Transfer Entropy in Graph Convolutional Neural Networks

0
Sign in to get full access
Overview
- This paper investigates the use of transfer entropy to analyze the inner workings of Graph Convolutional Neural Networks (GCNNs).
- Transfer entropy is a measure of the information flow between different parts of a system, which the authors apply to study the information propagation in GCNNs.
- The goal is to gain insights into how GCNNs learn and extract useful features from graph-structured data.
Plain English Explanation
GCNNs are a type of deep learning model that can process data represented as graphs, rather than just flat arrays or images. Graphs are useful for modeling complex relationships, like social networks or chemical compounds. However, it's often unclear how GCNNs actually work under the hood to extract useful information from these graphs.
The researchers in this paper use a technique called transfer entropy to peek inside the GCNN "black box" and see how information flows through the model as it learns. Transfer entropy measures the amount of information that one part of the system (like a neuron in the GCNN) transfers to another part. By looking at the transfer entropy between different layers and components of the GCNN, the researchers can get a better understanding of how the model is processing the graph data and making its predictions.
This kind of analysis can help improve the interpretability of GCNNs, making it easier for humans to understand and trust the model's decisions. It can also guide future developments in GCNN architecture and training by revealing which parts of the model are most important for different tasks.
Technical Explanation
The key steps in the paper's analysis are:
-
Defining Transfer Entropy: The authors use transfer entropy as a measure of the information flow between different parts of the GCNN. Transfer entropy quantifies how much the past of one variable (e.g., a neuron's activation) can be used to predict the future of another variable (e.g., another neuron's activation), beyond what can be predicted using the past of the second variable alone.
-
Applying Transfer Entropy to GCNNs: The researchers compute transfer entropy between the input features, the hidden layer activations, and the output predictions of the GCNN. This allows them to understand how information propagates through the model and which connections are most important for the overall performance.
-
Experiments and Insights: The authors perform experiments on various GCNN architectures and datasets to study the transfer entropy patterns. They find that transfer entropy can reveal the relative importance of different graph convolution layers, identify critical connections in the model, and even help explain the model's sensitivity to probabilistic graph structures.
Critical Analysis
The paper provides a valuable new perspective on understanding the inner workings of GCNNs. By using transfer entropy, the researchers are able to go beyond simply measuring the GCNN's predictive performance and gain insights into the specific mechanisms driving the model's behavior.
However, the transfer entropy analysis is still limited to the specific architectures and datasets studied in the paper. More research is needed to understand how these insights generalize to a wider range of GCNN models and real-world applications. Additionally, the transfer entropy computations can be computationally intensive, which may limit their practical use in large-scale or real-time GCNN deployments.
Further work could also explore ways to directly incorporate transfer entropy into the GCNN training process, rather than just using it as a post-hoc analysis tool. This could potentially lead to more interpretable and robust GCNN models that are better aligned with the underlying graph structure.
Conclusion
This paper demonstrates the value of using transfer entropy to analyze the inner workings of Graph Convolutional Neural Networks. By quantifying the information flow within the model, the researchers are able to gain important insights into how GCNNs process and extract useful features from graph-structured data.
These insights can inform the design of future GCNN architectures, guide the training process, and ultimately lead to more interpretable and trustworthy models for a variety of graph-based applications. As the use of GCNNs continues to grow, techniques like transfer entropy analysis will become increasingly important for understanding and improving these powerful machine learning tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transfer Entropy in Graph Convolutional Neural Networks
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
Graph Convolutional Networks (GCN) are Graph Neural Networks where the convolutions are applied over a graph. In contrast to Convolutional Neural Networks, GCN's are designed to perform inference on graphs, where the number of nodes can vary, and the nodes are unordered. In this study, we address two important challenges related to GCNs: i) oversmoothing; and ii) the utilization of node relational properties (i.e., heterophily and homophily). Oversmoothing is the degradation of the discriminative capacity of nodes as a result of repeated aggregations. Heterophily is the tendency for nodes of different classes to connect, whereas homophily is the tendency of similar nodes to connect. We propose a new strategy for addressing these challenges in GCNs based on Transfer Entropy (TE), which measures of the amount of directed transfer of information between two time varying nodes. Our findings indicate that using node heterophily and degree information as a node selection mechanism, along with feature-based TE calculations, enhances accuracy across various GCN models. Our model can be easily modified to improve classification accuracy of a GCN model. As a trade off, this performance boost comes with a significant computational overhead when the TE is computed for many graph nodes.
Read more6/12/2024

0
Learning in Convolutional Neural Networks Accelerated by Transfer Entropy
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
Recently, there is a growing interest in applying Transfer Entropy (TE) in quantifying the effective connectivity between artificial neurons. In a feedforward network, the TE can be used to quantify the relationships between neuron output pairs located in different layers. Our focus is on how to include the TE in the learning mechanisms of a Convolutional Neural Network (CNN) architecture. We introduce a novel training mechanism for CNN architectures which integrates the TE feedback connections. Adding the TE feedback parameter accelerates the training process, as fewer epochs are needed. On the flip side, it adds computational overhead to each epoch. According to our experiments on CNN classifiers, to achieve a reasonable computational overhead--accuracy trade-off, it is efficient to consider only the inter-neural information transfer of a random subset of the neuron pairs from the last two fully connected layers. The TE acts as a smoothing factor, generating stability and becoming active only periodically, not after processing each input sample. Therefore, we can consider the TE is in our model a slowly changing meta-parameter.
Read more4/5/2024

0
Understanding Heterophily for Graph Neural Networks
Junfu Wang, Yuanfang Guo, Liang Yang, Yunhong Wang
Graphs with heterophily have been regarded as challenging scenarios for Graph Neural Networks (GNNs), where nodes are connected with dissimilar neighbors through various patterns. In this paper, we present theoretical understandings of the impacts of different heterophily patterns for GNNs by incorporating the graph convolution (GC) operations into fully connected networks via the proposed Heterophilous Stochastic Block Models (HSBM), a general random graph model that can accommodate diverse heterophily patterns. Firstly, we show that by applying a GC operation, the separability gains are determined by two factors, i.e., the Euclidean distance of the neighborhood distributions and $sqrt{mathbb{E}left[operatorname{deg}right]}$, where $mathbb{E}left[operatorname{deg}right]$ is the averaged node degree. It reveals that the impact of heterophily on classification needs to be evaluated alongside the averaged node degree. Secondly, we show that the topological noise has a detrimental impact on separability, which is equivalent to degrading $mathbb{E}left[operatorname{deg}right]$. Finally, when applying multiple GC operations, we show that the separability gains are determined by the normalized distance of the $l$-powered neighborhood distributions. It indicates that the nodes still possess separability as $l$ goes to infinity in a wide range of regimes. Extensive experiments on both synthetic and real-world data verify the effectiveness of our theory.
Read more6/5/2024
0
Graph Neural Networks Do Not Always Oversmooth
Bastian Epping, Alexandre Ren'e, Moritz Helias, Michael T. Schaub
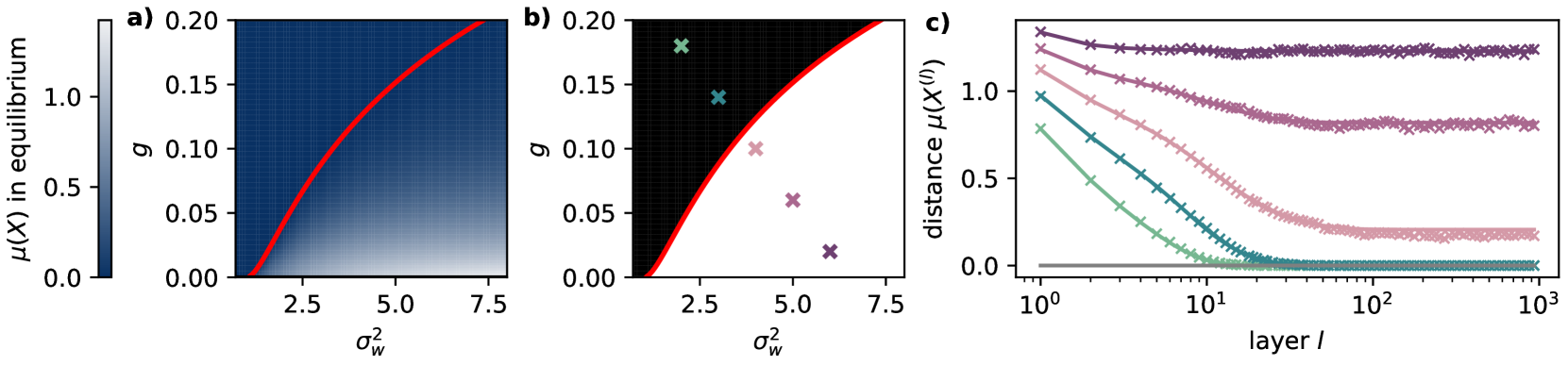
Graph neural networks (GNNs) have emerged as powerful tools for processing relational data in applications. However, GNNs suffer from the problem of oversmoothing, the property that the features of all nodes exponentially converge to the same vector over layers, prohibiting the design of deep GNNs. In this work we study oversmoothing in graph convolutional networks (GCNs) by using their Gaussian process (GP) equivalence in the limit of infinitely many hidden features. By generalizing methods from conventional deep neural networks (DNNs), we can describe the distribution of features at the output layer of deep GCNs in terms of a GP: as expected, we find that typical parameter choices from the literature lead to oversmoothing. The theory, however, allows us to identify a new, nonoversmoothing phase: if the initial weights of the network have sufficiently large variance, GCNs do not oversmooth, and node features remain informative even at large depth. We demonstrate the validity of this prediction in finite-size GCNs by training a linear classifier on their output. Moreover, using the linearization of the GCN GP, we generalize the concept of propagation depth of information from DNNs to GCNs. This propagation depth diverges at the transition between the oversmoothing and non-oversmoothing phase. We test the predictions of our approach and find good agreement with finite-size GCNs. Initializing GCNs near the transition to the non-oversmoothing phase, we obtain networks which are both deep and expressive.
Read more6/5/2024