Track Anything Rapter(TAR)

0

Sign in to get full access
Overview
- Proposed a novel object tracking system called Track Anything Rapter (TAR)
- TAR can track any object in a video using a single click
- TAR is an end-to-end trainable model that combines visual and language understanding
Plain English Explanation
TAR is a new technology that makes it easy to track objects in videos. With just a single click, TAR can identify and follow any object of interest as it moves through the video. This is possible because TAR combines visual information from the video with language understanding to understand what the user wants to track.
Rather than requiring users to manually draw bounding boxes around an object or provide detailed descriptions, TAR can infer the user's intent from a simple click. This makes the tracking process much more intuitive and efficient. The paper on TAR describes how the system works and demonstrates its capabilities on a variety of tracking tasks.
Technical Explanation
The TAR system uses an end-to-end neural network architecture that takes in the video frames and a user click as input, and outputs the location of the tracked object in each frame. The network consists of a visual encoder that processes the video, a language encoder that understands the user's click, and a cross-attention module that combines these two modalities to predict the object's position.
By jointly learning to understand the visual information and the user's intent, TAR is able to track a wide range of objects with high accuracy, even in challenging scenarios like occlusion or background clutter. The authors demonstrate TAR's capabilities on several benchmarks, showing that it outperforms previous state-of-the-art tracking methods.
Critical Analysis
The TAR paper presents a promising approach to object tracking that leverages both visual and language understanding. The single-click interface is a notable improvement over traditional tracking methods that require more manual input.
However, the paper does not fully address the potential limitations of the system. For example, it's unclear how TAR would perform on highly deformable objects or in videos with rapid camera motion. Additionally, the training and inference times of the model are not reported, which could be an important practical consideration.
Further research could also explore ways to make TAR more robust to noisy or ambiguous user clicks, and to extend the system to support other types of user input beyond just clicks.
Conclusion
The TAR system represents an exciting step forward in object tracking technology. By combining visual and language understanding, TAR enables a simple and intuitive way for users to track objects of interest in videos. The strong performance demonstrated in the paper suggests that this approach could have a significant impact in a wide range of applications, from video analysis to autonomous systems. As the technology continues to evolve, it will be interesting to see how TAR and similar systems can be further refined and deployed in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Track Anything Rapter(TAR)
Tharun V. Puthanveettil, Fnu Obaid ur Rahman
Object tracking is a fundamental task in computer vision with broad practical applications across various domains, including traffic monitoring, robotics, and autonomous vehicle tracking. In this project, we aim to develop a sophisticated aerial vehicle system known as Track Anything Rapter (TAR), designed to detect, segment, and track objects of interest based on user-provided multimodal queries, such as text, images, and clicks. TAR utilizes cutting-edge pre-trained models like DINO, CLIP, and SAM to estimate the relative pose of the queried object. The tracking problem is approached as a Visual Servoing task, enabling the UAV to consistently focus on the object through advanced motion planning and control algorithms. We showcase how the integration of these foundational models with a custom high-level control algorithm results in a highly stable and precise tracking system deployed on a custom-built PX4 Autopilot-enabled Voxl2 M500 drone. To validate the tracking algorithm's performance, we compare it against Vicon-based ground truth. Additionally, we evaluate the reliability of the foundational models in aiding tracking in scenarios involving occlusions. Finally, we test and validate the model's ability to work seamlessly with multiple modalities, such as click, bounding box, and image templates.
Read more5/30/2024
🚀
0
CloudTrack: Scalable UAV Tracking with Cloud Semantics
Yannik Blei, Michael Krawez, Nisarga Nilavadi, Tanja Katharina Kaiser, Wolfram Burgard
Nowadays, unmanned aerial vehicles (UAVs) are commonly used in search and rescue scenarios to gather information in the search area. The automatic identification of the person searched for in aerial footage could increase the autonomy of such systems, reduce the search time, and thus increase the missed person's chances of survival. In this paper, we present a novel approach to perform semantically conditioned open vocabulary object tracking that is specifically designed to cope with the limitations of UAV hardware. Our approach has several advantages. It can run with verbal descriptions of the missing person, e.g., the color of the shirt, it does not require dedicated training to execute the mission and can efficiently track a potentially moving person. Our experimental results demonstrate the versatility and efficacy of our approach.
Read more9/25/2024
🔄
0
D-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles
Alberto Dionigi, Simone Felicioni, Mirko Leomanni, Gabriele Costante
Visual active tracking is a growing research topic in robotics due to its key role in applications such as human assistance, disaster recovery, and surveillance. In contrast to passive tracking, active tracking approaches combine vision and control capabilities to detect and actively track the target. Most of the work in this area focuses on ground robots, while the very few contributions on aerial platforms still pose important design constraints that limit their applicability. To overcome these limitations, in this paper we propose D-VAT, a novel end-to-end visual active tracking methodology based on deep reinforcement learning that is tailored to micro aerial vehicle platforms. The D-VAT agent computes the vehicle thrust and angular velocity commands needed to track the target by directly processing monocular camera measurements. We show that the proposed approach allows for precise and collision-free tracking operations, outperforming different state-of-the-art baselines on simulated environments which differ significantly from those encountered during training. Moreover, we demonstrate a smooth real-world transition to a quadrotor platform with mixed-reality.
Read more4/9/2024
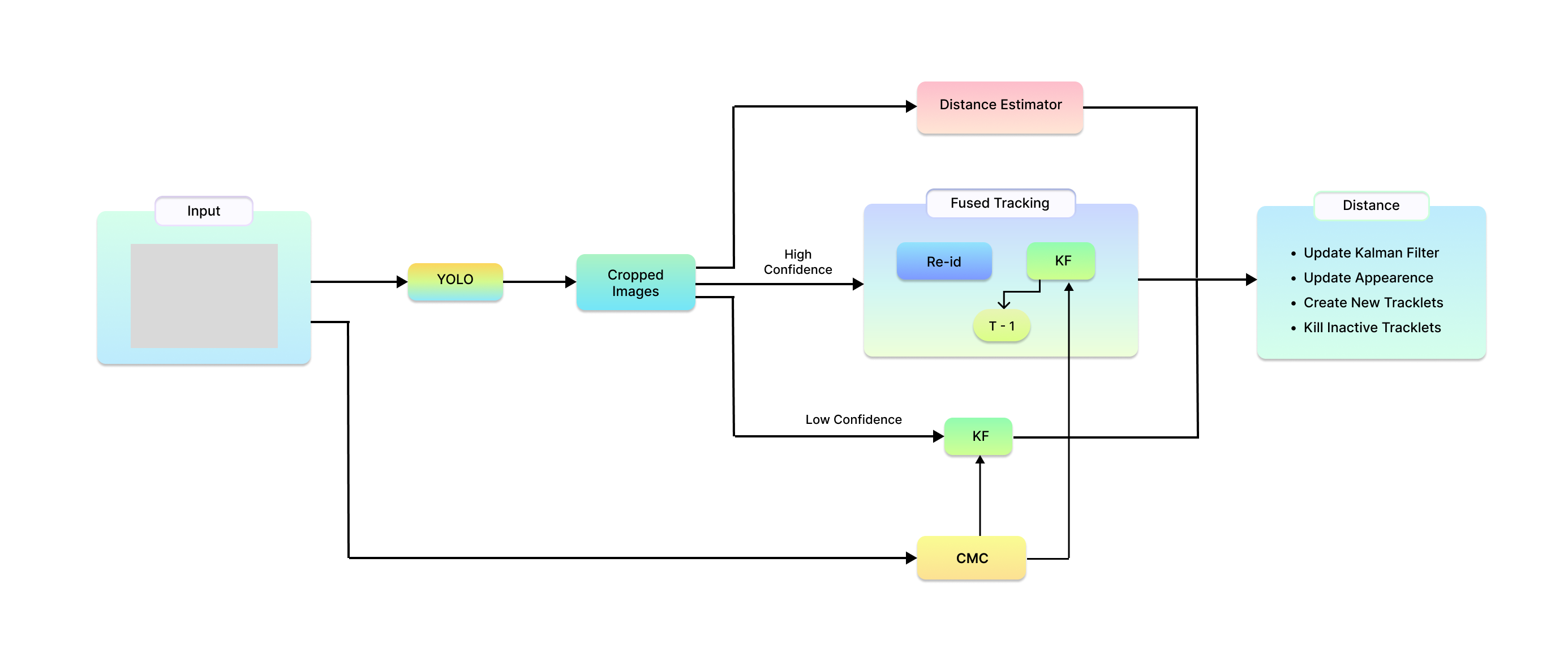
0
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
Vasileios Karampinis, Anastasios Arsenos, Orfeas Filippopoulos, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
Read more5/17/2024