Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling

0

Sign in to get full access
Overview
- Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
- Explores a technique called "token recycling" to speed up the inference of large language models
- Demonstrates significant performance gains without compromising model accuracy
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful, but they're also very computationally expensive to run. This can make it challenging to use them in real-world applications where speed and efficiency are important.
The researchers in this paper propose a technique called "token recycling" to help speed up the inference of these large models. The core idea is to reuse the intermediate computations from previous steps, rather than throwing them away and recomputing them from scratch. This allows the model to make predictions more quickly, without compromising the accuracy of the results.
To understand this better, imagine you're trying to translate a sentence from English to French. As you process each word, you build up an understanding of the overall meaning. With token recycling, instead of discarding that intermediate knowledge, you can reuse it to help translate the next word more efficiently.
The researchers demonstrate that by applying token recycling, they're able to achieve significant speedups in model inference - in some cases, the model runs 2-3x faster. This could make it much more practical to deploy large language models in real-world applications where latency is a concern, such as chatbots, virtual assistants, or text generation tools.
Technical Explanation
The key innovation in this paper is the "token recycling" technique, which allows large language models to reuse intermediate computations from previous steps during the inference process. Traditionally, when a language model generates text, it processes each token (word) sequentially, discarding the intermediate representations after they're no longer needed.
With token recycling, the model keeps track of these intermediate representations and reuses them later on, rather than recomputing them from scratch. This is accomplished by maintaining a "recycling buffer" that stores the relevant activations at each step. When predicting the next token, the model can draw from this buffer to avoid redundant computations.
The researchers evaluate their approach on a variety of large language models, including GPT-2, GPT-3, and T5. They show that token recycling provides significant speedups, with inference times reduced by 2-3x in many cases. Importantly, this performance boost is achieved without any loss of model accuracy - the final outputs are identical to the original models.
The authors also explore different strategies for managing the recycling buffer, such as selectively storing only the most important activations. This allows them to balance the performance gains against the memory overhead required to store the intermediate representations.
Critical Analysis
The token recycling technique proposed in this paper is a clever and promising approach to accelerating the inference of large language models. By intelligently reusing intermediate computations, the researchers are able to achieve substantial speedups without compromising model accuracy.
That said, there are a few potential limitations and areas for further exploration:
-
Memory Overhead: Maintaining the recycling buffer introduces additional memory requirements, which could be a concern for deployment on resource-constrained devices. The authors explore techniques to mitigate this, but it remains an important consideration.
-
Generalizability: The experiments in the paper focus on a relatively narrow set of language models and tasks. It would be valuable to see how well the token recycling approach generalizes to a broader range of LLMs and applications.
-
Real-World Deployment: While the paper demonstrates impressive speedups in a research setting, the true test will be how well the technique performs in real-world, production-level deployments, where factors like system integration and model versioning come into play.
-
Interaction with Other Optimizations: It would be interesting to understand how token recycling interacts with other techniques for accelerating LLM inference, such as quantization, pruning, or distillation. Combining these approaches could lead to even greater performance gains.
Overall, the token recycling technique presented in this paper is a promising step forward in making large language models more practically usable in a wide range of applications. As the authors note, continued research in this area could have substantial benefits for the field of natural language processing and beyond.
Conclusion
The "Turning Trash into Treasure" paper introduces a novel token recycling technique that can significantly accelerate the inference of large language models without sacrificing model accuracy. By intelligently reusing intermediate computations, the researchers demonstrate speedups of 2-3x on a variety of LLMs, including GPT-2, GPT-3, and T5.
This work has important implications for the real-world deployment of powerful language models, as it helps address the computational challenges that have often limited their practical use. By making LLMs more efficient and responsive, the token recycling approach could enable a new wave of applications that leverage these models' impressive language understanding capabilities.
While the paper highlights some potential limitations around memory overhead and generalizability, the core idea is a compelling one that deserves further exploration. As the field of natural language processing continues to advance, techniques like token recycling will likely play an important role in bridging the gap between research breakthroughs and practical, widely-adopted solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
Xianzhen Luo, Yixuan Wang, Qingfu Zhu, Zhiming Zhang, Xuanyu Zhang, Qing Yang, Dongliang Xu, Wanxiang Che
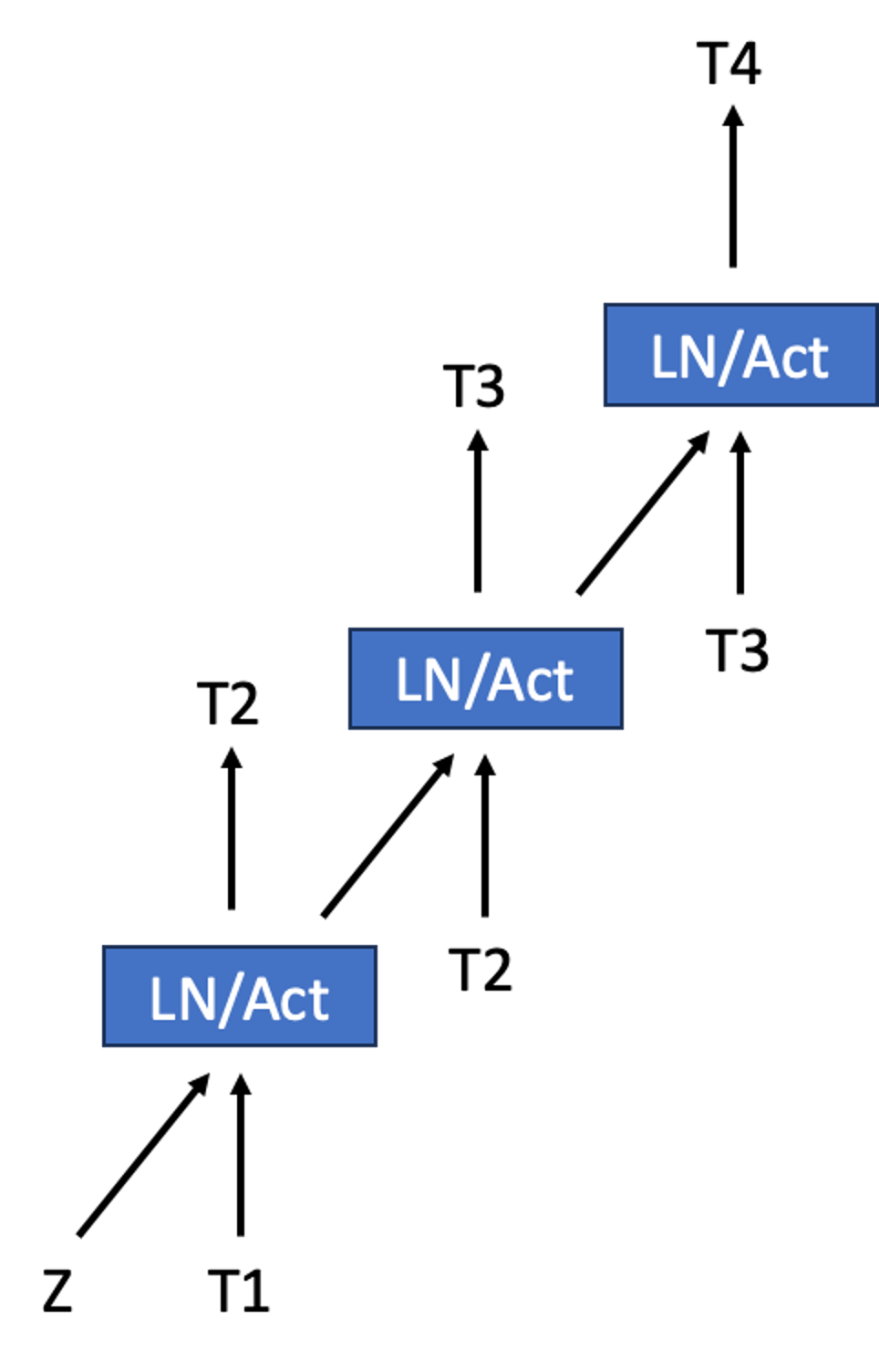
The rapid growth in the parameters of large language models (LLMs) has made inference latency a fundamental bottleneck, limiting broader application of LLMs. Speculative decoding represents a lossless approach to accelerate inference through a guess-and-verify paradigm, leveraging the parallel capabilities of modern hardware. Some speculative decoding methods rely on additional structures to guess draft tokens, such as small models or parameter-efficient architectures, which need extra training before use. Alternatively, retrieval-based train-free techniques build libraries from pre-existing corpora or by n-gram generation. However, they face challenges like large storage requirements, time-consuming retrieval, and limited adaptability. Observing that candidate tokens generated during the decoding process are likely to reoccur in future sequences, we propose Token Recycling. This approach stores candidate tokens in an adjacency matrix and employs a breadth-first search (BFS)-like algorithm on the matrix to construct a draft tree. The tree is then validated through tree attention. New candidate tokens from the decoding process are then used to update the matrix. Token Recycling requires textless2MB of additional storage and achieves approximately 2x speedup across all sizes of LLMs. It significantly outperforms existing train-free methods by 30% and even a training method by 25%. It can be directly applied to any existing LLMs and tasks without the need for adaptation.
Read more8/19/2024
0
Accelerating Production LLMs with Combined Token/Embedding Speculators
Davis Wertheimer, Joshua Rosenkranz, Thomas Parnell, Sahil Suneja, Pavithra Ranganathan, Raghu Ganti, Mudhakar Srivatsa
This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
Read more6/10/2024
💬
0
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, Sharad Mehrotra
We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage process: drafting and verification. The drafting stage generates draft tokens at a slightly lower quality but more quickly, which is achieved by selectively skipping certain intermediate layers during drafting. Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass. This process ensures the final output remains identical to that produced by the unaltered LLM. Moreover, the proposed method requires no additional neural network training and no extra memory footprint, making it a plug-and-play and cost-effective solution for inference acceleration. Benchmarks with LLaMA-2 and its variants demonstrated a speedup up to 1.99$times$.
Read more5/21/2024
0
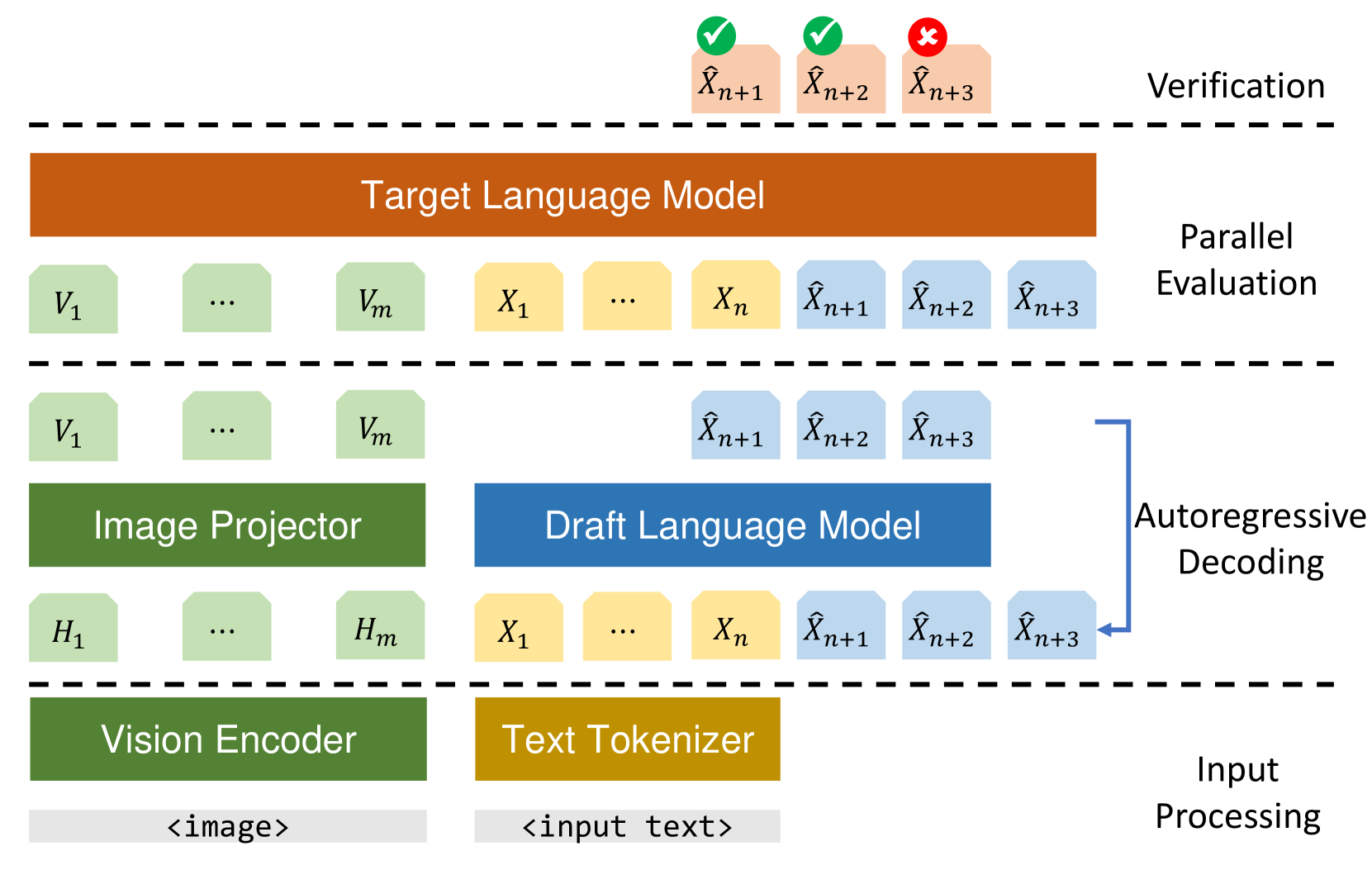
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Read more4/16/2024