TrojanForge: Adversarial Hardware Trojan Examples with Reinforcement Learning

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TrojanForge: Adversarial Hardware Trojan Examples with Reinforcement Learning
Amin Sarihi, Peter Jamieson, Ahmad Patooghy, Abdel-Hameed A. Badawy
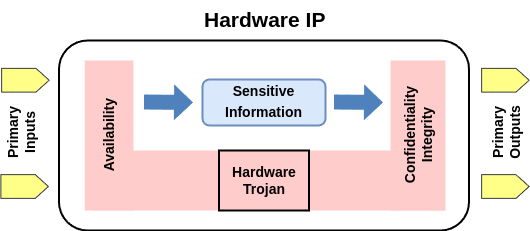
The Hardware Trojan (HT) problem can be thought of as a continuous game between attackers and defenders, each striving to outsmart the other by leveraging any available means for an advantage. Machine Learning (ML) has recently been key in advancing HT research. Various novel techniques, such as Reinforcement Learning (RL) and Graph Neural Networks (GNNs), have shown HT insertion and detection capabilities. HT insertion with ML techniques, specifically, has seen a spike in research activity due to the shortcomings of conventional HT benchmarks and the inherent human design bias that occurs when we create them. This work continues this innovation by presenting a tool called TrojanForge, capable of generating HT adversarial examples that defeat HT detectors; demonstrating the capabilities of GAN-like adversarial tools for automatic HT insertion. We introduce an RL environment where the RL insertion agent interacts with HT detectors in an insertion-detection loop where the agent collects rewards based on its success in bypassing HT detectors. Our results show that this process leads to inserted HTs that evade various HT detectors, achieving high attack success percentages. This tool provides insight into why HT insertion fails in some instances and how we can leverage this knowledge in defense.
Read more5/27/2024
0
How to Train your Antivirus: RL-based Hardening through the Problem-Space
Ilias Tsingenopoulos, Jacopo Cortellazzi, Branislav Bov{s}ansk'y, Simone Aonzo, Davy Preuveneers, Wouter Joosen, Fabio Pierazzi, Lorenzo Cavallaro
ML-based malware detection on dynamic analysis reports is vulnerable to both evasion and spurious correlations. In this work, we investigate a specific ML architecture employed in the pipeline of a widely-known commercial antivirus company, with the goal to harden it against adversarial malware. Adversarial training, the sole defensive technique that can confer empirical robustness, is not applicable out of the box in this domain, for the principal reason that gradient-based perturbations rarely map back to feasible problem-space programs. We introduce a novel Reinforcement Learning approach for constructing adversarial examples, a constituent part of adversarially training a model against evasion. Our approach comes with multiple advantages. It performs modifications that are feasible in the problem-space, and only those; thus it circumvents the inverse mapping problem. It also makes possible to provide theoretical guarantees on the robustness of the model against a particular set of adversarial capabilities. Our empirical exploration validates our theoretical insights, where we can consistently reach 0% Attack Success Rate after a few adversarial retraining iterations.
Read more9/6/2024
0
An AI Architecture with the Capability to Classify and Explain Hardware Trojans
Paul Whitten, Francis Wolff, Chris Papachristou
Hardware trojan detection methods, based on machine learning (ML) techniques, mainly identify suspected circuits but lack the ability to explain how the decision was arrived at. An explainable methodology and architecture is introduced based on the existing hardware trojan detection features. Results are provided for explaining digital hardware trojans within a netlist using trust-hub trojan benchmarks.
Read more7/8/2024
🏅
0
HackAtari: Atari Learning Environments for Robust and Continual Reinforcement Learning
Quentin Delfosse, Jannis Bluml, Bjarne Gregori, Kristian Kersting
Artificial agents' adaptability to novelty and alignment with intended behavior is crucial for their effective deployment. Reinforcement learning (RL) leverages novelty as a means of exploration, yet agents often struggle to handle novel situations, hindering generalization. To address these issues, we propose HackAtari, a framework introducing controlled novelty to the most common RL benchmark, the Atari Learning Environment. HackAtari allows us to create novel game scenarios (including simplification for curriculum learning), to swap the game elements' colors, as well as to introduce different reward signals for the agent. We demonstrate that current agents trained on the original environments include robustness failures, and evaluate HackAtari's efficacy in enhancing RL agents' robustness and aligning behavior through experiments using C51 and PPO. Overall, HackAtari can be used to improve the robustness of current and future RL algorithms, allowing Neuro-Symbolic RL, curriculum RL, causal RL, as well as LLM-driven RL. Our work underscores the significance of developing interpretable in RL agents.
Read more6/7/2024