In-Context Learning with Representations: Contextual Generalization of Trained Transformers

0
Sign in to get full access
Overview
- Investigates how trained transformer models can learn and generalize in new contexts
- Proposes an approach called "in-context learning with representations" to improve contextual generalization
- Conducts experiments to understand the capabilities and limitations of this approach
Plain English Explanation
This paper explores how machine learning models, specifically trained transformer models, can adapt and perform well in new situations or "contexts" that they were not originally trained on. The researchers propose a new technique called "in-context learning with representations" that aims to improve a model's ability to generalize its knowledge to these new contexts.
The key idea is to train the model not just on the task itself, but also on learning representations of the context. This allows the model to better understand the underlying structure and relationships in the new context, rather than just memorizing specific examples.
The researchers conduct experiments to test this approach and gain insights into the capabilities and limitations of contextual generalization. For example, they explore how factors like the amount of training data or the complexity of the context can impact a model's ability to adapt.
Overall, this work contributes to our understanding of how machine learning models can become more flexible and capable of handling diverse real-world situations, beyond just the specific data they were trained on.
Technical Explanation
The paper investigates contextual generalization - the ability of trained transformer models to adapt and perform well in new contexts that differ from their original training data.
The researchers propose an approach called in-context learning with representations, which trains the model not just on the task, but also on learning representations of the context. This allows the model to better understand the underlying structure and relationships in new contexts, rather than just memorizing specific examples.
Through a series of experiments, the paper explores the capabilities and limitations of this approach. For example, they investigate how factors like the amount of training data or the complexity of the context can impact a model's ability to adapt.
The insights from this work contribute to our understanding of contextual learning and how machine learning models can become more flexible and capable of handling diverse real-world situations.
Critical Analysis
The paper provides a thoughtful exploration of the challenges and opportunities in contextual generalization for transformer models. The proposed "in-context learning with representations" approach seems promising, as it aims to go beyond simply memorizing training examples and instead build a deeper understanding of the underlying context.
However, the paper also acknowledges several limitations and areas for further research. For example, the experiments only test a limited range of contexts, and it's unclear how well the approach would scale to truly novel or complex contexts. Additionally, the paper does not address potential issues around robustness or security that could arise when deploying such models in real-world applications.
Further research is needed to better understand the broader implications and potential risks of this technology. Continued critical analysis and empirical testing will be crucial to ensure that contextual learning systems are developed responsibly and with appropriate safeguards.
Conclusion
This paper presents an innovative approach to improving the contextual generalization capabilities of transformer models. By training the models to learn representations of the context in addition to the task, the researchers demonstrate how these models can adapt more effectively to new situations.
While the results are promising, the paper also highlights the need for further research to fully understand the limitations and potential risks of this technology. As machine learning models become increasingly capable of adapting to diverse contexts, it will be essential to carefully consider the societal implications and develop appropriate frameworks for responsible deployment.
Overall, this work contributes valuable insights to the ongoing efforts to create more flexible and adaptable AI systems that can better handle the complexities of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
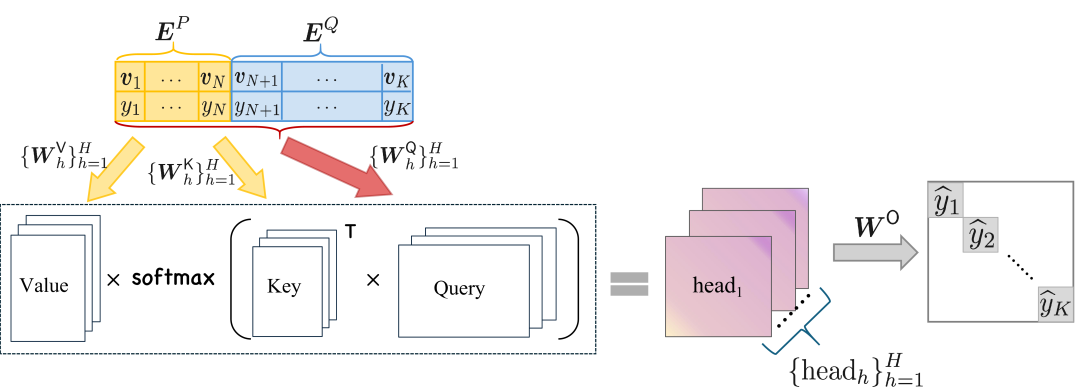
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more8/21/2024
📊
0
In-Context Learning through the Bayesian Prism
Madhur Panwar, Kabir Ahuja, Navin Goyal
In-context learning (ICL) is one of the surprising and useful features of large language models and subject of intense research. Recently, stylized meta-learning-like ICL setups have been devised that train transformers on sequences of input-output pairs $(x, f(x))$. The function $f$ comes from a function class and generalization is checked by evaluating on sequences generated from unseen functions from the same class. One of the main discoveries in this line of research has been that for several function classes, such as linear regression, transformers successfully generalize to new functions in the class. However, the inductive biases of these models resulting in this behavior are not clearly understood. A model with unlimited training data and compute is a Bayesian predictor: it learns the pretraining distribution. In this paper we empirically examine how far this Bayesian perspective can help us understand ICL. To this end, we generalize the previous meta-ICL setup to hierarchical meta-ICL setup which involve unions of multiple task families. We instantiate this setup on a diverse range of linear and nonlinear function families and find that transformers can do ICL in this setting as well. Where Bayesian inference is tractable, we find evidence that high-capacity transformers mimic the Bayesian predictor. The Bayesian perspective provides insights into the inductive bias of ICL and how transformers perform a particular task when they are trained on multiple tasks. We also find that transformers can learn to generalize to new function classes that were not seen during pretraining. This involves deviation from the Bayesian predictor. We examine these deviations in more depth offering new insights and hypotheses.
Read more4/16/2024

0
Transformers are Minimax Optimal Nonparametric In-Context Learners
Juno Kim, Tai Nakamaki, Taiji Suzuki
In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we study the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error bounds for a transformer composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise $gamma$-smooth class. We show that sufficiently trained transformers can achieve -- and even improve upon -- the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the emph{pretraining} and emph{in-context} generalization gaps. Furthermore, we establish information-theoretic lower bounds for meta-learners w.r.t. both the number of tasks and in-context examples. These findings shed light on the roles of task diversity and representation learning for ICL.
Read more8/23/2024
🌀
0
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
Read more4/11/2024