural language". Examples might include visual concepts like "dog", "car", or "happy face", or more abstract concepts like "risk", "fairness", or "creativity".
The key insight is that by explicitly training neural networks to learn these semantic features, rather than just optimizing for task performance, the inner workings of the network become more interpretable and transparent. Researchers and users can then inspect the network to see which specific semantic features it is using to make decisions, rather than just observing the input-output mapping as a black box.
The paper discusses several potential applications of this framework, including:
-
Explainable AI: By identifying the semantic features driving a network's outputs, the reasoning behind its decisions can be made more transparent and understandable to human users.
-
Few-shot learning: If a network has already learned general semantic features, it may be able to more quickly learn new tasks by relating novel inputs to those familiar concepts.
-
Neural network analysis: Studying the specific semantic features encoded in a network's representations could provide insights into how neural networks learn and what they are really "thinking" about.
The paper also discusses related work, such as object-based segmentation for semantic features and categorical semantics for knowledge integration, and outlines a research agenda for further developing this conceptual framework.
Critical Analysis
The proposed conceptual framework for "white box" neural networks is an intriguing idea with significant potential, but also raises some important questions and caveats.
One key challenge is the difficulty of defining and identifying appropriate semantic features, especially for more abstract or subjective concepts. The paper acknowledges this, noting that the set of semantic features may need to be task-specific and that there may be multiple valid ways to define them. Developing rigorous and generalizable methods for selecting and validating semantic features will be an important area for further research.
Additionally, training neural networks to explicitly learn semantic features may introduce tradeoffs in terms of model performance or efficiency, compared to purely task-oriented optimization. The paper does not explore these potential downsides in depth, and more empirical evaluation would be needed to understand the practical implications.
Another open question is the extent to which this framework can be applied to large-scale, highly complex neural networks, which often develop internal representations that are difficult for humans to interpret, even with semantic feature extraction. Scaling this approach to state-of-the-art models may require additional innovations.
Finally, while the applications discussed (explainable AI, few-shot learning, network analysis) are compelling, the paper does not provide a detailed roadmap for realizing these benefits. More work is needed to translate the conceptual framework into concrete, implementable techniques.
Overall, the paper presents an intriguing new way of thinking about neural networks that could have significant implications for AI safety, robustness, and interpretability. However, realizing the full potential of this framework will require further research to address the challenges and open questions it raises.
Conclusion
This paper introduces a conceptual framework for "white box" neural networks, where the inner workings of the network are made more interpretable and transparent through the use of high-level, human-understandable "semantic features".
By explicitly training neural networks to learn these semantic features, rather than just optimizing for task performance, the authors argue that the reasoning behind the network's decisions can be better explained and understood. This could have important implications for building more trustworthy and reliable AI systems, as well as enabling new approaches to few-shot learning and neural network analysis.
While the framework presents an intriguing new direction, there are also significant challenges to overcome, such as defining and validating appropriate semantic features, managing potential tradeoffs in model performance, and scaling the approach to large-scale neural networks. Addressing these issues will be an important area for further research.
Overall, this paper offers a thought-provoking perspective on the future of neural network design and interpretation, with the potential to significantly advance the field of explainable and trustworthy AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards White Box Deep Learning
Maciej Satkiewicz
This paper introduces semantic features as a candidate conceptual framework for white-box neural networks. The proof of concept model is well-motivated, inherently interpretable, has low parameter-count and achieves almost human-level adversarial test metrics - with no adversarial training! These results and the general nature of the approach warrant further research on semantic features. The code is available at https://github.com/314-Foundation/white-box-nn
Read more4/16/2024
❗
0
Advancing Ante-Hoc Explainable Models through Generative Adversarial Networks
Tanmay Garg, Deepika Vemuri, Vineeth N Balasubramanian
This paper presents a novel concept learning framework for enhancing model interpretability and performance in visual classification tasks. Our approach appends an unsupervised explanation generator to the primary classifier network and makes use of adversarial training. During training, the explanation module is optimized to extract visual concepts from the classifier's latent representations, while the GAN-based module aims to discriminate images generated from concepts, from true images. This joint training scheme enables the model to implicitly align its internally learned concepts with human-interpretable visual properties. Comprehensive experiments demonstrate the robustness of our approach, while producing coherent concept activations. We analyse the learned concepts, showing their semantic concordance with object parts and visual attributes. We also study how perturbations in the adversarial training protocol impact both classification and concept acquisition. In summary, this work presents a significant step towards building inherently interpretable deep vision models with task-aligned concept representations - a key enabler for developing trustworthy AI for real-world perception tasks.
Read more4/4/2024
0
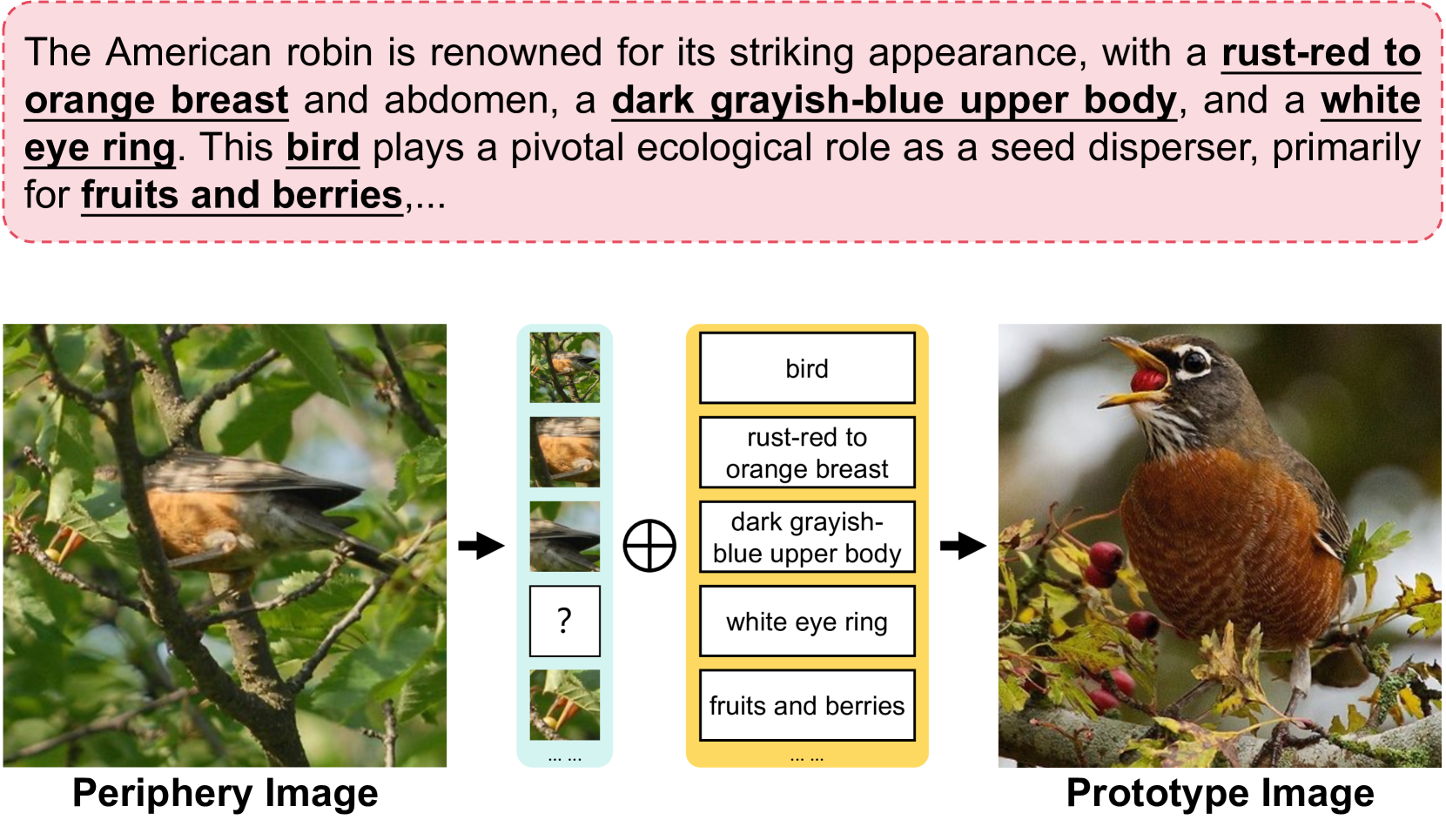
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
Read more4/10/2024
0
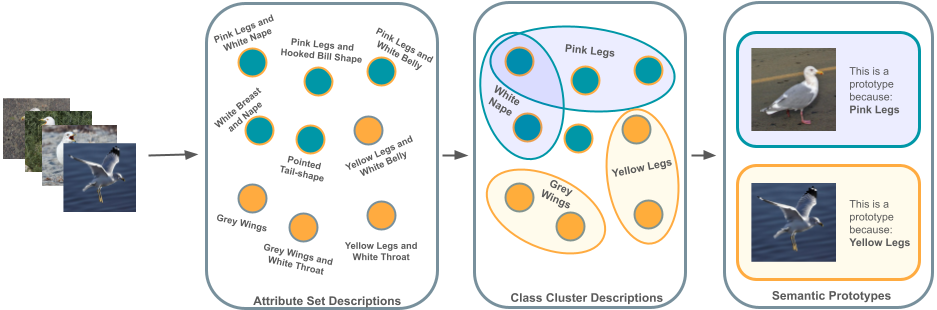
Semantic Prototypes: Enhancing Transparency Without Black Boxes
Orfeas Menis-Mastromichalakis, Giorgos Filandrianos, Jason Liartis, Edmund Dervakos, Giorgos Stamou
As machine learning (ML) models and datasets increase in complexity, the demand for methods that enhance explainability and interpretability becomes paramount. Prototypes, by encapsulating essential characteristics within data, offer insights that enable tactical decision-making and enhance transparency. Traditional prototype methods often rely on sub-symbolic raw data and opaque latent spaces, reducing explainability and increasing the risk of misinterpretations. This paper presents a novel framework that utilizes semantic descriptions to define prototypes and provide clear explanations, effectively addressing the shortcomings of conventional methods. Our approach leverages concept-based descriptions to cluster data on the semantic level, ensuring that prototypes not only represent underlying properties intuitively but are also straightforward to interpret. Our method simplifies the interpretative process and effectively bridges the gap between complex data structures and human cognitive processes, thereby enhancing transparency and fostering trust. Our approach outperforms existing widely-used prototype methods in facilitating human understanding and informativeness, as validated through a user survey.
Read more8/20/2024