Tuning-free Universally-Supervised Semantic Segmentation
2405.14294
0
0
⛏️
Abstract
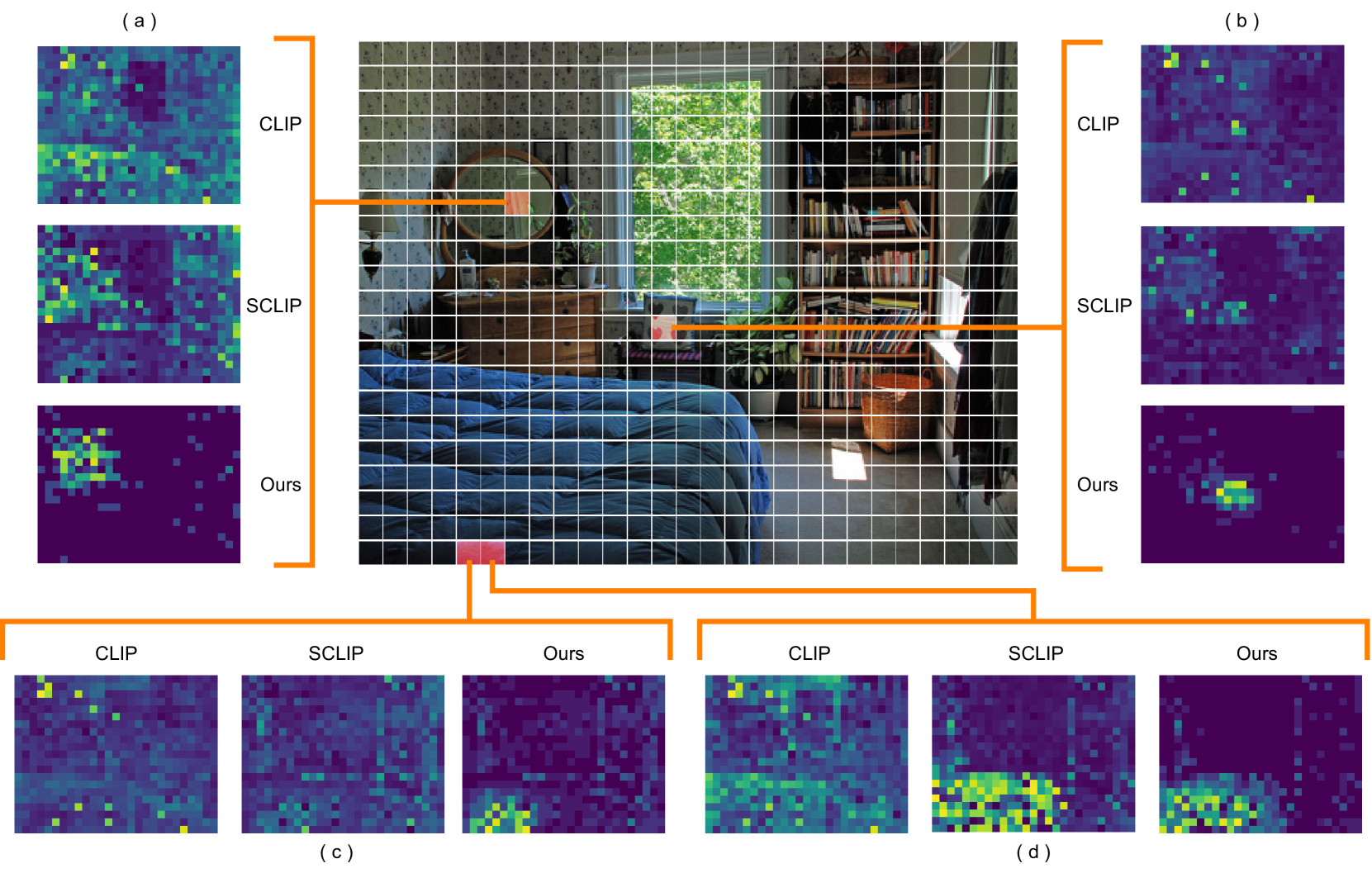
This work presents a tuning-free semantic segmentation framework based on classifying SAM masks by CLIP, which is universally applicable to various types of supervision. Initially, we utilize CLIP's zero-shot classification ability to generate pseudo-labels or perform open-vocabulary segmentation. However, the misalignment between mask and CLIP text embeddings leads to suboptimal results. To address this issue, we propose discrimination-bias aligned CLIP to closely align mask and text embedding, offering an overhead-free performance gain. We then construct a global-local consistent classifier to classify SAM masks, which reveals the intrinsic structure of high-quality embeddings produced by DBA-CLIP and demonstrates robustness against noisy pseudo-labels. Extensive experiments validate the efficiency and effectiveness of our method, and we achieve state-of-the-art (SOTA) or competitive performance across various datasets and supervision types.
Create account to get full access
Overview
- This paper presents a tuning-free semantic segmentation framework that uses the Semantic Attention Mask (SAM) and the CLIP model to perform zero-shot and open-vocabulary segmentation.
- The key innovation is a "discrimination-bias aligned CLIP" (DBA-CLIP) approach, which aligns the mask and text embeddings to improve performance.
- The paper also introduces a global-local consistent classifier to robustly classify the SAM masks, even in the presence of noisy pseudo-labels.
- The framework is shown to achieve state-of-the-art or competitive performance across various datasets and supervision types.
Plain English Explanation
The paper focuses on a new way to do semantic segmentation, which is the process of identifying and labeling different objects or regions in an image. Traditionally, this requires a lot of manual labeling of training data, which can be time-consuming and expensive.
The researchers propose a solution that leverages the CLIP model, a powerful AI system that can recognize and classify objects based on their visual and textual characteristics. By using CLIP's zero-shot classification capabilities, the framework can perform segmentation without needing much labeled training data.
The key innovation is a technique called "discrimination-bias aligned CLIP" (DBA-CLIP), which helps to better align the visual information from the image masks with the textual information from CLIP. This leads to more accurate and robust segmentation results.
The paper also introduces a "global-local consistent classifier" that can classify the segmentation masks, even when the initial pseudo-labels (generated by CLIP) are noisy or imperfect. This makes the overall system more reliable and effective.
Through extensive experiments, the researchers show that their framework can achieve state-of-the-art or highly competitive performance on various segmentation tasks and datasets, without requiring much manual labeling or tuning.
Technical Explanation
The paper starts by leveraging CLIP's zero-shot classification abilities to generate pseudo-labels or perform open-vocabulary segmentation. However, the researchers found that there was a misalignment between the CLIP's text embeddings and the image masks, leading to suboptimal results.
To address this issue, the researchers propose the "discrimination-bias aligned CLIP" (DBA-CLIP) approach. DBA-CLIP closely aligns the mask and text embeddings, offering an overhead-free performance gain. This is achieved by introducing a discrimination-bias loss that encourages the model to learn embeddings that are well-separated for different classes, while also being well-aligned between the mask and text modalities.
The paper then introduces a "global-local consistent classifier" to classify the SAM masks. This classifier leverages the intrinsic structure of the high-quality embeddings produced by DBA-CLIP, and demonstrates robustness against noisy pseudo-labels.
Through extensive experiments on various datasets and supervision types, the researchers validate the efficiency and effectiveness of their method. They achieve state-of-the-art (SOTA) or competitive performance across the board, showcasing the versatility and power of their tuning-free semantic segmentation framework.
Critical Analysis
The paper presents a well-designed and comprehensive solution to the challenge of semantic segmentation, particularly in the context of limited labeled data. The key innovations, such as DBA-CLIP and the global-local consistent classifier, appear to be well-conceived and effectively implemented.
One potential limitation of the approach is its reliance on the CLIP model, which may introduce certain biases or limitations inherent in the pre-trained CLIP system. Additionally, the paper does not explore the performance of the framework in more challenging or diverse real-world scenarios, where the robustness and generalization of the system may be further tested.
Furthermore, the paper could have delved deeper into the potential societal implications and ethical considerations of a tuning-free segmentation system, particularly in domains where biased or inaccurate segmentation could have significant consequences.
Overall, the research presented in this paper is a valuable contribution to the field of semantic segmentation, and the proposed framework demonstrates the potential of leveraging pre-trained models and novel architectural choices to enable robust and efficient segmentation tasks. As the authors suggest, further exploration of the framework's limitations and potential extensions could lead to even more impactful developments in this important area of computer vision.
Conclusion
This paper introduces a tuning-free semantic segmentation framework that leverages the power of the CLIP model and a novel "discrimination-bias aligned CLIP" (DBA-CLIP) approach to perform zero-shot and open-vocabulary segmentation. The key innovations, including the global-local consistent classifier, enable the framework to achieve state-of-the-art or highly competitive performance across various datasets and supervision types.
The research presented in this paper highlights the potential of combining pre-trained models, such as CLIP, with carefully designed architectural choices to tackle challenging computer vision problems, even in the absence of extensive labeled training data. As the authors demonstrate, this tuning-free approach can lead to significant advancements in the field of semantic segmentation, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero shot Medical Image Segmentation
Sidra Aleem, Fangyijie Wang, Mayug Maniparambil, Eric Arazo, Julia Dietlmeier, Guenole Silvestre, Kathleen Curran, Noel E. O'Connor, Suzanne Little
0
0
The Segment Anything Model (SAM) and CLIP are remarkable vision foundation models (VFMs). SAM, a prompt driven segmentation model, excels in segmentation tasks across diverse domains, while CLIP is renowned for its zero shot recognition capabilities. However, their unified potential has not yet been explored in medical image segmentation. To adapt SAM to medical imaging, existing methods primarily rely on tuning strategies that require extensive data or prior prompts tailored to the specific task, making it particularly challenging when only a limited number of data samples are available. This work presents an in depth exploration of integrating SAM and CLIP into a unified framework for medical image segmentation. Specifically, we propose a simple unified framework, SaLIP, for organ segmentation. Initially, SAM is used for part based segmentation within the image, followed by CLIP to retrieve the mask corresponding to the region of interest (ROI) from the pool of SAM generated masks. Finally, SAM is prompted by the retrieved ROI to segment a specific organ. Thus, SaLIP is training and fine tuning free and does not rely on domain expertise or labeled data for prompt engineering. Our method shows substantial enhancements in zero shot segmentation, showcasing notable improvements in DICE scores across diverse segmentation tasks like brain (63.46%), lung (50.11%), and fetal head (30.82%), when compared to un prompted SAM. Code and text prompts are available at: https://github.com/aleemsidra/SaLIP.
5/1/2024
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Sina Hajimiri, Ismail Ben Ayed, Jose Dolz
0
0
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
4/15/2024
➖
Zero Shot Context-Based Object Segmentation using SLIP (SAM+CLIP)
Saaketh Koundinya Gundavarapu, Arushi Arora, Shreya Agarwal
0
0
We present SLIP (SAM+CLIP), an enhanced architecture for zero-shot object segmentation. SLIP combines the Segment Anything Model (SAM) cite{kirillov2023segment} with the Contrastive Language-Image Pretraining (CLIP) cite{radford2021learning}. By incorporating text prompts into SAM using CLIP, SLIP enables object segmentation without prior training on specific classes or categories. We fine-tune CLIP on a Pokemon dataset, allowing it to learn meaningful image-text representations. SLIP demonstrates the ability to recognize and segment objects in images based on contextual information from text prompts, expanding the capabilities of SAM for versatile object segmentation. Our experiments demonstrate the effectiveness of the SLIP architecture in segmenting objects in images based on textual cues. The integration of CLIP's text-image understanding capabilities into SAM expands the capabilities of the original architecture and enables more versatile and context-aware object segmentation.
5/27/2024
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024