An AI Architecture with the Capability to Classify and Explain Hardware Trojans

0
Sign in to get full access
Overview
- An AI architecture capable of detecting and explaining hardware Trojans
- Leverages machine learning techniques like support vector machines
- Aims to provide transparency and interpretability for hardware security
Plain English Explanation
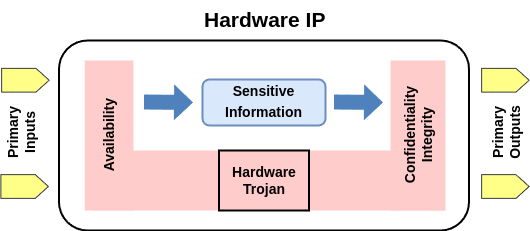
The research paper describes an AI architecture that can detect and explain hardware Trojans. Hardware Trojans are malicious modifications to electronic circuits that can compromise security and functionality.
The proposed architecture uses machine learning, specifically a support vector machine, to classify whether a hardware design contains a Trojan. Importantly, the system also aims to explain its classification decisions in a way that is transparent and interpretable to human users.
By providing this explanation capability, the architecture aims to give users a better understanding of how the system reached its conclusions, rather than treating it as a "black box." This can help build trust and allow for more informed decision-making around hardware security.
Technical Explanation
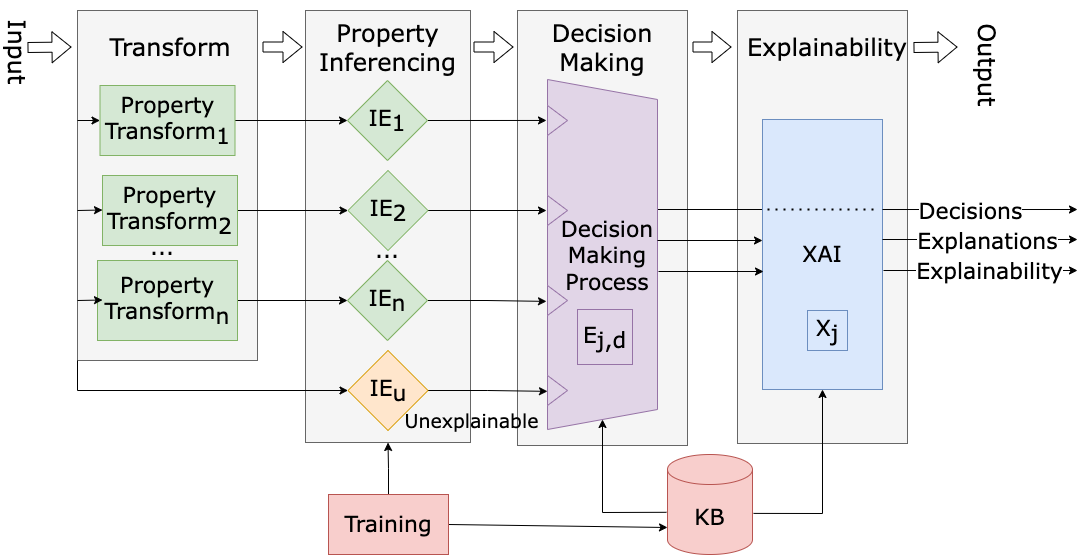
The researchers propose an Explainable Artificial Intelligence (XAI) architecture for detecting and explaining hardware Trojans. The core of the system is a support vector machine (SVM) classifier, trained on a dataset of hardware designs with and without Trojans.
To provide explanations, the system uses a technique called "Contrastive Interpretability Analysis" (CIA). This approach compares the features of a hardware design that is classified as containing a Trojan to those of a "closest" design that is classified as Trojan-free. By highlighting the key differences between these two designs, the CIA module can explain what characteristics led the SVM to its classification decision.
The researchers tested their architecture on a benchmark dataset of hardware Trojans, and found that it was able to accurately classify the Trojans while also providing meaningful explanations for its decisions. These explanations could help hardware designers and security analysts better understand potential vulnerabilities in their systems.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the dataset used for training and evaluation was relatively small, so the performance of the system may not generalize well to larger, more diverse sets of hardware designs. Additionally, the explanations provided by the CIA module, while informative, may not be comprehensive or easily interpretable for all users.
Another potential issue is that the architecture relies on a support vector machine as the core classifier. While SVMs are a well-established machine learning technique, more recent deep learning approaches may be able to achieve higher accuracy and more nuanced explanations.
Overall, the research presents a promising step towards explainable hardware security, but further work is needed to address the limitations and adapt the approach to larger-scale, real-world scenarios.
Conclusion
This research introduces an AI architecture that can detect and explain hardware Trojans, which are a significant threat to the security and reliability of electronic systems. By providing both classification capabilities and transparent, interpretable explanations, the architecture aims to empower hardware designers and security analysts to better understand and mitigate these vulnerabilities.
While the current implementation has some limitations, the overall approach of combining machine learning and explainable AI techniques represents an important step towards more secure and trustworthy hardware systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An AI Architecture with the Capability to Classify and Explain Hardware Trojans
Paul Whitten, Francis Wolff, Chris Papachristou
Hardware trojan detection methods, based on machine learning (ML) techniques, mainly identify suspected circuits but lack the ability to explain how the decision was arrived at. An explainable methodology and architecture is introduced based on the existing hardware trojan detection features. Results are provided for explaining digital hardware trojans within a netlist using trust-hub trojan benchmarks.
Read more7/8/2024

0
TrojanForge: Adversarial Hardware Trojan Examples with Reinforcement Learning
Amin Sarihi, Peter Jamieson, Ahmad Patooghy, Abdel-Hameed A. Badawy
The Hardware Trojan (HT) problem can be thought of as a continuous game between attackers and defenders, each striving to outsmart the other by leveraging any available means for an advantage. Machine Learning (ML) has recently been key in advancing HT research. Various novel techniques, such as Reinforcement Learning (RL) and Graph Neural Networks (GNNs), have shown HT insertion and detection capabilities. HT insertion with ML techniques, specifically, has seen a spike in research activity due to the shortcomings of conventional HT benchmarks and the inherent human design bias that occurs when we create them. This work continues this innovation by presenting a tool called TrojanForge, capable of generating HT adversarial examples that defeat HT detectors; demonstrating the capabilities of GAN-like adversarial tools for automatic HT insertion. We introduce an RL environment where the RL insertion agent interacts with HT detectors in an insertion-detection loop where the agent collects rewards based on its success in bypassing HT detectors. Our results show that this process leads to inserted HTs that evade various HT detectors, achieving high attack success percentages. This tool provides insight into why HT insertion fails in some instances and how we can leverage this knowledge in defense.
Read more5/27/2024
0
An AI Architecture with the Capability to Explain Recognition Results
Paul Whitten, Francis Wolff, Chris Papachristou
Explainability is needed to establish confidence in machine learning results. Some explainable methods take a post hoc approach to explain the weights of machine learning models, others highlight areas of the input contributing to decisions. These methods do not adequately explain decisions, in plain terms. Explainable property-based systems have been shown to provide explanations in plain terms, however, they have not performed as well as leading unexplainable machine learning methods. This research focuses on the importance of metrics to explainability and contributes two methods yielding performance gains. The first method introduces a combination of explainable and unexplainable flows, proposing a metric to characterize explainability of a decision. The second method compares classic metrics for estimating the effectiveness of neural networks in the system, posing a new metric as the leading performer. Results from the new methods and examples from handwritten datasets are presented.
Read more7/4/2024

0
Explainable Malware Detection with Tailored Logic Explained Networks
Peter Anthony, Francesco Giannini, Michelangelo Diligenti, Martin Homola, Marco Gori, Stefan Balogh, Jan Mojzis
Malware detection is a constant challenge in cybersecurity due to the rapid development of new attack techniques. Traditional signature-based approaches struggle to keep pace with the sheer volume of malware samples. Machine learning offers a promising solution, but faces issues of generalization to unseen samples and a lack of explanation for the instances identified as malware. However, human-understandable explanations are especially important in security-critical fields, where understanding model decisions is crucial for trust and legal compliance. While deep learning models excel at malware detection, their black-box nature hinders explainability. Conversely, interpretable models often fall short in performance. To bridge this gap in this application domain, we propose the use of Logic Explained Networks (LENs), which are a recently proposed class of interpretable neural networks providing explanations in the form of First-Order Logic (FOL) rules. This paper extends the application of LENs to the complex domain of malware detection, specifically using the large-scale EMBER dataset. In the experimental results we show that LENs achieve robustness that exceeds traditional interpretable methods and that are rivaling black-box models. Moreover, we introduce a tailored version of LENs that is shown to generate logic explanations with higher fidelity with respect to the model's predictions.
Read more5/7/2024