Twins-PainViT: Towards a Modality-Agnostic Vision Transformer Framework for Multimodal Automatic Pain Assessment using Facial Videos and fNIRS

0
Sign in to get full access
Overview
- Presents a multimodal deep learning framework called Twins-PainViT for automatic pain assessment using facial videos and functional near-infrared spectroscopy (fNIRS) data.
- Leverages a modality-agnostic Vision Transformer (ViT) architecture to fuse information from these two modalities.
- Explores multi-task learning to jointly predict pain intensity and binary pain detection.
- Demonstrates state-of-the-art performance on the UNBC-McMaster Shoulder Pain Expression Archive dataset.
Plain English Explanation
The paper introduces a new deep learning system called Twins-PainViT for automatically assessing a person's level of pain. This system uses two types of data: facial videos and functional near-infrared spectroscopy (fNIRS) brain scans.
The key innovation is the use of a Vision Transformer (ViT) architecture, which allows the system to effectively combine and make sense of these two very different data modalities. The system is trained to jointly predict both the intensity of pain and whether pain is present or not, using a multi-task learning approach.
The researchers show that this Twins-PainViT system achieves state-of-the-art performance on a standard pain assessment dataset, outperforming previous methods that used either facial videos or fNIRS data alone. This suggests the power of combining multiple data sources and modalities to gain a more complete understanding of a person's pain experience.
Technical Explanation
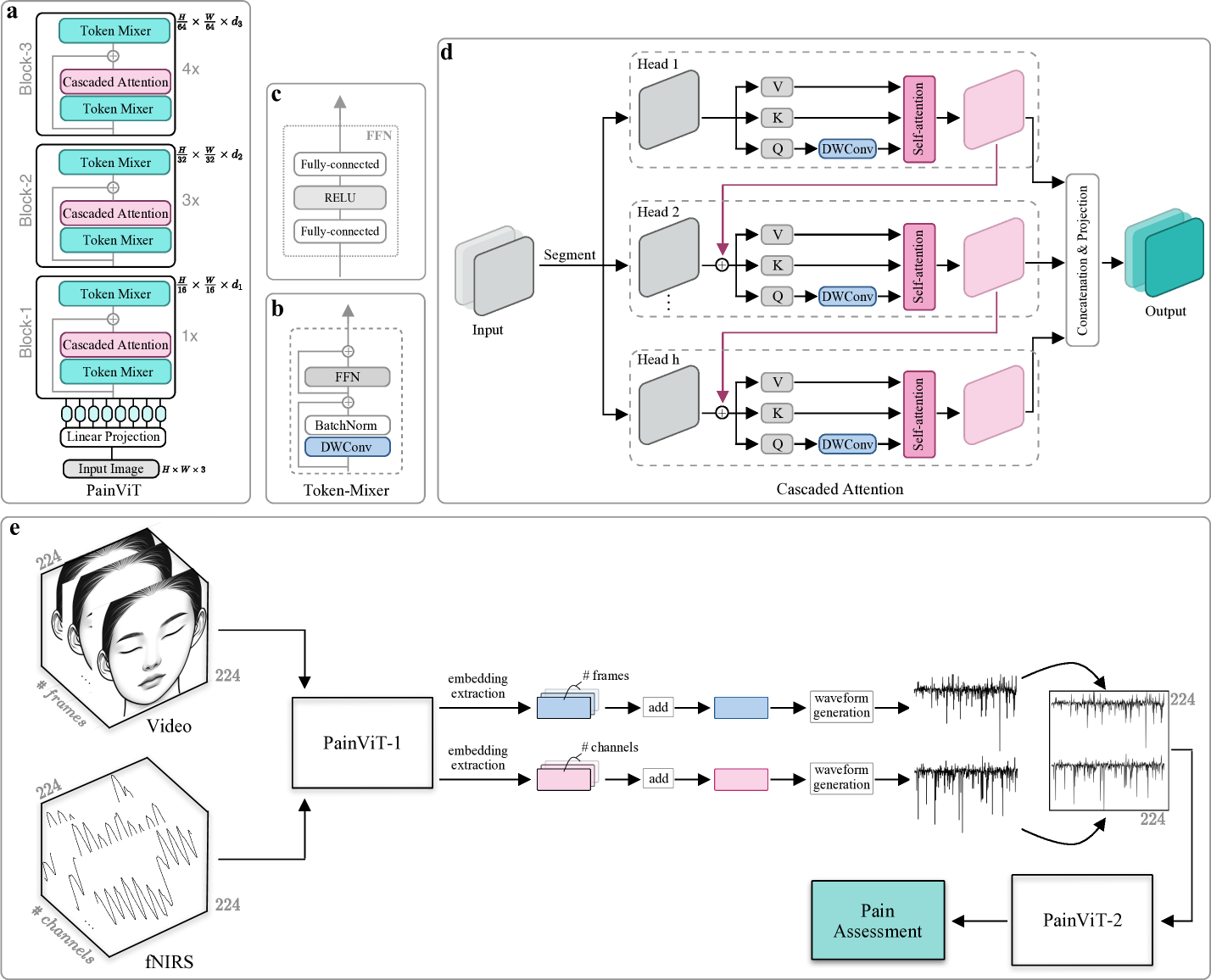
The Twins-PainViT framework uses a modality-agnostic Vision Transformer (ViT) architecture to fuse information from facial videos and fNIRS brain scans for automatic pain assessment. The ViT model processes each modality independently, extracting relevant features, before combining the representations through cross-attention mechanisms.
This multimodal fusion is then used for two related pain prediction tasks: 1) estimating the intensity of pain on a continuous scale, and 2) detecting the binary presence or absence of pain. The model is trained in a multi-task learning setting, allowing the shared ViT backbone to learn robust representations that benefit both tasks.
The researchers evaluate Twins-PainViT on the UNBC-McMaster Shoulder Pain Expression Archive dataset, which contains facial videos and fNIRS recordings of participants experiencing shoulder pain. Twins-PainViT outperforms previous state-of-the-art methods that used either modality alone, demonstrating the value of the multimodal fusion approach.
Critical Analysis
The paper provides a compelling demonstration of the advantages of multimodal deep learning for automatic pain assessment. By combining complementary information from facial expressions and brain activity, the Twins-PainViT framework is able to make more accurate and robust predictions than unimodal approaches.
However, the dataset used in the evaluation is relatively small, with only 200 participants. While the results are promising, it will be important to validate the approach on larger and more diverse datasets to ensure its generalizability. Additionally, the pain assessment tasks considered are relatively narrow in scope, focusing only on intensity and binary detection. Expanding the framework to handle a broader range of pain-related outcomes could further enhance its clinical utility.
Another potential limitation is the black-box nature of the ViT architecture, which can make it challenging to interpret the model's decision-making process. Incorporating more interpretable components or providing additional model introspection tools could help clinicians and researchers better understand how the system is arriving at its pain assessments.
Conclusion
The Twins-PainViT framework represents an important step forward in the development of multimodal deep learning systems for automatic pain assessment. By leveraging the complementary strengths of facial videos and fNIRS data, the model is able to achieve state-of-the-art performance on standard benchmarks.
This research highlights the potential of combining multiple data modalities to gain a more comprehensive understanding of the complex human experience of pain. As the field of pain assessment continues to evolve, approaches like Twins-PainViT may play an increasingly crucial role in improving clinical diagnosis, monitoring, and treatment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Twins-PainViT: Towards a Modality-Agnostic Vision Transformer Framework for Multimodal Automatic Pain Assessment using Facial Videos and fNIRS
Stefanos Gkikas, Manolis Tsiknakis
Automatic pain assessment plays a critical role for advancing healthcare and optimizing pain management strategies. This study has been submitted to the First Multimodal Sensing Grand Challenge for Next-Gen Pain Assessment (AI4PAIN). The proposed multimodal framework utilizes facial videos and fNIRS and presents a modality-agnostic approach, alleviating the need for domain-specific models. Employing a dual ViT configuration and adopting waveform representations for the fNIRS, as well as for the extracted embeddings from the two modalities, demonstrate the efficacy of the proposed method, achieving an accuracy of 46.76% in the multilevel pain assessment task.
Read more7/30/2024

0
Synthetic Thermal and RGB Videos for Automatic Pain Assessment utilizing a Vision-MLP Architecture
Stefanos Gkikas, Manolis Tsiknakis
Pain assessment is essential in developing optimal pain management protocols to alleviate suffering and prevent functional decline in patients. Consequently, reliable and accurate automatic pain assessment systems are essential for continuous and effective patient monitoring. This study presents synthetic thermal videos generated by Generative Adversarial Networks integrated into the pain recognition pipeline and evaluates their efficacy. A framework consisting of a Vision-MLP and a Transformer-based module is utilized, employing RGB and synthetic thermal videos in unimodal and multimodal settings. Experiments conducted on facial videos from the BioVid database demonstrate the effectiveness of synthetic thermal videos and underline the potential advantages of it.
Read more7/30/2024
0
Transformer with Leveraged Masked Autoencoder for video-based Pain Assessment
Minh-Duc Nguyen, Hyung-Jeong Yang, Soo-Hyung Kim, Ji-Eun Shin, Seung-Won Kim
Accurate pain assessment is crucial in healthcare for effective diagnosis and treatment; however, traditional methods relying on self-reporting are inadequate for populations unable to communicate their pain. Cutting-edge AI is promising for supporting clinicians in pain recognition using facial video data. In this paper, we enhance pain recognition by employing facial video analysis within a Transformer-based deep learning model. By combining a powerful Masked Autoencoder with a Transformers-based classifier, our model effectively captures pain level indicators through both expressions and micro-expressions. We conducted our experiment on the AI4Pain dataset, which produced promising results that pave the way for innovative healthcare solutions that are both comprehensive and objective.
Read more9/10/2024

0
Advancing Multimodal Data Fusion in Pain Recognition: A Strategy Leveraging Statistical Correlation and Human-Centered Perspectives
Xingrui Gu, Zhixuan Wang, Irisa Jin, Zekun Wu
This research presents a novel multimodal data fusion methodology for pain behavior recognition, integrating statistical correlation analysis with human-centered insights. Our approach introduces two key innovations: 1) integrating data-driven statistical relevance weights into the fusion strategy to effectively utilize complementary information from heterogeneous modalities, and 2) incorporating human-centric movement characteristics into multimodal representation learning for detailed modeling of pain behaviors. Validated across various deep learning architectures, our method demonstrates superior performance and broad applicability. We propose a customizable framework that aligns each modality with a suitable classifier based on statistical significance, advancing personalized and effective multimodal fusion. Furthermore, our methodology provides explainable analysis of multimodal data, contributing to interpretable and explainable AI in healthcare. By highlighting the importance of data diversity and modality-specific representations, we enhance traditional fusion techniques and set new standards for recognizing complex pain behaviors. Our findings have significant implications for promoting patient-centered healthcare interventions and supporting explainable clinical decision-making.
Read more8/2/2024