Transparent AI: Developing an Explainable Interface for Predicting Postoperative Complications
2404.16064
0
0
🔮
Abstract
Given the sheer volume of surgical procedures and the significant rate of postoperative fatalities, assessing and managing surgical complications has become a critical public health concern. Existing artificial intelligence (AI) tools for risk surveillance and diagnosis often lack adequate interpretability, fairness, and reproducibility. To address this, we proposed an Explainable AI (XAI) framework designed to answer five critical questions: why, why not, how, what if, and what else, with the goal of enhancing the explainability and transparency of AI models. We incorporated various techniques such as Local Interpretable Model-agnostic Explanations (LIME), SHapley Additive exPlanations (SHAP), counterfactual explanations, model cards, an interactive feature manipulation interface, and the identification of similar patients to address these questions. We showcased an XAI interface prototype that adheres to this framework for predicting major postoperative complications. This initial implementation has provided valuable insights into the vast explanatory potential of our XAI framework and represents an initial step towards its clinical adoption.
Create account to get full access
Overview
- Assessing and managing surgical complications is a critical public health concern due to the high volume of procedures and significant rate of postoperative fatalities.
- Existing AI tools for risk surveillance and diagnosis often lack adequate interpretability, fairness, and reproducibility.
- The researchers propose an Explainable AI (XAI) framework to enhance the explainability and transparency of AI models used for this task.
Plain English Explanation
The paper focuses on a critical issue in healthcare: the large number of surgical procedures and the significant rate of patients dying after these operations. Existing AI systems used to monitor for complications and diagnose issues often have problems with being easy to understand, treating people fairly, and producing consistent results.
To address this, the researchers developed a new approach called Explainable AI (XAI). The goal of XAI is to make AI models more transparent and easier to understand. The XAI framework they created aims to answer five key questions: why did the model make a particular prediction, why didn't it make a different prediction, how did it arrive at its conclusion, what would happen if certain factors were changed, and what other factors might be important.
The researchers incorporated various techniques like LIME, SHAP, counterfactual explanations, and an interface that lets users interact with the model. They used these to build a prototype XAI system for predicting major complications after surgery. This initial implementation provided valuable insights into the potential of the XAI framework and represents an important step towards integrating it into clinical practice.
Technical Explanation
The paper proposes an Explainable AI (XAI) framework to address the lack of interpretability, fairness, and reproducibility in existing AI tools for assessing and managing surgical complications. The XAI framework aims to provide answers to five key questions: why, why not, how, what if, and what else.
To achieve this, the researchers incorporated various XAI techniques, including:
- Local Interpretable Model-agnostic Explanations (LIME): Generates local, interpretable explanations for individual predictions.
- SHapley Additive exPlanations (SHAP): Calculates the contribution of each feature to the model's output.
- Counterfactual explanations: Identifies changes to input features that would lead to a different model prediction.
- Model cards: Provide detailed information about the model's performance, intended use, and potential biases.
- An interactive feature manipulation interface: Allows users to explore the impact of changing input features on the model's predictions.
- Identification of similar patients: Helps users understand how the current patient compares to others used to train the model.
The researchers showcased a prototype XAI interface for predicting major postoperative complications. This initial implementation provided valuable insights into the potential of the XAI framework and represents an important step towards clinical adoption.
Critical Analysis
The paper presents a compelling approach to enhancing the interpretability, fairness, and reproducibility of AI models used for assessing and managing surgical complications. The proposed XAI framework addresses several critical limitations of existing AI tools in this domain, such as the lack of transparency and the potential for biased or inconsistent predictions.
One potential limitation of the research is the lack of a detailed evaluation of the XAI framework's impact on clinical decision-making and patient outcomes. While the prototype interface demonstrates the technical feasibility of the approach, further research is needed to assess its real-world effectiveness and practical implications for healthcare professionals and patients.
Additionally, the paper does not extensively explore potential ethical considerations or privacy concerns related to the use of patient data in the XAI system. As with any AI-powered healthcare application, it will be crucial to address these issues to ensure the responsible and equitable deployment of the technology.
Overall, the paper represents an important step towards improving the design of interpretable and trustworthy AI systems for critical healthcare applications. The XAI framework proposed in this research has the potential to significantly enhance the transparency and accountability of AI-based risk surveillance and diagnostic tools, ultimately leading to improved patient outcomes and better-informed clinical decision-making.
Conclusion
The paper presents an Explainable AI (XAI) framework designed to enhance the interpretability, fairness, and reproducibility of AI models used for assessing and managing surgical complications. By incorporating techniques like LIME, SHAP, counterfactual explanations, and interactive user interfaces, the XAI framework aims to provide healthcare professionals and patients with a better understanding of how these AI systems make predictions and recommendations.
The prototype XAI interface showcased in the paper represents an important initial step towards the clinical adoption of this technology. As the researchers note, further research is needed to fully evaluate the framework's impact on clinical decision-making and patient outcomes. However, this work represents a significant contribution to the growing field of explainable and trustworthy AI, with the potential to improve the quality and safety of surgical care for patients worldwide.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
0
0
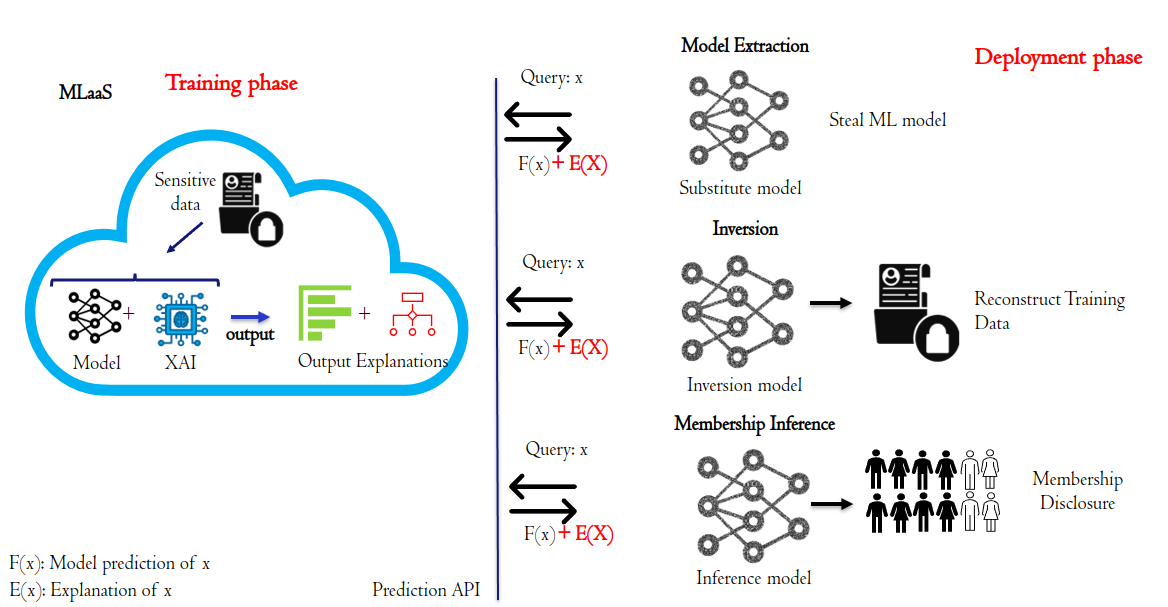
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
6/26/2024
From Explainable to Interpretable Deep Learning for Natural Language Processing in Healthcare: How Far from Reality?
Guangming Huang, Yingya Li, Shoaib Jameel, Yunfei Long, Giorgos Papanastasiou
0
0
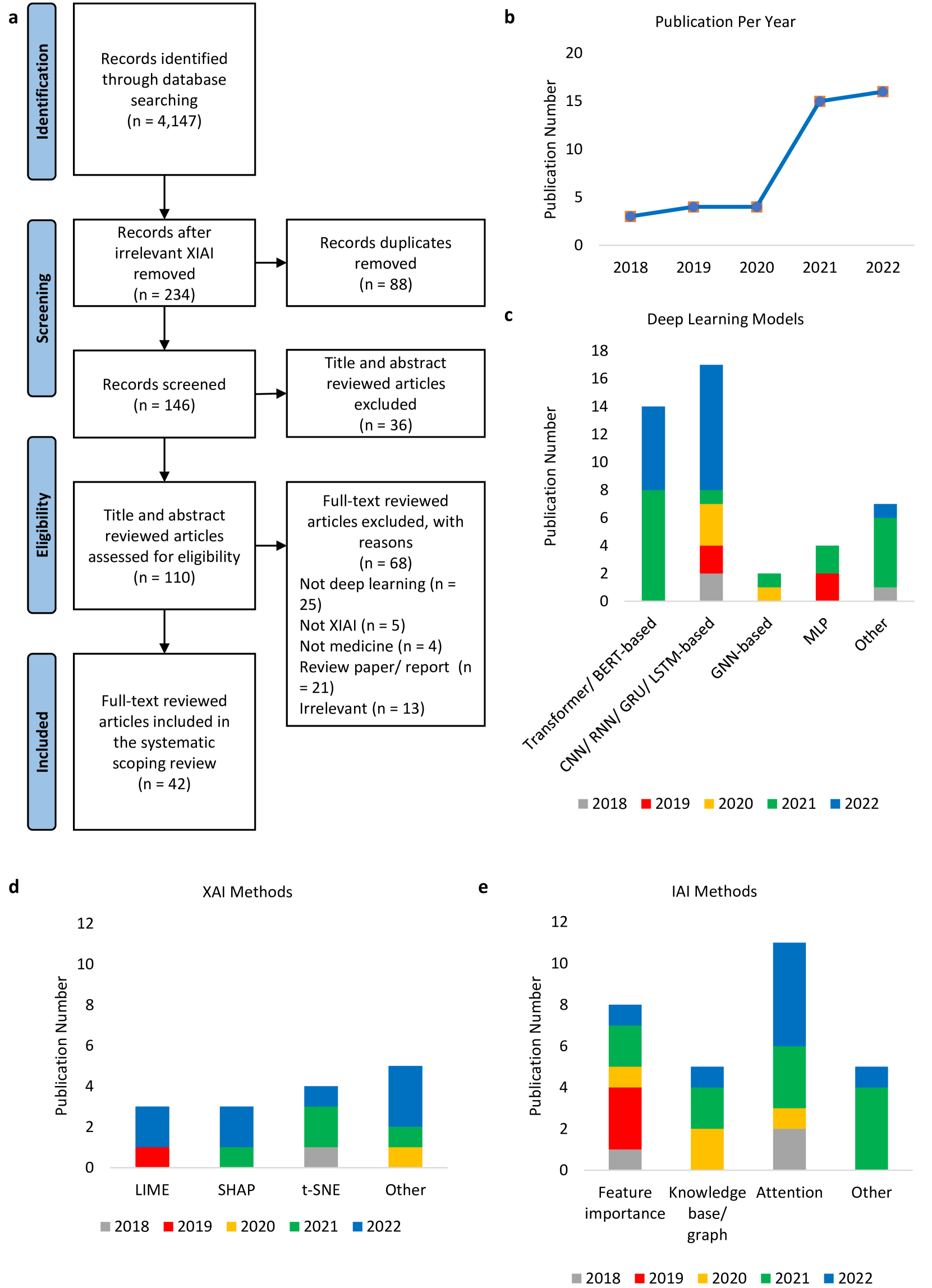
Deep learning (DL) has substantially enhanced natural language processing (NLP) in healthcare research. However, the increasing complexity of DL-based NLP necessitates transparent model interpretability, or at least explainability, for reliable decision-making. This work presents a thorough scoping review of explainable and interpretable DL in healthcare NLP. The term eXplainable and Interpretable Artificial Intelligence (XIAI) is introduced to distinguish XAI from IAI. Different models are further categorized based on their functionality (model-, input-, output-based) and scope (local, global). Our analysis shows that attention mechanisms are the most prevalent emerging IAI technique. The use of IAI is growing, distinguishing it from XAI. The major challenges identified are that most XIAI does not explore global modelling processes, the lack of best practices, and the lack of systematic evaluation and benchmarks. One important opportunity is to use attention mechanisms to enhance multi-modal XIAI for personalized medicine. Additionally, combining DL with causal logic holds promise. Our discussion encourages the integration of XIAI in Large Language Models (LLMs) and domain-specific smaller models. In conclusion, XIAI adoption in healthcare requires dedicated in-house expertise. Collaboration with domain experts, end-users, and policymakers can lead to ready-to-use XIAI methods across NLP and medical tasks. While challenges exist, XIAI techniques offer a valuable foundation for interpretable NLP algorithms in healthcare.
5/13/2024

Breast Cancer Diagnosis: A Comprehensive Exploration of Explainable Artificial Intelligence (XAI) Techniques
Samita Bai, Sidra Nasir, Rizwan Ahmed Khan, Sheeraz Arif, Alexandre Meyer, Hubert Konik
0
0
Breast cancer (BC) stands as one of the most common malignancies affecting women worldwide, necessitating advancements in diagnostic methodologies for better clinical outcomes. This article provides a comprehensive exploration of the application of Explainable Artificial Intelligence (XAI) techniques in the detection and diagnosis of breast cancer. As Artificial Intelligence (AI) technologies continue to permeate the healthcare sector, particularly in oncology, the need for transparent and interpretable models becomes imperative to enhance clinical decision-making and patient care. This review discusses the integration of various XAI approaches, such as SHAP, LIME, Grad-CAM, and others, with machine learning and deep learning models utilized in breast cancer detection and classification. By investigating the modalities of breast cancer datasets, including mammograms, ultrasounds and their processing with AI, the paper highlights how XAI can lead to more accurate diagnoses and personalized treatment plans. It also examines the challenges in implementing these techniques and the importance of developing standardized metrics for evaluating XAI's effectiveness in clinical settings. Through detailed analysis and discussion, this article aims to highlight the potential of XAI in bridging the gap between complex AI models and practical healthcare applications, thereby fostering trust and understanding among medical professionals and improving patient outcomes.
6/4/2024

The future of human-centric eXplainable Artificial Intelligence (XAI) is not post-hoc explanations
Vinitra Swamy, Jibril Frej, Tanja Kaser
0
0
Explainable Artificial Intelligence (XAI) plays a crucial role in enabling human understanding and trust in deep learning systems. As models get larger, more ubiquitous, and pervasive in aspects of daily life, explainability is necessary to minimize adverse effects of model mistakes. Unfortunately, current approaches in human-centric XAI (e.g. predictive tasks in healthcare, education, or personalized ads) tend to rely on a single post-hoc explainer, whereas recent work has identified systematic disagreement between post-hoc explainers when applied to the same instances of underlying black-box models. In this paper, we therefore present a call for action to address the limitations of current state-of-the-art explainers. We propose a shift from post-hoc explainability to designing interpretable neural network architectures. We identify five needs of human-centric XAI (real-time, accurate, actionable, human-interpretable, and consistent) and propose two schemes for interpretable-by-design neural network workflows (adaptive routing with InterpretCC and temporal diagnostics with I2MD). We postulate that the future of human-centric XAI is neither in explaining black-boxes nor in reverting to traditional, interpretable models, but in neural networks that are intrinsically interpretable.
5/29/2024