Trustworthiness in Retrieval-Augmented Generation Systems: A Survey

0

Sign in to get full access
Overview
- Trustworthiness is a crucial aspect of retrieval-augmented generation systems, which combine language models with information retrieval.
- This paper provides a comprehensive survey of the current research on trustworthiness in these systems.
- Key topics covered include sources of untrustworthiness, methods for improving trustworthiness, and evaluation of trustworthiness.
Plain English Explanation
Retrieval-augmented generation systems are a type of AI model that combines a language model, which can generate human-like text, with an information retrieval system, which can find relevant information from a large database. These systems are used for tasks like answering questions, summarizing documents, and generating content.
However, the trustworthiness of these systems is an important concern. There are various ways that they can produce unreliable or misleading outputs, such as hallucinating information, repeating biases in the training data, or misunderstanding the context. This paper reviews the current research on how to identify and address these trustworthiness issues.
The paper discusses methods for improving trustworthiness, such as better retrieval algorithms, transparency about the model's reasoning, and techniques to detect and mitigate hallucinations. It also covers ways to evaluate the trustworthiness of these systems, such as testing them on fact-checking tasks or having humans assess the reliability of the outputs.
Overall, the goal is to make retrieval-augmented generation systems more reliable and trustworthy so that they can be safely used for important applications like healthcare, finance, and education. By understanding the sources of untrustworthiness and developing techniques to address them, researchers hope to unlock the full potential of these powerful AI models.
Technical Explanation
The paper begins by defining the key concepts of trustworthiness and retrieval-augmented generation systems. It then provides a taxonomy of the different sources of untrustworthiness in these systems, including:
- Retrieval quality issues, where the retriever fails to find relevant information
- Encoding and decoding errors, where the language model misunderstands or misrepresents the retrieved information
- Hallucination, where the model generates content not supported by the retrieval
- [Biases and inconsistencies in the training data or model
The paper then reviews various techniques that have been proposed to improve the trustworthiness of these systems, such as:
- Improved retrieval algorithms to surface more relevant and accurate information
- Transparency mechanisms to explain the model's reasoning and sources of information
- Methods to detect and mitigate hallucination and other forms of untrustworthiness
Finally, the paper discusses approaches for evaluating the trustworthiness of retrieval-augmented generation systems, including human evaluation, fact-checking tasks, and other diagnostic tests.
Critical Analysis
The paper provides a comprehensive overview of the current state of research on trustworthiness in retrieval-augmented generation systems. However, it also acknowledges several important limitations and areas for further work:
- The evaluation of trustworthiness is still an open challenge, as there is no consensus on the best metrics or benchmarks to use.
- The techniques proposed for improving trustworthiness have not yet been thoroughly tested at scale on real-world applications.
- The paper does not address the potential societal impacts and ethical considerations around the use of these systems, such as the risk of amplifying biases or generating misinformation.
Further research is needed to develop more robust and reliable methods for ensuring the trustworthiness of retrieval-augmented generation systems, particularly as they become more widely deployed in high-stakes domains. Ongoing collaboration between researchers, developers, and end-users will be crucial to addressing these challenges.
Conclusion
This survey paper provides a valuable synthesis of the current research on trustworthiness in retrieval-augmented generation systems. By understanding the sources of untrustworthiness and the techniques for mitigating them, researchers and practitioners can work towards developing more reliable and transparent AI systems that can be safely deployed in a wide range of applications. As these technologies continue to advance, maintaining trustworthiness will be a critical priority for ensuring their responsible and beneficial use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Trustworthiness in Retrieval-Augmented Generation Systems: A Survey
Yujia Zhou, Yan Liu, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Zheng Liu, Chaozhuo Li, Zhicheng Dou, Tsung-Yi Ho, Philip S. Yu
Retrieval-Augmented Generation (RAG) has quickly grown into a pivotal paradigm in the development of Large Language Models (LLMs). While much of the current research in this field focuses on performance optimization, particularly in terms of accuracy and efficiency, the trustworthiness of RAG systems remains an area still under exploration. From a positive perspective, RAG systems are promising to enhance LLMs by providing them with useful and up-to-date knowledge from vast external databases, thereby mitigating the long-standing problem of hallucination. While from a negative perspective, RAG systems are at the risk of generating undesirable contents if the retrieved information is either inappropriate or poorly utilized. To address these concerns, we propose a unified framework that assesses the trustworthiness of RAG systems across six key dimensions: factuality, robustness, fairness, transparency, accountability, and privacy. Within this framework, we thoroughly review the existing literature on each dimension. Additionally, we create the evaluation benchmark regarding the six dimensions and conduct comprehensive evaluations for a variety of proprietary and open-source models. Finally, we identify the potential challenges for future research based on our investigation results. Through this work, we aim to lay a structured foundation for future investigations and provide practical insights for enhancing the trustworthiness of RAG systems in real-world applications.
Read more9/17/2024
⛏️
0
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
Retrieval-Augmented Generation (RAG) has recently gained traction in natural language processing. Numerous studies and real-world applications are leveraging its ability to enhance generative models through external information retrieval. Evaluating these RAG systems, however, poses unique challenges due to their hybrid structure and reliance on dynamic knowledge sources. To better understand these challenges, we conduct A Unified Evaluation Process of RAG (Auepora) and aim to provide a comprehensive overview of the evaluation and benchmarks of RAG systems. Specifically, we examine and compare several quantifiable metrics of the Retrieval and Generation components, such as relevance, accuracy, and faithfulness, within the current RAG benchmarks, encompassing the possible output and ground truth pairs. We then analyze the various datasets and metrics, discuss the limitations of current benchmarks, and suggest potential directions to advance the field of RAG benchmarks.
Read more7/4/2024

0
A Survey on Retrieval-Augmented Text Generation for Large Language Models
Yizheng Huang, Jimmy Huang
Retrieval-Augmented Generation (RAG) merges retrieval methods with deep learning advancements to address the static limitations of large language models (LLMs) by enabling the dynamic integration of up-to-date external information. This methodology, focusing primarily on the text domain, provides a cost-effective solution to the generation of plausible but possibly incorrect responses by LLMs, thereby enhancing the accuracy and reliability of their outputs through the use of real-world data. As RAG grows in complexity and incorporates multiple concepts that can influence its performance, this paper organizes the RAG paradigm into four categories: pre-retrieval, retrieval, post-retrieval, and generation, offering a detailed perspective from the retrieval viewpoint. It outlines RAG's evolution and discusses the field's progression through the analysis of significant studies. Additionally, the paper introduces evaluation methods for RAG, addressing the challenges faced and proposing future research directions. By offering an organized framework and categorization, the study aims to consolidate existing research on RAG, clarify its technological underpinnings, and highlight its potential to broaden the adaptability and applications of LLMs.
Read more8/26/2024
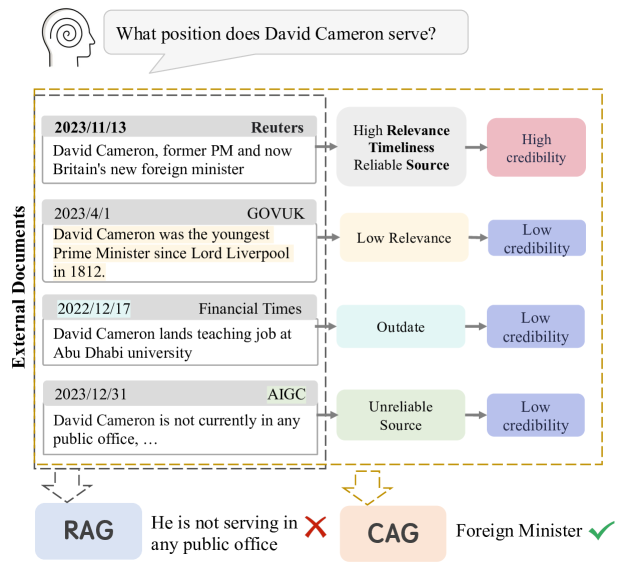
0
Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation
Ruotong Pan, Boxi Cao, Hongyu Lin, Xianpei Han, Jia Zheng, Sirui Wang, Xunliang Cai, Le Sun
The rapid development of large language models has led to the widespread adoption of Retrieval-Augmented Generation (RAG), which integrates external knowledge to alleviate knowledge bottlenecks and mitigate hallucinations. However, the existing RAG paradigm inevitably suffers from the impact of flawed information introduced during the retrieval phrase, thereby diminishing the reliability and correctness of the generated outcomes. In this paper, we propose Credibility-aware Generation (CAG), a universally applicable framework designed to mitigate the impact of flawed information in RAG. At its core, CAG aims to equip models with the ability to discern and process information based on its credibility. To this end, we propose an innovative data transformation framework that generates data based on credibility, thereby effectively endowing models with the capability of CAG. Furthermore, to accurately evaluate the models' capabilities of CAG, we construct a comprehensive benchmark covering three critical real-world scenarios. Experimental results demonstrate that our model can effectively understand and utilize credibility for generation, significantly outperform other models with retrieval augmentation, and exhibit resilience against the disruption caused by noisy documents, thereby maintaining robust performance. Moreover, our model supports customized credibility, offering a wide range of potential applications.
Read more5/10/2024