D-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles
2308.16874
0
0
🔄
Abstract
Visual active tracking is a growing research topic in robotics due to its key role in applications such as human assistance, disaster recovery, and surveillance. In contrast to passive tracking, active tracking approaches combine vision and control capabilities to detect and actively track the target. Most of the work in this area focuses on ground robots, while the very few contributions on aerial platforms still pose important design constraints that limit their applicability. To overcome these limitations, in this paper we propose D-VAT, a novel end-to-end visual active tracking methodology based on deep reinforcement learning that is tailored to micro aerial vehicle platforms. The D-VAT agent computes the vehicle thrust and angular velocity commands needed to track the target by directly processing monocular camera measurements. We show that the proposed approach allows for precise and collision-free tracking operations, outperforming different state-of-the-art baselines on simulated environments which differ significantly from those encountered during training. Moreover, we demonstrate a smooth real-world transition to a quadrotor platform with mixed-reality.
Create account to get full access
Overview
- Visual active tracking is a growing research topic in robotics for applications like human assistance, disaster recovery, and surveillance.
- Unlike passive tracking, active tracking combines vision and control to detect and track targets.
- Most work focuses on ground robots, while aerial platforms face design constraints.
- This paper proposes a novel deep reinforcement learning approach called D-VAT for visual active tracking on micro aerial vehicles.
Plain English Explanation
The paper describes a new method called D-VAT that allows small flying robots, like drones, to automatically track and follow moving targets using only a camera. This builds on previous research in the field of ,[object Object], which combines computer vision and robot control to actively track and pursue targets, rather than just passively observing them.
Most existing work on visual active tracking has focused on ground robots, while aerial platforms like drones have faced more technical challenges. D-VAT aims to overcome these challenges by using a deep learning approach to directly translate camera images into the flight commands needed to track a target. This allows the drone to autonomously adjust its position and trajectory to keep the target in view without colliding with obstacles.
The researchers show that D-VAT outperforms other state-of-the-art methods, not just in the simulated environments it was trained on, but also when tested in very different real-world scenarios. They also demonstrate that the system can be smoothly transferred from simulation to a real quadrotor platform, blending virtual and physical environments. This builds on other recent advancements in areas like ,[object Object], for fast UAVs and secure area-of-interest aware control for drone swarms.
Technical Explanation
The D-VAT approach uses a deep reinforcement learning agent to directly map monocular camera images to the thrust and angular velocity commands needed to track a target. This end-to-end architecture avoids the need for explicit object detection, tracking, and control components.
The agent is trained in simulation environments that vary in terms of target motion, obstacles, and other factors. The researchers show that D-VAT can generalize well to new scenarios, outperforming baseline methods not just in the training environments, but also in significantly different test settings.
To enable real-world deployment, the researchers demonstrate a smooth transition from simulation to a physical quadrotor platform, leveraging mixed-reality techniques that blend virtual and physical elements. This allows the D-VAT agent to be evaluated in a safe and controlled manner before being deployed on actual hardware.
Critical Analysis
The paper presents a promising approach for visual active tracking on micro aerial vehicles, but it also acknowledges several limitations and avenues for future work.
One key constraint is that the current implementation assumes the target is always visible to the drone's camera. In real-world scenarios, the target may become occluded by obstacles or leave the camera's field of view. Addressing these challenges could draw inspiration from advances in areas like ,[object Object] to complement vision-based tracking.
Additionally, the real-world experiments were conducted in a semi-structured indoor environment. Scaling the approach to more complex outdoor scenarios with greater uncertainty and dynamics may require further innovations in areas like [object Object].
Overall, the D-VAT method represents a promising step forward in the field of visual active tracking for micro aerial vehicles. By leveraging deep reinforcement learning, the authors have demonstrated an effective way to tackle this challenging problem. However, continued research will be needed to address the remaining constraints and expand the capabilities of these systems.
Conclusion
This paper introduces a novel deep reinforcement learning-based approach called D-VAT for visual active tracking on micro aerial vehicles. By directly mapping camera images to flight controls, D-VAT can autonomously track moving targets while avoiding obstacles, outperforming existing methods.
The researchers demonstrate D-VAT's ability to generalize beyond the training environments and smoothly transition to real-world quadrotor platforms using mixed-reality techniques. While some limitations remain, this work represents an important advancement in the field of visual active tracking and its applications in areas like human assistance, disaster recovery, and surveillance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
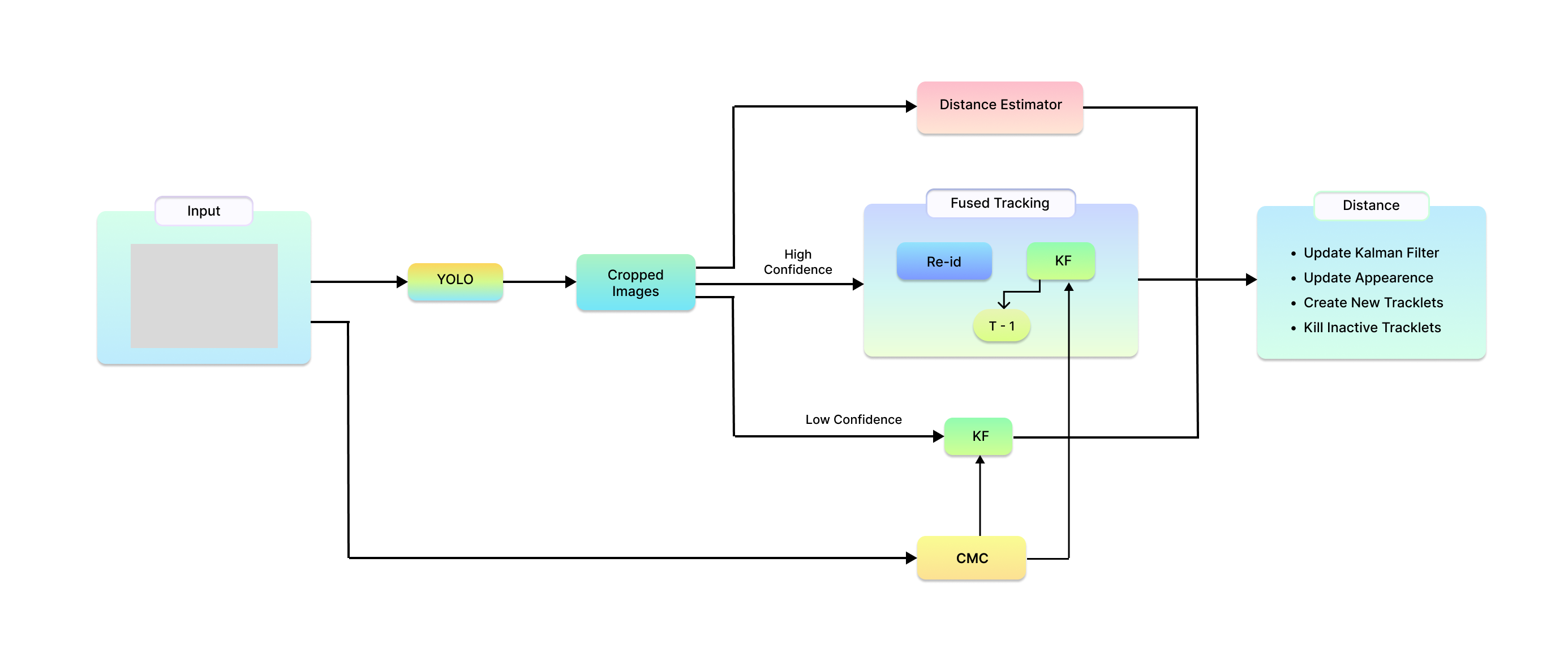
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
Vasileios Karampinis, Anastasios Arsenos, Orfeas Filippopoulos, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
0
0
In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
5/17/2024

Active Visual Localization for Multi-Agent Collaboration: A Data-Driven Approach
Matthew Hanlon, Boyang Sun, Marc Pollefeys, Hermann Blum
0
0
Rather than having each newly deployed robot create its own map of its surroundings, the growing availability of SLAM-enabled devices provides the option of simply localizing in a map of another robot or device. In cases such as multi-robot or human-robot collaboration, localizing all agents in the same map is even necessary. However, localizing e.g. a ground robot in the map of a drone or head-mounted MR headset presents unique challenges due to viewpoint changes. This work investigates how active visual localization can be used to overcome such challenges of viewpoint changes. Specifically, we focus on the problem of selecting the optimal viewpoint at a given location. We compare existing approaches in the literature with additional proposed baselines and propose a novel data-driven approach. The result demonstrates the superior performance of the data-driven approach when compared to existing methods, both in controlled simulation experiments and real-world deployment.
5/10/2024

Track Anything Rapter(TAR)
Tharun V. Puthanveettil, Fnu Obaid ur Rahman
0
0
Object tracking is a fundamental task in computer vision with broad practical applications across various domains, including traffic monitoring, robotics, and autonomous vehicle tracking. In this project, we aim to develop a sophisticated aerial vehicle system known as Track Anything Rapter (TAR), designed to detect, segment, and track objects of interest based on user-provided multimodal queries, such as text, images, and clicks. TAR utilizes cutting-edge pre-trained models like DINO, CLIP, and SAM to estimate the relative pose of the queried object. The tracking problem is approached as a Visual Servoing task, enabling the UAV to consistently focus on the object through advanced motion planning and control algorithms. We showcase how the integration of these foundational models with a custom high-level control algorithm results in a highly stable and precise tracking system deployed on a custom-built PX4 Autopilot-enabled Voxl2 M500 drone. To validate the tracking algorithm's performance, we compare it against Vicon-based ground truth. Additionally, we evaluate the reliability of the foundational models in aiding tracking in scenarios involving occlusions. Finally, we test and validate the model's ability to work seamlessly with multiple modalities, such as click, bounding box, and image templates.
5/30/2024

Vision Transformers for End-to-End Vision-Based Quadrotor Obstacle Avoidance
Anish Bhattacharya, Nishanth Rao, Dhruv Parikh, Pratik Kunapuli, Nikolai Matni, Vijay Kumar
0
0
We demonstrate the capabilities of an attention-based end-to-end approach for high-speed quadrotor obstacle avoidance in dense, cluttered environments, with comparison to various state-of-the-art architectures. Quadrotor unmanned aerial vehicles (UAVs) have tremendous maneuverability when flown fast; however, as flight speed increases, traditional vision-based navigation via independent mapping, planning, and control modules breaks down due to increased sensor noise, compounding errors, and increased processing latency. Thus, learning-based, end-to-end planning and control networks have shown to be effective for online control of these fast robots through cluttered environments. We train and compare convolutional, U-Net, and recurrent architectures against vision transformer models for depth-based end-to-end control, in a photorealistic, high-physics-fidelity simulator as well as in hardware, and observe that the attention-based models are more effective as quadrotor speeds increase, while recurrent models with many layers provide smoother commands at lower speeds. To the best of our knowledge, this is the first work to utilize vision transformers for end-to-end vision-based quadrotor control.
5/20/2024