Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
2406.05955
11
0
Abstract
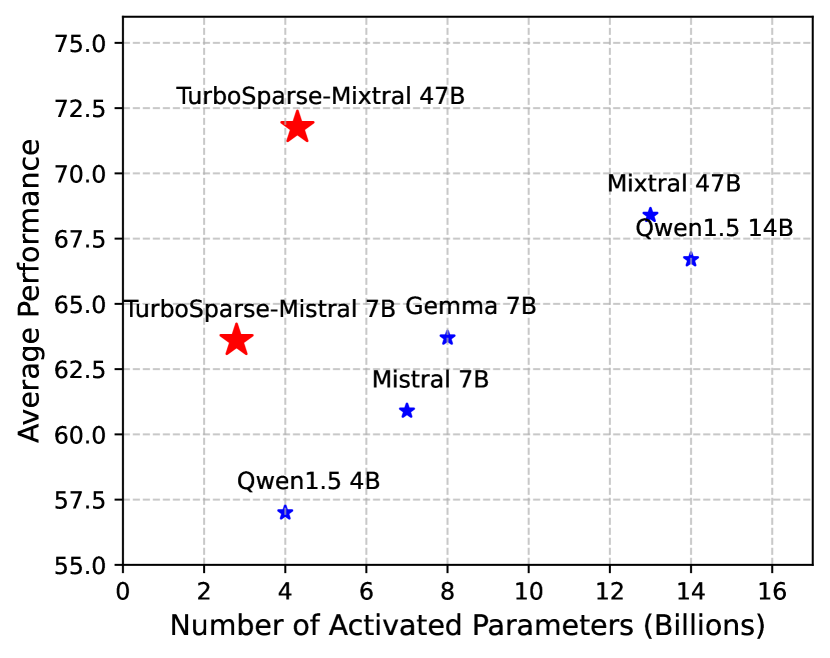
Exploiting activation sparsity is a promising approach to significantly accelerating the inference process of large language models (LLMs) without compromising performance. However, activation sparsity is determined by activation functions, and commonly used ones like SwiGLU and GeGLU exhibit limited sparsity. Simply replacing these functions with ReLU fails to achieve sufficient sparsity. Moreover, inadequate training data can further increase the risk of performance degradation. To address these challenges, we propose a novel dReLU function, which is designed to improve LLM activation sparsity, along with a high-quality training data mixture ratio to facilitate effective sparsification. Additionally, we leverage sparse activation patterns within the Feed-Forward Network (FFN) experts of Mixture-of-Experts (MoE) models to further boost efficiency. By applying our neuron sparsification method to the Mistral and Mixtral models, only 2.5 billion and 4.3 billion parameters are activated per inference iteration, respectively, while achieving even more powerful model performance. Evaluation results demonstrate that this sparsity achieves a 2-5x decoding speedup. Remarkably, on mobile phones, our TurboSparse-Mixtral-47B achieves an inference speed of 11 tokens per second. Our models are available at url{https://huggingface.co/PowerInfer}
Create account to get full access
Overview
- This paper introduces "Turbo Sparse", a technique to achieve state-of-the-art performance on large language models (LLMs) while using minimal activated parameters.
- Turbo Sparse leverages sparse attention and sparse feed-forward layers to dramatically reduce the number of parameters required, without sacrificing model performance.
- The authors demonstrate Turbo Sparse's effectiveness on a range of benchmark tasks, showing it can match or exceed the performance of dense LLMs while using 10x fewer activated parameters.
Plain English Explanation
The paper describes a new method called "Turbo Sparse" that allows large language models (LLMs) to achieve top-notch performance while only using a small fraction of their total parameters. LLMs are powerful AI systems that can generate human-like text, answer questions, and perform other language-related tasks. However, these models often have billions of parameters, making them computationally expensive and resource-intensive to run.
Turbo Sparse tackles this issue by introducing "sparse" attention and feed-forward layers. Normally, LLMs use all of their parameters to process each input. But with Turbo Sparse, only a small subset of the parameters are activated and used for a given input. This dramatically reduces the computational load without significantly impacting the model's capabilities.
The paper demonstrates that Turbo Sparse can match or even outperform traditional dense LLMs on a variety of benchmark tasks, all while using 10 times fewer activated parameters. This makes Turbo Sparse a promising approach for deploying high-performance language models on resource-constrained devices or in low-power settings.
Technical Explanation
The key innovation in Turbo Sparse is the use of sparse attention and sparse feed-forward layers. Attention is a crucial component of LLMs that allows the model to focus on the most relevant parts of the input when generating output. In a traditional dense attention layer, all input elements are considered when computing the attention weights.
Turbo Sparse instead uses a sparse attention mechanism, where each output element only attends to a small subset of the input elements. This is achieved through a learnable sparse attention pattern that is optimized during training. Similarly, the feed-forward layers in Turbo Sparse use sparse weight matrices, where most of the weights are set to zero.
The authors show that these sparse layers can be trained end-to-end using standard techniques, and they demonstrate Turbo Sparse's effectiveness on a range of language modeling and text generation tasks. Compared to dense LLMs, Turbo Sparse models achieve similar or better performance while using 10x fewer activated parameters.
Critical Analysis
The Turbo Sparse approach is a promising step towards building more efficient and resource-friendly LLMs. By leveraging sparsity, the authors have shown that it's possible to drastically reduce the computational overhead of these models without sacrificing their capabilities.
However, the paper does not address some potential limitations of the Turbo Sparse approach. For example, the sparse attention and feed-forward layers may not be as expressive as their dense counterparts, which could limit the model's ability to capture certain linguistic phenomena. Additionally, the training process for Turbo Sparse models may be more complex and sensitive to hyperparameter tuning compared to dense models.
The authors also do not explore the potential for further increasing the sparsity of Turbo Sparse models or combining it with other efficient techniques, such as sparsity-accelerated training or contextually-aware thresholding. Exploring these avenues could lead to even more efficient and high-performing LLMs.
Conclusion
The Turbo Sparse technique introduced in this paper represents an important step towards building more efficient and sustainable large language models. By leveraging sparse attention and feed-forward layers, the authors have demonstrated that it's possible to achieve state-of-the-art performance while using a fraction of the parameters required by traditional dense LLMs.
This work has significant implications for deploying high-performance language models on resource-constrained devices, such as edge computing systems or mobile applications. Additionally, the increased efficiency of Turbo Sparse models could help reduce the substantial environmental and financial costs associated with training and running large-scale language models.
Overall, the Turbo Sparse approach is a promising direction for the field of efficient AI, and the authors have laid the groundwork for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guangli Li, Tao Yang, Maosong Sun
0
0
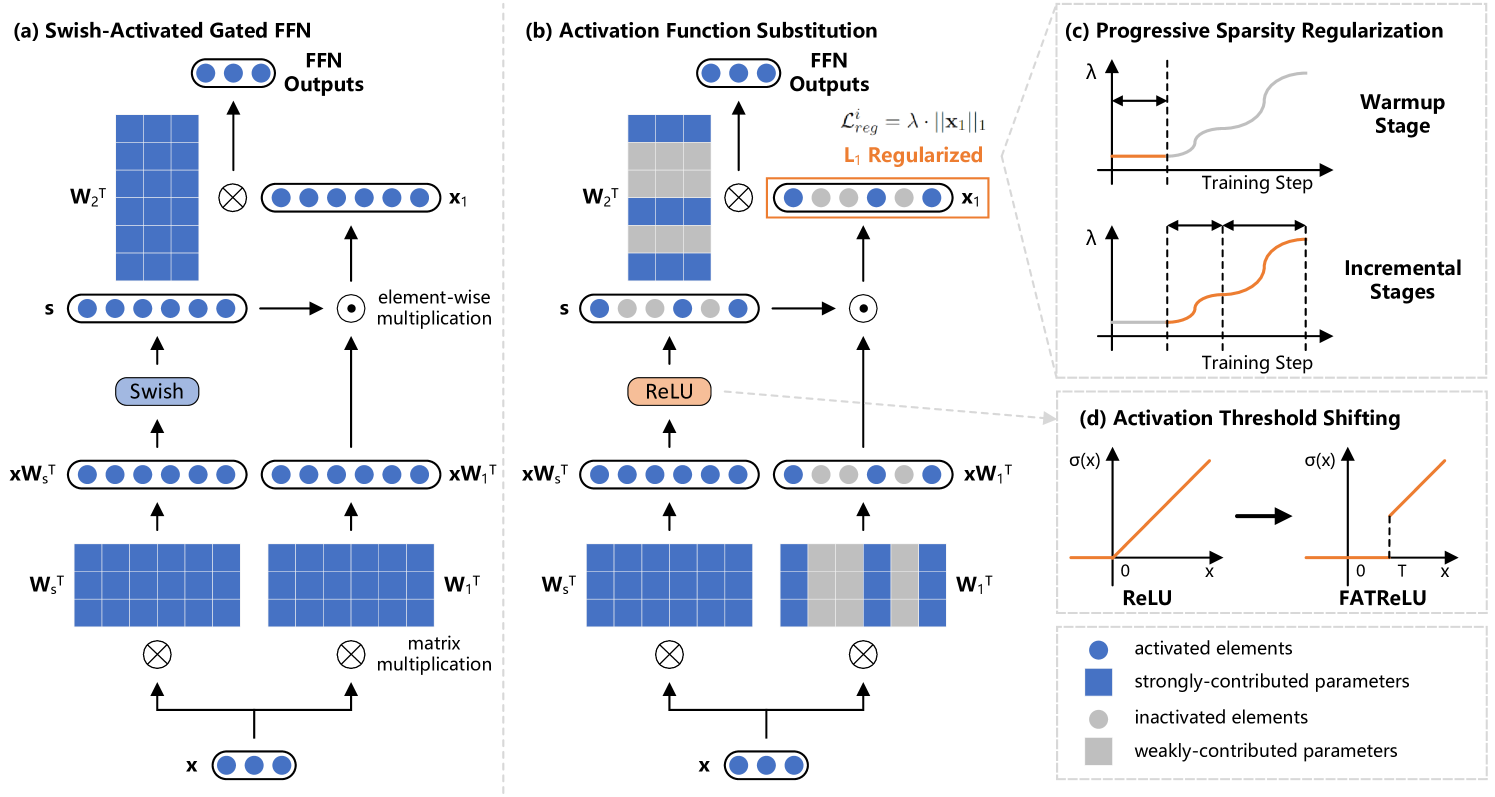
Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, activation sparsity has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces a simple and effective sparsification method named ProSparse to push LLMs for higher activation sparsity while maintaining comparable performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along the multi-stage sine curves. This can enhance activation sparsity and mitigate performance degradation by avoiding radical shifts in activation distributions. With ProSparse, we obtain high sparsity of 89.32% for LLaMA2-7B, 88.80% for LLaMA2-13B, and 87.89% for end-size MiniCPM-1B, respectively, achieving comparable performance to their original Swish-activated versions. These present the most sparsely activated models among open-source LLaMA versions and competitive end-size models, considerably surpassing ReluLLaMA-7B (66.98%) and ReluLLaMA-13B (71.56%). Our inference acceleration experiments further demonstrate the significant practical acceleration potential of LLMs with higher activation sparsity, obtaining up to 4.52$times$ inference speedup.
5/28/2024
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Z. Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
0
0
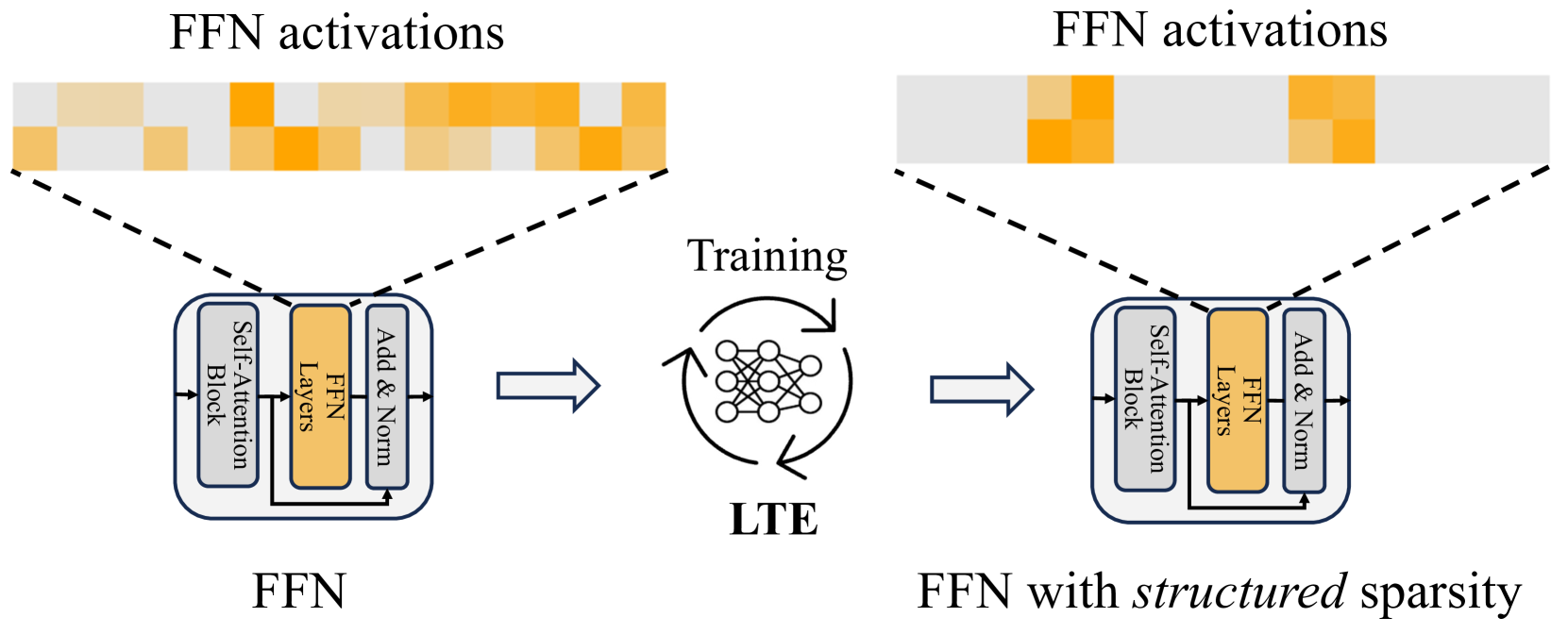
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
6/5/2024
Achieving Sparse Activation in Small Language Models
Jifeng Song, Kai Huang, Xiangyu Yin, Boyuan Yang, Wei Gao
0
0
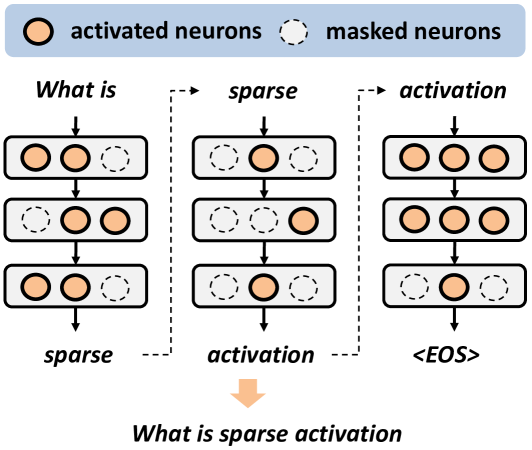
Sparse activation, which selectively activates only an input-dependent set of neurons in inference, is a useful technique to reduce the computing cost of Large Language Models (LLMs) without retraining or adaptation efforts. However, whether it can be applied to the recently emerging Small Language Models (SLMs) remains questionable, because SLMs are generally less over-parameterized than LLMs. In this paper, we aim to achieve sparse activation in SLMs. We first show that the existing sparse activation schemes in LLMs that build on neurons' output magnitudes cannot be applied to SLMs, and activating neurons based on their attribution scores is a better alternative. Further, we demonstrated and quantified the large errors of existing attribution metrics when being used for sparse activation, due to the interdependency among attribution scores of neurons across different layers. Based on these observations, we proposed a new attribution metric that can provably correct such errors and achieve precise sparse activation. Experiments over multiple popular SLMs and datasets show that our approach can achieve 80% sparsification ratio with <5% model accuracy loss, comparable to the sparse activation achieved in LLMs. The source code is available at: https://github.com/pittisl/Sparse-Activation.
6/12/2024
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024