Training-Free Action Recognition and Goal Inference with Dynamic Frame Selection

0
Sign in to get full access
Overview
- This paper explores a novel approach for open-ended video understanding using large language models.
- The key idea is to leverage the rich knowledge and capabilities of these language models to enable zero-shot video inference, where models can understand and describe video content without being explicitly trained on that data.
- The paper presents a detailed technical implementation and evaluation, showcasing promising results for this zero-shot video understanding paradigm.
Plain English Explanation
The paper looks at a new way to understand videos using large language models - powerful AI systems that have been trained on massive amounts of text data. The key insight is that these language models have developed a deep understanding of the world that can be leveraged to make sense of video content, even if the model has never seen that specific video before.
The researchers developed a system that takes a video as input and uses a large language model to generate natural language descriptions of what's happening in the video. This "zero-shot" approach means the model doesn't need to be explicitly trained on the video data itself - it can use its general knowledge to figure out what's going on.
For example, if shown a video of someone cooking, the language model might describe the scene by saying "A person is standing at a stove, stirring a pot on the burner. They appear to be preparing a meal by chopping vegetables and adding them to the pot." The model is able to understand and describe the video content without needing to be trained on cooking videos beforehand.
The paper presents a technical implementation of this zero-shot video understanding approach and evaluates its performance on various video understanding tasks. The results suggest this is a promising direction for making AI systems that can flexibly understand video content, without the need for extensive training on specific datasets.
Technical Explanation
The paper proposes a novel approach for zero-shot open-ended video understanding using large language models. The key idea is to leverage the rich knowledge and capabilities of these powerful AI systems, which have been trained on vast amounts of textual data, to enable flexible understanding of video content.
The core technical implementation involves using a large language model as the backbone for video understanding. The model takes a video as input and generates natural language descriptions of the video content. Importantly, the language model is not explicitly trained on the target video data - it uses its general world knowledge to make sense of the video in a "zero-shot" fashion.
The paper evaluates this approach on a range of video understanding tasks, including action recognition, video captioning, and open-ended video question answering. The results demonstrate that the zero-shot language model-based approach can achieve strong performance, often rivaling or even surpassing specialized models that are trained directly on the target video datasets.
A key strength of this approach is its flexibility and generalizability. Because the language model is not constrained to a specific set of video concepts or tasks, it can be applied to a wide variety of video understanding problems, including fine-grained knowledge graph-driven video understanding and dynamic consistent video generation. This opens up new possibilities for building more versatile and adaptable video AI systems.
Critical Analysis
The paper presents a compelling and well-executed exploration of zero-shot video understanding using large language models. One potential limitation, as acknowledged by the authors, is that the performance of the approach is still somewhat dependent on the specific language model used and its training data. Exploring ways to further improve the generalization and robustness of the language model-based video understanding would be an interesting area for future research.
Additionally, while the paper showcases strong results on standard video understanding benchmarks, it would be valuable to see how the approach fares on more real-world, open-ended video understanding tasks that require deeper reasoning and commonsense understanding. Expanding the evaluation to more challenging and diverse video scenarios could help further stress test the capabilities and limitations of this zero-shot approach.
Overall, this work represents an important step towards more flexible and generalizable video AI systems. By harnessing the power of large language models, the researchers have demonstrated a promising path forward for advancing the state of the art in video understanding beyond the constraints of traditional, dataset-specific models.
Conclusion
This paper presents a novel approach for zero-shot open-ended video understanding using large language models. By leveraging the rich knowledge and capabilities of these powerful AI systems, the researchers have developed a flexible video understanding framework that can make sense of video content without requiring explicit training on that data.
The technical implementation and evaluation showcased in the paper suggest this is a promising direction for building more versatile and adaptable video AI systems. As language models continue to advance and expand their understanding of the world, the potential for zero-shot video understanding to enable new applications and use cases in areas like video captioning and video question answering is quite exciting.
Overall, this work represents an important step forward in the field of video AI, paving the way for more flexible and generalizable approaches to understanding the rich and complex visual world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training-Free Action Recognition and Goal Inference with Dynamic Frame Selection
Ee Yeo Keat, Zhang Hao, Alexander Matyasko, Basura Fernando
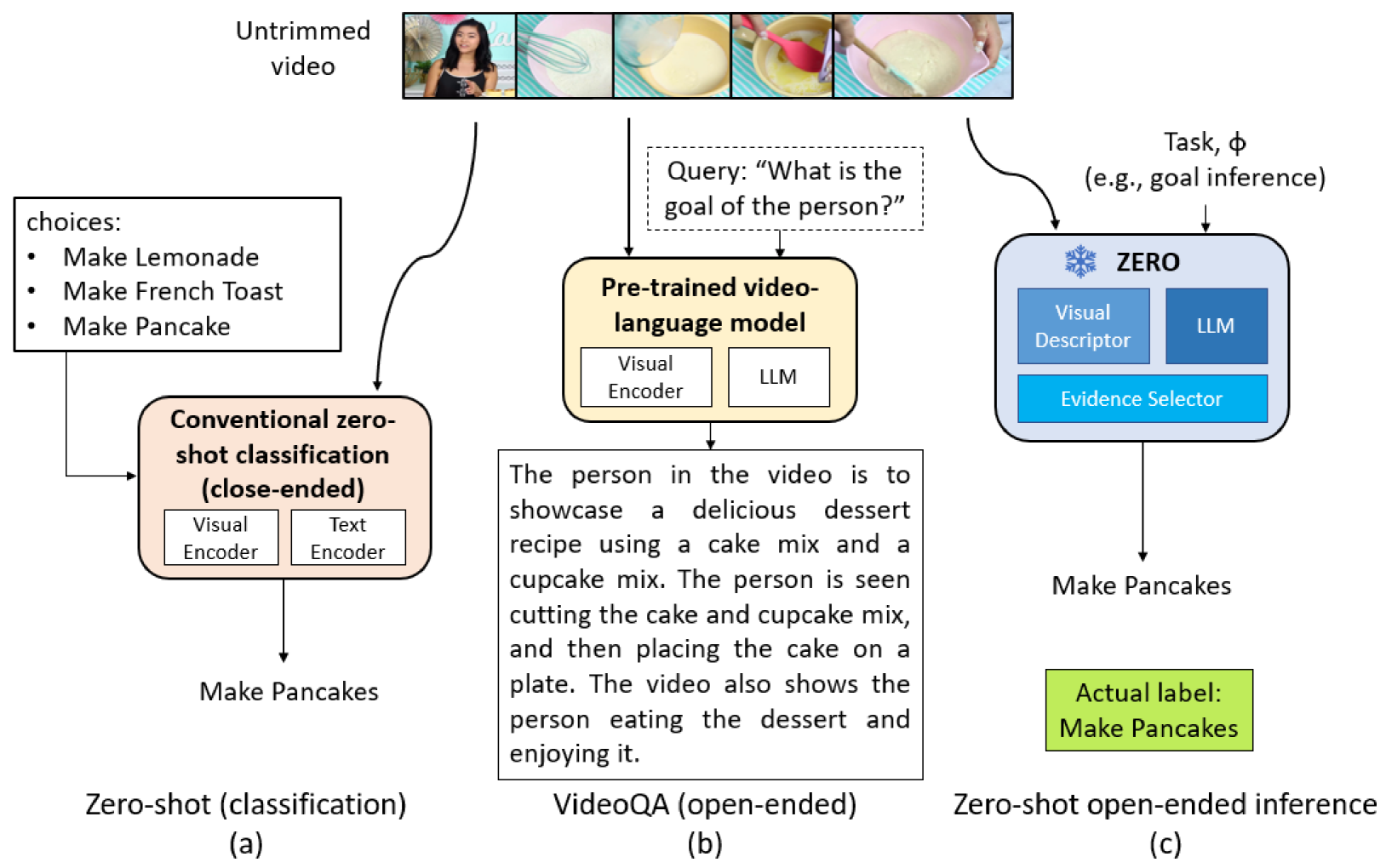
We introduce VidTFS, a Training-free, open-vocabulary video goal and action inference framework that combines the frozen vision foundational model (VFM) and large language model (LLM) with a novel dynamic Frame Selection module. Our experiments demonstrate that the proposed frame selection module improves the performance of the framework significantly. We validate the performance of the proposed VidTFS on four widely used video datasets, including CrossTask, COIN, UCF101, and ActivityNet, covering goal inference and action recognition tasks under open-vocabulary settings without requiring any training or fine-tuning. The results show that VidTFS outperforms pretrained and instruction-tuned multimodal language models that directly stack LLM and VFM for downstream video inference tasks. Our VidTFS with its adaptability shows the future potential for generalizing to new training-free video inference tasks.
Read more8/29/2024

0
Training-free Video Temporal Grounding using Large-scale Pre-trained Models
Minghang Zheng, Xinhao Cai, Qingchao Chen, Yuxin Peng, Yang Liu
Video temporal grounding aims to identify video segments within untrimmed videos that are most relevant to a given natural language query. Existing video temporal localization models rely on specific datasets for training and have high data collection costs, but they exhibit poor generalization capability under the across-dataset and out-of-distribution (OOD) settings. In this paper, we propose a Training-Free Video Temporal Grounding (TFVTG) approach that leverages the ability of pre-trained large models. A naive baseline is to enumerate proposals in the video and use the pre-trained visual language models (VLMs) to select the best proposal according to the vision-language alignment. However, most existing VLMs are trained on image-text pairs or trimmed video clip-text pairs, making it struggle to (1) grasp the relationship and distinguish the temporal boundaries of multiple events within the same video; (2) comprehend and be sensitive to the dynamic transition of events (the transition from one event to another) in the video. To address these issues, we propose leveraging large language models (LLMs) to analyze multiple sub-events contained in the query text and analyze the temporal order and relationships between these events. Secondly, we split a sub-event into dynamic transition and static status parts and propose the dynamic and static scoring functions using VLMs to better evaluate the relevance between the event and the description. Finally, for each sub-event description, we use VLMs to locate the top-k proposals and leverage the order and relationships between sub-events provided by LLMs to filter and integrate these proposals. Our method achieves the best performance on zero-shot video temporal grounding on Charades-STA and ActivityNet Captions datasets without any training and demonstrates better generalization capabilities in cross-dataset and OOD settings.
Read more8/30/2024

0
Open-vocabulary Temporal Action Localization using VLMs
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
Video action localization aims to find timings of a specific action from a long video. Although existing learning-based approaches have been successful, those require annotating videos that come with a considerable labor cost. This paper proposes a learning-free, open-vocabulary approach based on emerging off-the-shelf vision-language models (VLM). The challenge stems from the fact that VLMs are neither designed to process long videos nor tailored for finding actions. We overcome these problems by extending an iterative visual prompting technique. Specifically, we sample video frames into a concatenated image with frame index labels, making a VLM guess a frame that is considered to be closest to the start/end of the action. Iterating this process by narrowing a sampling time window results in finding a specific frame of start and end of an action. We demonstrate that this sampling technique yields reasonable results, illustrating a practical extension of VLMs for understanding videos. A sample code is available at https://microsoft.github.io/VLM-Video-Action-Localization/.
Read more9/10/2024

0
Frame Order Matters: A Temporal Sequence-Aware Model for Few-Shot Action Recognition
Bozheng Li, Mushui Liu, Gaoang Wang, Yunlong Yu
In this paper, we propose a novel Temporal Sequence-Aware Model (TSAM) for few-shot action recognition (FSAR), which incorporates a sequential perceiver adapter into the pre-training framework, to integrate both the spatial information and the sequential temporal dynamics into the feature embeddings. Different from the existing fine-tuning approaches that capture temporal information by exploring the relationships among all the frames, our perceiver-based adapter recurrently captures the sequential dynamics alongside the timeline, which could perceive the order change. To obtain the discriminative representations for each class, we extend a textual corpus for each class derived from the large language models (LLMs) and enrich the visual prototypes by integrating the contextual semantic information. Besides, We introduce an unbalanced optimal transport strategy for feature matching that mitigates the impact of class-unrelated features, thereby facilitating more effective decision-making. Experimental results on five FSAR datasets demonstrate that our method set a new benchmark, beating the second-best competitors with large margins.
Read more8/23/2024