TSCM: A Teacher-Student Model for Vision Place Recognition Using Cross-Metric Knowledge Distillation

0

Sign in to get full access
Overview
- The paper proposes a novel "Teacher-Student Cross-Metric" (TSCM) model for vision place recognition, which uses cross-metric knowledge distillation to train a smaller student model to match the performance of a larger teacher model.
- The key idea is to leverage the teacher's superior performance on a metric-learning based place recognition task to guide the training of the student model.
- This approach allows the student model to achieve comparable accuracy to the teacher model, while being more efficient and deployable on resource-constrained devices.
Plain English Explanation
The paper describes a new way to train vision-based place recognition models. Place recognition is the task of determining the specific location or "place" that a camera is viewing, which is an important capability for applications like robot navigation and augmented reality.
Typically, state-of-the-art place recognition models are large, complex neural networks that perform very well but require a lot of computing power. This can make them difficult to deploy on small or mobile devices. The key innovation in this paper is a way to train a smaller, more efficient "student" model to match the performance of a larger, more powerful "teacher" model.
The insight is that the teacher model, with its superior recognition ability, can provide valuable guidance to help train the student model. This "knowledge distillation" process allows the student to learn the essential skills from the teacher, without needing to replicate the full complexity of the teacher model. The result is a student model that achieves comparable accuracy to the teacher, but with much lower computational requirements.
This approach could enable vision-based place recognition to be deployed in a wider range of applications, especially on resource-constrained devices like smartphones or robots. By providing a way to transfer the capabilities of large, powerful models to smaller, more efficient models, it makes advanced computer vision techniques more accessible and usable in the real world.
Technical Explanation
The paper proposes a Teacher-Student Cross-Metric (TSCM) model for vision-based place recognition. The core idea is to leverage the performance of a larger teacher model on a metric-learning based place recognition task to guide the training of a smaller student model.
The teacher model is a state-of-the-art vision model that has been trained to embed place images into a high-dimensional feature space, where images of the same place are close together and images of different places are far apart. This allows the teacher to accurately recognize places by simply comparing the feature vectors of the current image and a database of known places.
The student model has a similar architecture to the teacher, but is designed to be more compact and efficient. During training, the student model not only learns to match the ground-truth place labels, but also to mimic the teacher's feature embeddings through a cross-metric distillation loss. This encourages the student to learn the discriminative place recognition capabilities of the teacher, without needing to fully replicate its complex structure.
Experiments on standard place recognition benchmarks demonstrate that the student model is able to achieve comparable or even superior accuracy compared to the teacher model, while being significantly more efficient in terms of model size and inference time. This suggests the TSCM approach is an effective way to transfer the knowledge of large, powerful vision models to smaller, more deployable models.
Critical Analysis
The paper provides a thorough evaluation of the TSCM approach, exploring its performance on multiple place recognition datasets and comparing it to various baseline models. The results clearly demonstrate the benefits of the cross-metric knowledge distillation technique, showing that the student model can match or exceed the accuracy of the teacher model while being substantially more efficient.
That said, the paper does acknowledge some limitations of the approach. For example, the performance of the student model is still dependent on the quality of the teacher model, and may not be able to surpass the teacher's capabilities. Additionally, the cross-metric distillation process adds some complexity to the training procedure compared to a standard supervised learning setup.
One area for further research could be exploring ways to make the TSCM approach even more robust and generalizable. For instance, investigating techniques to improve the transfer of knowledge from teacher to student, or examining how the approach performs on a wider variety of vision tasks beyond just place recognition.
Overall, the TSCM model represents an interesting and promising development in the field of vision-based place recognition. By enabling efficient student models to match the performance of larger teacher models, it has the potential to unlock new real-world applications of advanced computer vision on resource-constrained platforms.
Conclusion
The TSCM model proposed in this paper offers an effective approach for training smaller, more efficient vision models to achieve state-of-the-art place recognition performance. By leveraging the superior capabilities of a larger teacher model through cross-metric knowledge distillation, the student model is able to learn the essential skills for accurate place recognition without needing to fully replicate the teacher's complexity.
This technique could have significant implications for deploying advanced vision-based systems, particularly in scenarios where computing resources are limited, such as on mobile devices or embedded systems. By enabling high-performing place recognition on more lightweight models, TSCM could facilitate the integration of these capabilities into a wider range of real-world applications, from robot navigation to augmented reality.
While the paper highlights some potential limitations, the core idea of cross-metric knowledge distillation represents an important step forward in making state-of-the-art computer vision techniques more accessible and deployable. As researchers continue to explore this and related approaches, we may see increasingly powerful yet efficient vision models that can be readily integrated into a diverse array of intelligent systems and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TSCM: A Teacher-Student Model for Vision Place Recognition Using Cross-Metric Knowledge Distillation
Yehui Shen, Mingmin Liu, Huimin Lu, Xieyuanli Chen
Visual place recognition (VPR) plays a pivotal role in autonomous exploration and navigation of mobile robots within complex outdoor environments. While cost-effective and easily deployed, camera sensors are sensitive to lighting and weather changes, and even slight image alterations can greatly affect VPR efficiency and precision. Existing methods overcome this by exploiting powerful yet large networks, leading to significant consumption of computational resources. In this paper, we propose a high-performance teacher and lightweight student distillation framework called TSCM. It exploits our devised cross-metric knowledge distillation to narrow the performance gap between the teacher and student models, maintaining superior performance while enabling minimal computational load during deployment. We conduct comprehensive evaluations on large-scale datasets, namely Pittsburgh30k and Pittsburgh250k. Experimental results demonstrate the superiority of our method over baseline models in terms of recognition accuracy and model parameter efficiency. Moreover, our ablation studies show that the proposed knowledge distillation technique surpasses other counterparts. The code of our method has been released at https://github.com/nubot-nudt/TSCM.
Read more4/3/2024
✨
0
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
Read more4/9/2024
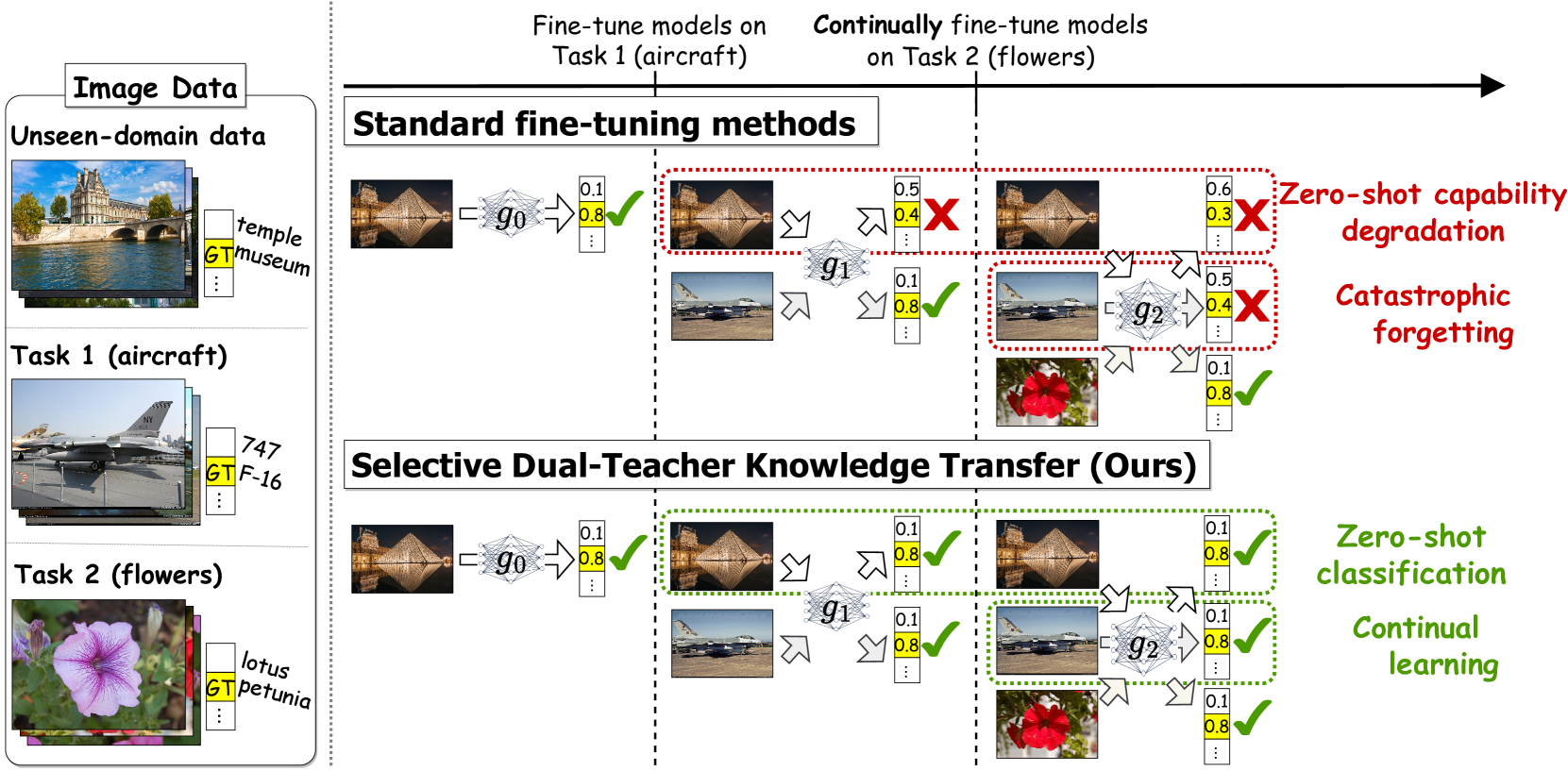
0
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
Yu-Chu Yu, Chi-Pin Huang, Jr-Jen Chen, Kai-Po Chang, Yung-Hsuan Lai, Fu-En Yang, Yu-Chiang Frank Wang
Large-scale vision-language models (VLMs) have shown a strong zero-shot generalization capability on unseen-domain data. However, adapting pre-trained VLMs to a sequence of downstream tasks often leads to the forgetting of previously learned knowledge and a reduction in zero-shot classification performance. To tackle this problem, we propose a unique Selective Dual-Teacher Knowledge Transfer framework that leverages the most recent fine-tuned and the original pre-trained VLMs as dual teachers to preserve the previously learned knowledge and zero-shot capabilities, respectively. With only access to an unlabeled reference dataset, our proposed framework performs a selective knowledge distillation mechanism by measuring the feature discrepancy from the dual-teacher VLMs. Consequently, our selective dual-teacher knowledge distillation mitigates catastrophic forgetting of previously learned knowledge while preserving the zero-shot capabilities of pre-trained VLMs. Extensive experiments on benchmark datasets demonstrate that our framework is favorable against state-of-the-art continual learning approaches for preventing catastrophic forgetting and zero-shot degradation. Project page: https://chuyu.org/research/snd
Read more7/18/2024

0
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Zaiwei Zhang, Gregory P. Meyer, Zhichao Lu, Ashish Shrivastava, Avinash Ravichandran, Eric M. Wolff
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
Read more9/2/2024