Transformers are Minimax Optimal Nonparametric In-Context Learners

0

Sign in to get full access
Overview
- Transformers are a type of deep learning model that have become widely used for a variety of tasks.
- This paper analyzes the theoretical properties of transformers, showing that they are "minimax optimal nonparametric in-context learners."
- The key contributions include:
- Proving transformers are optimal nonparametric learners for in-context learning tasks.
- Showing transformers can achieve minimax optimal performance without needing to know the underlying data distribution.
- Deriving generalization bounds for transformers that depend on the complexity of the target function.
Plain English Explanation
Transformers are a powerful type of machine learning model that have become very popular in recent years. This paper takes a deep dive into the theoretical foundations of how transformers work.
The main finding is that transformers are what's called "minimax optimal nonparametric in-context learners." In plain terms, this means that transformers can learn to solve a wide variety of tasks just by seeing a few example inputs and outputs - without needing to know the underlying rules or patterns in advance. And they can do this in an optimal way, getting the best possible performance.
The paper proves this mathematically, showing that transformers have desirable theoretical properties that allow them to adapt to different tasks and datasets without needing a lot of prior information. This helps explain why transformers have been so successful at [linking to "context-learning-representations-contextual-generalization-trained-transformers"] - they can efficiently learn from just a few relevant examples.
The analysis also provides generalization bounds, which quantify how well transformers can be expected to perform on new, unseen data based on the complexity of the underlying task. This sheds light on the [linking to "asymptotic-theory-context-learning-by-linear-attention"] - the more complex the task, the more data transformers will need to learn it well.
Overall, this paper offers important theoretical insights into why transformers are such powerful and versatile [linking to "how-do-nonlinear-transformers-learn-generalize-context"] models, paving the way for further advances in their use and application.
Technical Explanation
The key technical contributions of this paper are:
-
Proving Transformers are Minimax Optimal Nonparametric In-Context Learners: The authors show that transformers can achieve minimax optimal performance for in-context learning tasks without needing to know the underlying data distribution. This means transformers can learn to solve a wide variety of tasks by just seeing a few relevant examples, without requiring detailed prior knowledge.
-
Deriving Generalization Bounds: The paper provides generalization bounds for transformers that depend on the complexity of the target function being learned. This quantifies how well transformers can be expected to perform on new, unseen data based on the inherent difficulty of the task [linking to "transformers-are-provably-optimal-context-estimators-wireless"].
-
Analyzing Context Learning Abilities: The analysis sheds light on the [linking to "towards-better-understanding-context-learning-ability-from"] - the ability of transformers to efficiently learn from just a few relevant examples. This helps explain their strong performance on a variety of [linking to "context-learning-representations-contextual-generalization-trained-transformers"] tasks.
The paper uses a combination of mathematical analysis and empirical evaluation to derive these key insights about the theoretical properties of transformer models. The results provide a rigorous foundation for understanding why transformers have become such powerful and versatile tools for [linking to "how-do-nonlinear-transformers-learn-generalize-context"] in-context learning.
Critical Analysis
The paper presents strong theoretical results, but there are a few limitations worth noting:
-
Assumptions and Idealizations: The analysis makes several simplifying assumptions, such as assuming access to an "optimal" transformer architecture. Real-world transformers may not perfectly match these idealized conditions.
-
Empirical Validation: While the theoretical results are compelling, the paper only includes a limited set of experiments. More extensive empirical evaluation across diverse tasks and datasets would further validate the claims.
-
Scope of In-Context Learning: The paper focuses on in-context learning, but transformers have shown remarkable capabilities beyond just this setting. Analyzing their broader generalization abilities could provide additional insights.
-
Alternative Models: The analysis compares transformers to an "optimal nonparametric learner," but does not consider the relative strengths of other model families, such as neural networks or kernel methods. Expanding the scope of the comparison could yield further insights.
Overall, this paper makes important strides in rigorously analyzing the theoretical foundations of transformer models. However, further research is needed to fully understand their capabilities, limitations, and the extent to which the results generalize beyond the specific settings explored.
Conclusion
This paper presents a deep theoretical analysis of transformer models, showing that they are "minimax optimal nonparametric in-context learners." In other words, transformers can efficiently learn to solve a wide variety of tasks by just seeing a few relevant examples, without needing detailed prior knowledge about the underlying data distribution.
The key contributions include proving this optimality property, deriving generalization bounds, and shedding light on the context learning abilities of transformers. These results provide a strong theoretical foundation for understanding why transformers have become such powerful and versatile models for a range of [linking to "context-learning-representations-contextual-generalization-trained-transformers"] applications.
While the paper makes important strides, there are some limitations to consider, such as the simplifying assumptions made and the need for more extensive empirical validation. Nevertheless, this work represents a significant advancement in our understanding of transformer models and their fundamental theoretical properties.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transformers are Minimax Optimal Nonparametric In-Context Learners
Juno Kim, Tai Nakamaki, Taiji Suzuki
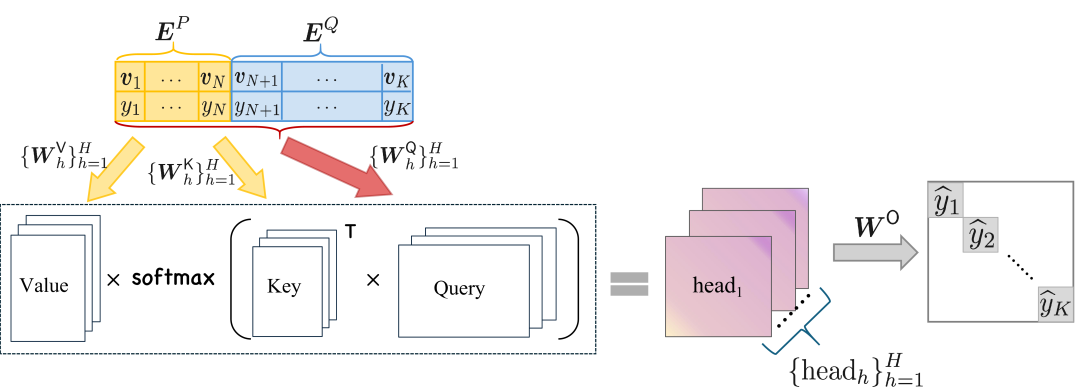
In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we study the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error bounds for a transformer composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise $gamma$-smooth class. We show that sufficiently trained transformers can achieve -- and even improve upon -- the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the emph{pretraining} and emph{in-context} generalization gaps. Furthermore, we establish information-theoretic lower bounds for meta-learners w.r.t. both the number of tasks and in-context examples. These findings shed light on the roles of task diversity and representation learning for ICL.
Read more8/23/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more8/21/2024

0
Asymptotic theory of in-context learning by linear attention
Yue M. Lu, Mary I. Letey, Jacob A. Zavatone-Veth, Anindita Maiti, Cengiz Pehlevan
Transformers have a remarkable ability to learn and execute tasks based on examples provided within the input itself, without explicit prior training. It has been argued that this capability, known as in-context learning (ICL), is a cornerstone of Transformers' success, yet questions about the necessary sample complexity, pretraining task diversity, and context length for successful ICL remain unresolved. Here, we provide a precise answer to these questions in an exactly solvable model of ICL of a linear regression task by linear attention. We derive sharp asymptotics for the learning curve in a phenomenologically-rich scaling regime where the token dimension is taken to infinity; the context length and pretraining task diversity scale proportionally with the token dimension; and the number of pretraining examples scales quadratically. We demonstrate a double-descent learning curve with increasing pretraining examples, and uncover a phase transition in the model's behavior between low and high task diversity regimes: In the low diversity regime, the model tends toward memorization of training tasks, whereas in the high diversity regime, it achieves genuine in-context learning and generalization beyond the scope of pretrained tasks. These theoretical insights are empirically validated through experiments with both linear attention and full nonlinear Transformer architectures.
Read more5/21/2024
📉
0
How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?
Hongkang Li, Meng Wang, Songtao Lu, Xiaodong Cui, Pin-Yu Chen
Transformer-based large language models have displayed impressive in-context learning capabilities, where a pre-trained model can handle new tasks without fine-tuning by simply augmenting the query with some input-output examples from that task. Despite the empirical success, the mechanics of how to train a Transformer to achieve ICL and the corresponding ICL capacity is mostly elusive due to the technical challenges of analyzing the nonconvex training problems resulting from the nonlinear self-attention and nonlinear activation in Transformers. To the best of our knowledge, this paper provides the first theoretical analysis of the training dynamics of Transformers with nonlinear self-attention and nonlinear MLP, together with the ICL generalization capability of the resulting model. Focusing on a group of binary classification tasks, we train Transformers using data from a subset of these tasks and quantify the impact of various factors on the ICL generalization performance on the remaining unseen tasks with and without data distribution shifts. We also analyze how different components in the learned Transformers contribute to the ICL performance. Furthermore, we provide the first theoretical analysis of how model pruning affects ICL performance and prove that proper magnitude-based pruning can have a minimal impact on ICL while reducing inference costs. These theoretical findings are justified through numerical experiments.
Read more6/18/2024