TPA3D: Triplane Attention for Fast Text-to-3D Generation

0
🛸
Sign in to get full access
Overview
- Recent text-to-3D generation models rely on 2D diffusion models due to lack of large-scale text-3D data
- Diffusion-based methods are computationally expensive for both training and inference
- Using GAN-based models could enable faster 3D generation
Plain English Explanation
Text-to-3D generation is the process of creating 3D models based on textual descriptions. However, there is a lack of large datasets that connect text descriptions to 3D shapes, which makes this task challenging. Recent approaches have turned to using 2D diffusion models to generate 3D data, but these methods can be very slow during both training and when generating new 3D shapes.
An alternative approach is to use Generative Adversarial Networks (GANs), which can generate 3D shapes more efficiently. In this work, the researchers propose a new GAN-based model called TPA3D that can generate high-quality 3D textured shapes from text descriptions.
The key innovation in TPA3D is the use of attention mechanisms that allow the model to focus on the most relevant parts of the text description when generating the 3D shape. This helps the model capture fine-grained details from the text and translate them into the 3D output. The researchers show that TPA3D can generate 3D shapes faster than previous diffusion-based approaches while maintaining high quality.
Technical Explanation
The TPA3D model is an end-to-end trainable Generative Adversarial Network (GAN) that takes text descriptions as input and generates corresponding 3D textured shapes as output.
The key components of the TPA3D architecture are:
- Text Encoder: Encodes the input text description into sentence-level and word-level features.
- Triplane Attention: Applies attention mechanisms to the text features to selectively focus on the most relevant parts when generating the 3D shape.
- 3D Generator: Takes the attended text features and generates a 3D textured shape.
- Discriminator: Discriminates between real and generated 3D shapes to provide feedback to the generator during training.
During training, the model observes 3D shapes and their corresponding 2D rendered images, but not the direct text-3D correspondences. The attention mechanisms allow the model to learn these associations from the available data.
The researchers show that TPA3D can generate high-quality 3D shapes that closely match the input text descriptions, while being significantly more efficient than previous diffusion-based approaches.
Critical Analysis
The authors acknowledge that the lack of large-scale text-3D correspondence data is a key challenge in this field. While they show that TPA3D can generate 3D shapes from text without direct text-3D supervision, the quality and fidelity of the generated shapes may be limited by the available data.
Additionally, the paper does not provide a detailed analysis of the types of text descriptions the model can handle or the limitations in the generated 3D shapes. It would be valuable to understand the model's performance on a wider range of text prompts and the types of errors or artifacts that may occur.
Further research could explore techniques to augment or synthesize additional text-3D paired data to improve the model's capabilities. Investigating ways to better incorporate 3D shape priors and constraints could also lead to more realistic and coherent 3D generation.
Conclusion
The TPA3D model presents a promising approach for fast and efficient text-to-3D generation using Generative Adversarial Networks (GANs). By leveraging attention mechanisms to selectively focus on relevant parts of the text descriptions, the model can generate high-quality 3D textured shapes that closely align with the input prompts.
This work demonstrates the potential of GAN-based models to enable more accessible and user-friendly 3D content creation, with applications in areas such as virtual environments, gaming, and product design. As the field of text-to-3D generation continues to evolve, further advancements in data, architectures, and training techniques could lead to even more impressive and versatile 3D generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
TPA3D: Triplane Attention for Fast Text-to-3D Generation
Bin-Shih Wu, Hong-En Chen, Sheng-Yu Huang, Yu-Chiang Frank Wang
Due to the lack of large-scale text-3D correspondence data, recent text-to-3D generation works mainly rely on utilizing 2D diffusion models for synthesizing 3D data. Since diffusion-based methods typically require significant optimization time for both training and inference, the use of GAN-based models would still be desirable for fast 3D generation. In this work, we propose Triplane Attention for text-guided 3D generation (TPA3D), an end-to-end trainable GAN-based deep learning model for fast text-to-3D generation. With only 3D shape data and their rendered 2D images observed during training, our TPA3D is designed to retrieve detailed visual descriptions for synthesizing the corresponding 3D mesh data. This is achieved by the proposed attention mechanisms on the extracted sentence and word-level text features. In our experiments, we show that TPA3D generates high-quality 3D textured shapes aligned with fine-grained descriptions, while impressive computation efficiency can be observed.
Read more9/10/2024
🛸
0
Instant3D: Instant Text-to-3D Generation
Ming Li, Pan Zhou, Jia-Wei Liu, Jussi Keppo, Min Lin, Shuicheng Yan, Xiangyu Xu
Text-to-3D generation has attracted much attention from the computer vision community. Existing methods mainly optimize a neural field from scratch for each text prompt, relying on heavy and repetitive training cost which impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. In particular, we propose to combine three key mechanisms: cross-attention, style injection, and token-to-plane transformation, which collectively ensure precise alignment of the output with the input text. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The code, data, and models are available at https://github.com/ming1993li/Instant3DCodes.
Read more4/30/2024

0
PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Ying-Tian Liu, Yuan-Chen Guo, Guan Luo, Heyi Sun, Wei Yin, Song-Hai Zhang
Diffusion models trained on large-scale text-image datasets have demonstrated a strong capability of controllable high-quality image generation from arbitrary text prompts. However, the generation quality and generalization ability of 3D diffusion models is hindered by the scarcity of high-quality and large-scale 3D datasets. In this paper, we present PI3D, a framework that fully leverages the pre-trained text-to-image diffusion models' ability to generate high-quality 3D shapes from text prompts in minutes. The core idea is to connect the 2D and 3D domains by representing a 3D shape as a set of Pseudo RGB Images. We fine-tune an existing text-to-image diffusion model to produce such pseudo-images using a small number of text-3D pairs. Surprisingly, we find that it can already generate meaningful and consistent 3D shapes given complex text descriptions. We further take the generated shapes as the starting point for a lightweight iterative refinement using score distillation sampling to achieve high-quality generation under a low budget. PI3D generates a single 3D shape from text in only 3 minutes and the quality is validated to outperform existing 3D generative models by a large margin.
Read more4/23/2024
0
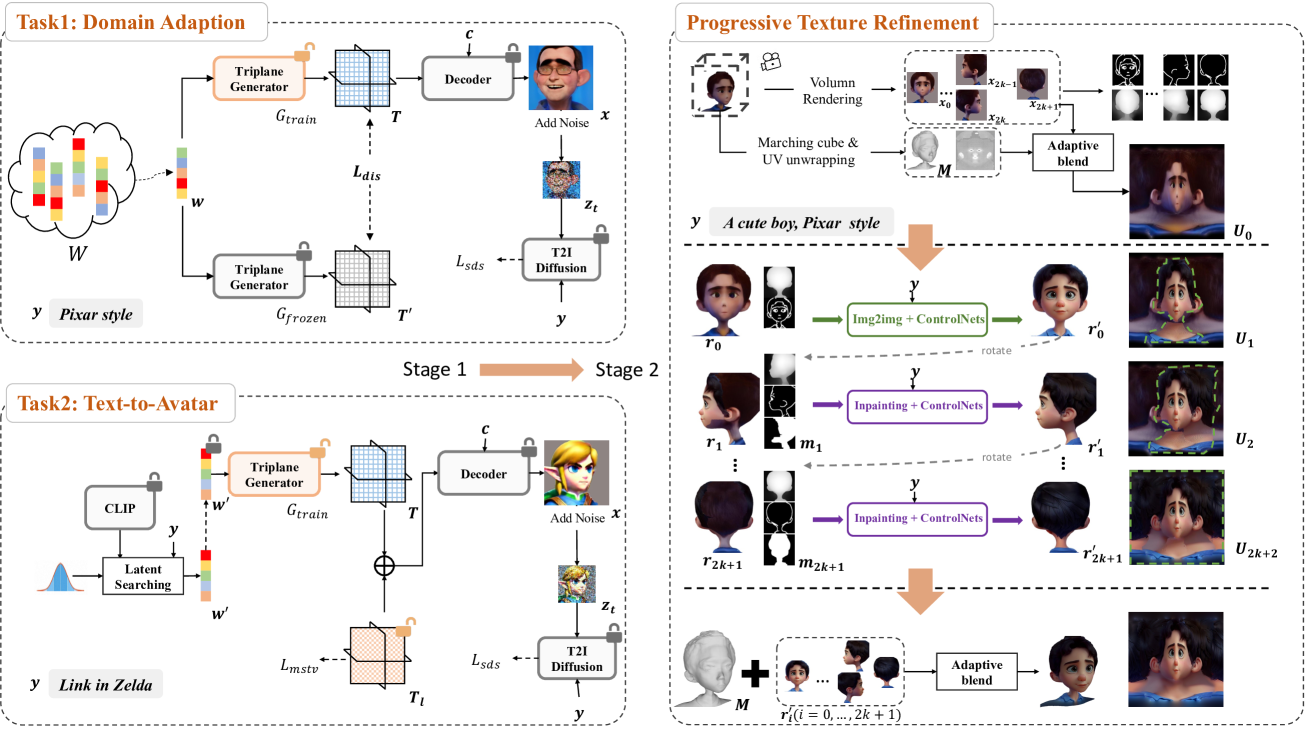
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
Read more4/15/2024