Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
2405.06948
0
0
🛸
Abstract
Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.
Create account to get full access
Overview
- Existing text-to-image generation models struggle with maintaining both text-image alignment and subject fidelity
- They often encounter issues like missing objects and incorrect attribute combinations when generating complex, compositional subjects
- The proposed framework introduces training-free guidance to strengthen the attention map and enable precise attribute binding and feature injection for each subject
- The method exhibits exceptional zero-shot generation ability, especially for compositional subjects
- A new metric, GroundingScore, is introduced to thoroughly evaluate subject alignment
Plain English Explanation
The researchers have developed a new way to generate images from text that is better at keeping the generated images closely aligned with the input text, especially when the text describes complex, multi-part subjects. Existing models often struggle with this, resulting in missing elements or incorrectly combined attributes in the generated images.
The key innovation is a "training-free guidance" approach that helps the model focus on the different parts of the input text and accurately incorporate them into the final image. This allows the model to be very precise in how it translates the text into a visually faithful image, even for intricate descriptions.
Additionally, the researchers introduce a new way to evaluate how well the generated images match the input text, called the "GroundingScore". This provides a more detailed and comprehensive assessment than previous metrics.
Overall, this work represents an important advance in text-to-image generation that could lead to more realistic and contextualized images, with potential applications in areas like digital art, visualization, and beyond.
Technical Explanation
The researchers propose a "subject-driven generation framework" that introduces training-free guidance to intervene in the generative process during inference time. This strengthens the attention map, allowing for precise attribute binding and feature injection for each subject in the input text.
The key components of the framework are:
- Attention Strengthening: The training-free guidance mechanism enhances the model's attention to different parts of the input text, enabling more accurate translation into visual elements.
- Attribute Binding: The guided attention helps the model precisely bind the attributes described in the text to the corresponding visual elements in the generated image.
- Feature Injection: The method injects the relevant visual features for each subject into the appropriate locations in the output image.
Experiments demonstrate that this approach exhibits exceptional zero-shot generation capabilities, particularly for compositional subjects - cases where the input text describes multiple interrelated objects or concepts.
The researchers also propose a novel evaluation metric called GroundingScore, which assesses how well the generated images are grounded in the input text by examining the alignment of specific visual elements.
Critical Analysis
The paper presents a compelling solution to the challenge of maintaining both text-image alignment and subject fidelity in text-to-image generation models. The training-free guidance approach is a clever innovation that avoids the need for tedious fine-tuning steps required by other methods.
One potential limitation is that the method may be computationally more expensive during inference, as the additional guidance mechanism needs to be applied. The paper does not provide a detailed analysis of the runtime performance or memory footprint of the proposed approach.
Additionally, while the GroundingScore metric is a valuable contribution, it is still a fairly narrow and specialized evaluation. There may be opportunities to develop more holistic assessment frameworks that capture a broader range of text-to-3D generation qualities, such as overall visual quality, contextual coherence, and user experience.
Further research could also explore how the training-free guidance technique could be applied to other text-to-visual tasks, such as text-centric background adaptation, or how it could be combined with other advancements in the field to create even more powerful and versatile text-to-image generation models.
Conclusion
The proposed subject-driven generation framework with training-free guidance represents a significant advancement in text-to-image generation. By strengthening the attention map and enabling precise attribute binding and feature injection, the method demonstrates exceptional zero-shot generation capabilities, particularly for complex, compositional subjects.
The introduction of the GroundingScore metric also provides a more thorough way to evaluate the alignment between generated images and their corresponding input text. This work has the potential to drive further progress in text-to-visual generation, with applications ranging from digital art and visualization to human-AI collaboration and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Training-Free Consistent Text-to-Image Generation
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, Yuval Atzmon
0
0
Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging. Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects. Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images. Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios, and even enable training-free personalization for common objects.
5/31/2024

Improving Subject-Driven Image Synthesis with Subject-Agnostic Guidance
Kelvin C. K. Chan, Yang Zhao, Xuhui Jia, Ming-Hsuan Yang, Huisheng Wang
0
0
In subject-driven text-to-image synthesis, the synthesis process tends to be heavily influenced by the reference images provided by users, often overlooking crucial attributes detailed in the text prompt. In this work, we propose Subject-Agnostic Guidance (SAG), a simple yet effective solution to remedy the problem. We show that through constructing a subject-agnostic condition and applying our proposed dual classifier-free guidance, one could obtain outputs consistent with both the given subject and input text prompts. We validate the efficacy of our approach through both optimization-based and encoder-based methods. Additionally, we demonstrate its applicability in second-order customization methods, where an encoder-based model is fine-tuned with DreamBooth. Our approach is conceptually simple and requires only minimal code modifications, but leads to substantial quality improvements, as evidenced by our evaluations and user studies.
5/3/2024
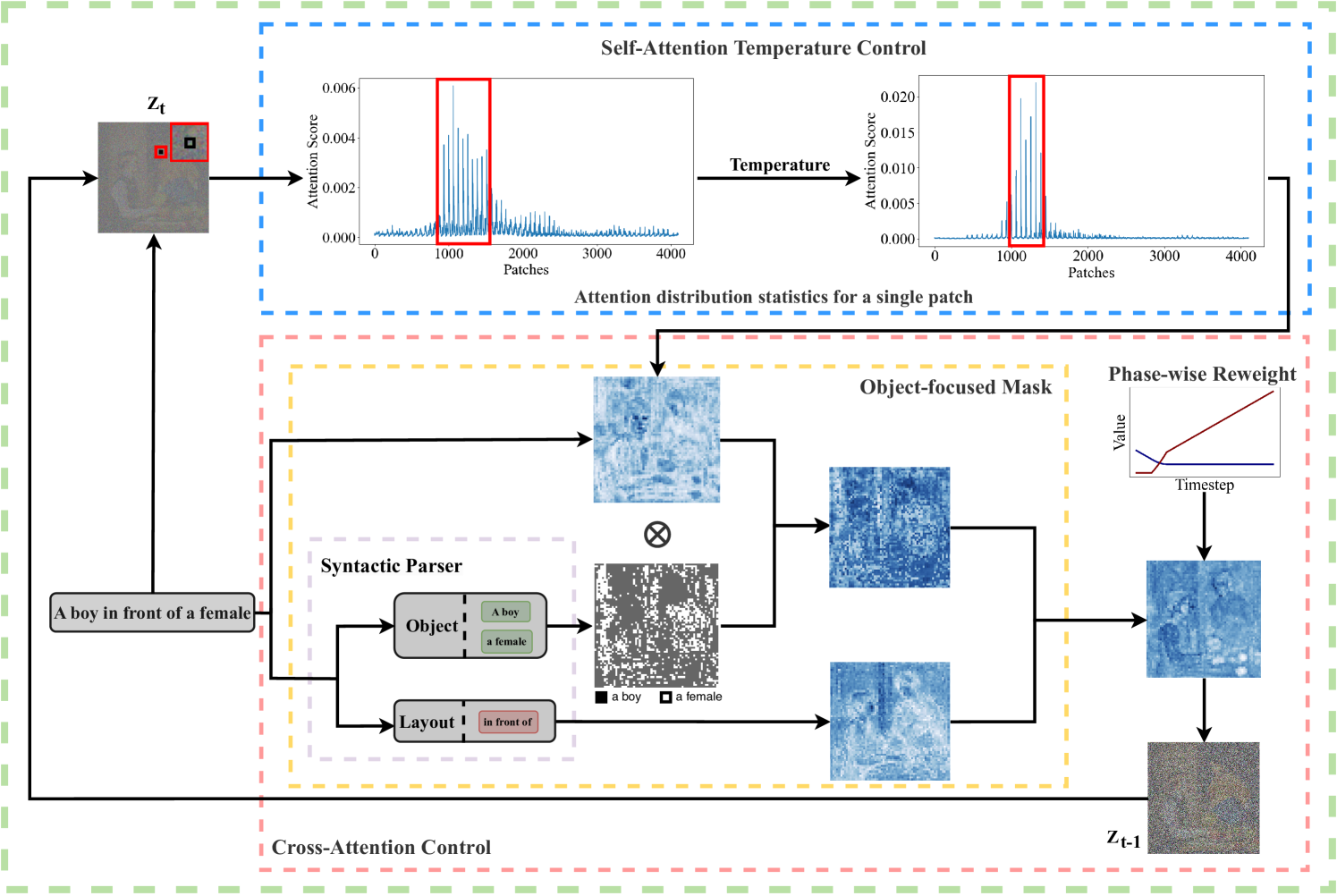
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
0
0
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
4/23/2024

Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Arman Zarei, Keivan Rezaei, Samyadeep Basu, Mehrdad Saberi, Mazda Moayeri, Priyatham Kattakinda, Soheil Feizi
0
0
Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
6/13/2024