Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning

0

Sign in to get full access
Overview
- This paper introduces Tripod, a framework that incorporates three complementary inductive biases to improve disentangled representation learning.
- Disentangled representation learning aims to learn interpretable and modular representations of data, where each latent factor captures a distinct underlying generative factor.
- The three inductive biases in Tripod are: [1] a hierarchical latent structure, [2] group equivariance, and [3] a linear dynamics model.
Plain English Explanation
Disentangled representation learning is the idea of finding distinct, interpretable factors that explain the data, like separate features that control different aspects of an image. For example, in an image of a face, we might want to learn separate factors for the person's identity, facial expression, head pose, etc.
The Tripod framework combines three key techniques to help achieve better disentangled representations:
-
Hierarchical structure: The model has a nested, tree-like organization of latent factors, where higher-level factors influence lower-level ones. This matches the intuition that real-world data often has a hierarchical generative process.
-
Group equivariance: The model is designed to be equivariant to certain transformations, like rotations or translations. This means that if the input changes in a particular way, the representations change in a predictable, structured way. This can help the model discover the underlying generative factors more effectively.
-
Linear dynamics: The model assumes the latent factors evolve over time according to a simple linear dynamical system. This inductive bias can be useful when modeling time-series data, like videos, where the factors may change in a smooth, linear fashion.
By incorporating these three complementary biases, the Tripod framework aims to learn more disentangled and meaningful representations of complex data, which could be useful for a variety of applications like computer vision, robotics, and generative modeling.
Technical Explanation
The Tripod framework [1] is designed to learn disentangled representations by incorporating three key inductive biases:
-
Hierarchical latent structure: The model has a nested, tree-like organization of latent factors, where higher-level factors influence lower-level ones. This matches the intuition that real-world data often has a hierarchical generative process. This structure is inspired by Improving Reconstruction of Disentangled Representation Learners via Multi-Level Balancing.
-
Group equivariance: The model is designed to be equivariant to certain transformations, like rotations or translations. This means that if the input changes in a particular way, the representations change in a predictable, structured way. This can help the model discover the underlying generative factors more effectively. This inductive bias is motivated by Unsupervised Learning of Group Invariant and Equivariant Representations.
-
Linear dynamics: The model assumes the latent factors evolve over time according to a simple linear dynamical system. This inductive bias can be useful when modeling time-series data, like videos, where the factors may change in a smooth, linear fashion. This is inspired by From Latent Dynamics to Meaningful Representations.
The authors demonstrate the effectiveness of the Tripod framework on several benchmark datasets for disentangled representation learning, including dSprites, Shapes3D, and a multimodal affective analysis task. The results show that Tripod outperforms existing state-of-the-art methods in terms of disentanglement and downstream task performance.
Critical Analysis
The Tripod framework presents an interesting approach to disentangled representation learning by leveraging multiple complementary inductive biases. The authors provide a thorough theoretical justification for each of the three biases and demonstrate their effectiveness through extensive experiments.
One potential limitation of the work is that the specific implementation of the Tripod model may not generalize well to all types of data and tasks. The authors acknowledge that the choice of the particular group equivariance and linear dynamics modules may need to be tailored to the problem at hand. Additionally, the hierarchical structure of the latent space may not be a good fit for all datasets, and the computational complexity of the model could be a concern for large-scale applications.
Furthermore, the paper does not provide a detailed analysis of the interpretability and modularity of the learned representations, which are key goals of disentangled representation learning. Future work could delve deeper into these aspects and explore how the Tripod representations can be leveraged for downstream applications.
Conclusion
In summary, the Tripod framework introduces a novel approach to disentangled representation learning by incorporating three complementary inductive biases: hierarchical latent structure, group equivariance, and linear dynamics. The authors demonstrate the effectiveness of this approach on several benchmark datasets, showing improvements over existing state-of-the-art methods.
While the Tripod framework presents an interesting and promising direction in the field of disentangled representation learning, further research is needed to address its potential limitations and explore the interpretability and practical applications of the learned representations. Overall, this work contributes to the ongoing efforts to develop more robust and meaningful representations of complex data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning
Kyle Hsu, Jubayer Ibn Hamid, Kaylee Burns, Chelsea Finn, Jiajun Wu
Inductive biases are crucial in disentangled representation learning for narrowing down an underspecified solution set. In this work, we consider endowing a neural network autoencoder with three select inductive biases from the literature: data compression into a grid-like latent space via quantization, collective independence amongst latents, and minimal functional influence of any latent on how other latents determine data generation. In principle, these inductive biases are deeply complementary: they most directly specify properties of the latent space, encoder, and decoder, respectively. In practice, however, naively combining existing techniques instantiating these inductive biases fails to yield significant benefits. To address this, we propose adaptations to the three techniques that simplify the learning problem, equip key regularization terms with stabilizing invariances, and quash degenerate incentives. The resulting model, Tripod, achieves state-of-the-art results on a suite of four image disentanglement benchmarks. We also verify that Tripod significantly improves upon its naive incarnation and that all three of its legs are necessary for best performance.
Read more5/28/2024
🤔
0
Towards Exact Computation of Inductive Bias
Akhilan Boopathy, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
Much research in machine learning involves finding appropriate inductive biases (e.g. convolutional neural networks, momentum-based optimizers, transformers) to promote generalization on tasks. However, quantification of the amount of inductive bias associated with these architectures and hyperparameters has been limited. We propose a novel method for efficiently computing the inductive bias required for generalization on a task with a fixed training data budget; formally, this corresponds to the amount of information required to specify well-generalizing models within a specific hypothesis space of models. Our approach involves modeling the loss distribution of random hypotheses drawn from a hypothesis space to estimate the required inductive bias for a task relative to these hypotheses. Unlike prior work, our method provides a direct estimate of inductive bias without using bounds and is applicable to diverse hypothesis spaces. Moreover, we derive approximation error bounds for our estimation approach in terms of the number of sampled hypotheses. Consistent with prior results, our empirical results demonstrate that higher dimensional tasks require greater inductive bias. We show that relative to other expressive model classes, neural networks as a model class encode large amounts of inductive bias. Furthermore, our measure quantifies the relative difference in inductive bias between different neural network architectures. Our proposed inductive bias metric provides an information-theoretic interpretation of the benefits of specific model architectures for certain tasks and provides a quantitative guide to developing tasks requiring greater inductive bias, thereby encouraging the development of more powerful inductive biases.
Read more6/26/2024

0
Independence Constrained Disentangled Representation Learning from Epistemological Perspective
Ruoyu Wang, Lina Yao
Disentangled Representation Learning aims to improve the explainability of deep learning methods by training a data encoder that identifies semantically meaningful latent variables in the data generation process. Nevertheless, there is no consensus regarding a universally accepted definition for the objective of disentangled representation learning. In particular, there is a considerable amount of discourse regarding whether should the latent variables be mutually independent or not. In this paper, we first investigate these arguments on the interrelationships between latent variables by establishing a conceptual bridge between Epistemology and Disentangled Representation Learning. Then, inspired by these interdisciplinary concepts, we introduce a two-level latent space framework to provide a general solution to the prior arguments on this issue. Finally, we propose a novel method for disentangled representation learning by employing an integration of mutual information constraint and independence constraint within the Generative Adversarial Network (GAN) framework. Experimental results demonstrate that our proposed method consistently outperforms baseline approaches in both quantitative and qualitative evaluations. The method exhibits strong performance across multiple commonly used metrics and demonstrates a great capability in disentangling various semantic factors, leading to an improved quality of controllable generation, which consequently benefits the explainability of the algorithm.
Read more9/5/2024
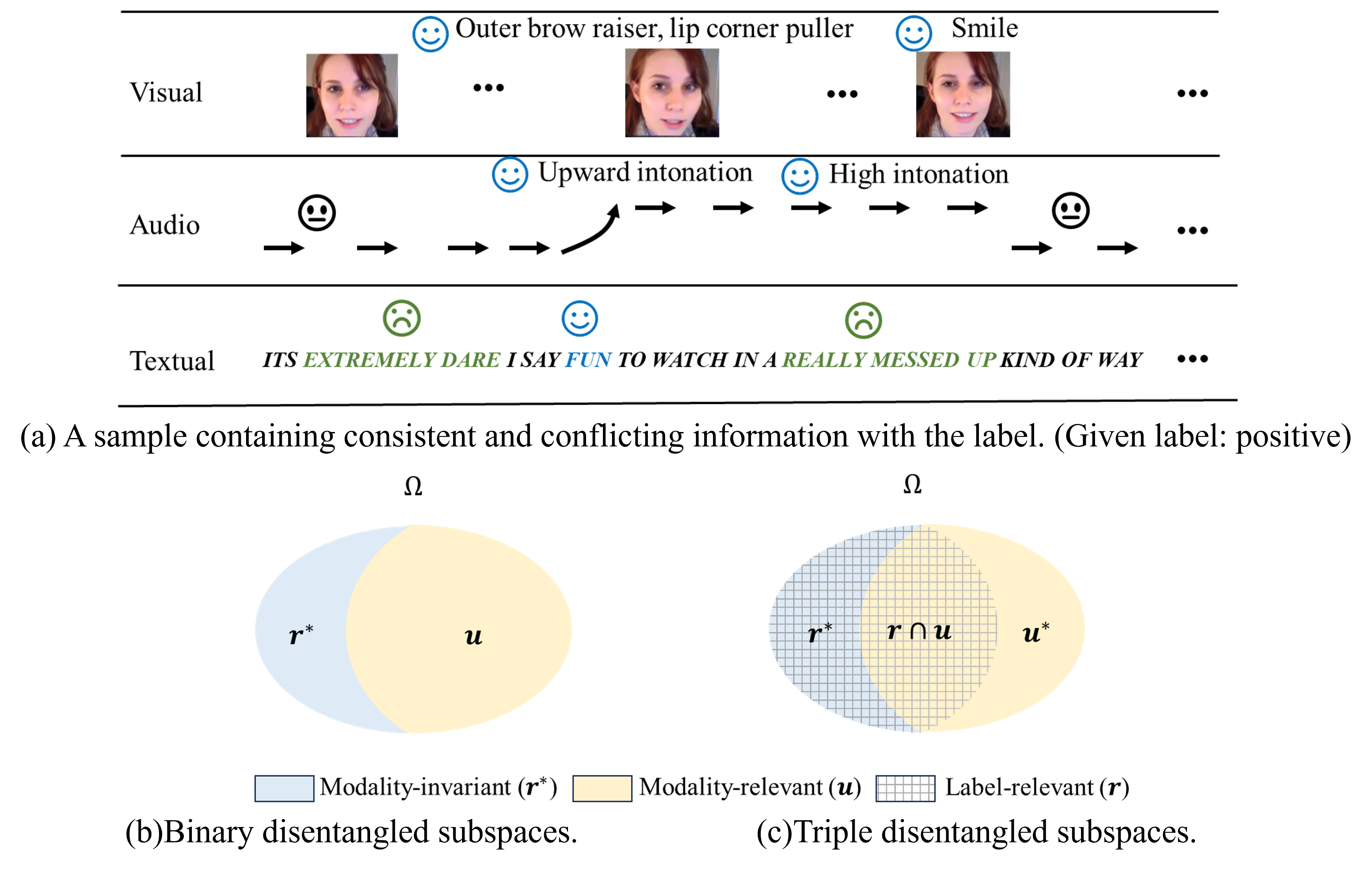
0
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Ying Zhou, Xuefeng Liang, Han Chen, Yin Zhao, Xin Chen, Lida Yu
Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Read more4/9/2024