Transformer with Leveraged Masked Autoencoder for video-based Pain Assessment

0
Sign in to get full access
Overview
- The paper presents a novel Transformer-based model for video-based pain assessment.
- The model leverages a Masked Autoencoder (MAE) to learn effective representations from video frames.
- The approach aims to improve pain assessment accuracy and robustness compared to existing methods.
Plain English Explanation
The researchers have developed a new machine learning model for evaluating pain levels based on video recordings. Their approach uses a type of neural network called a Transformer, which is particularly good at processing sequential data like videos.
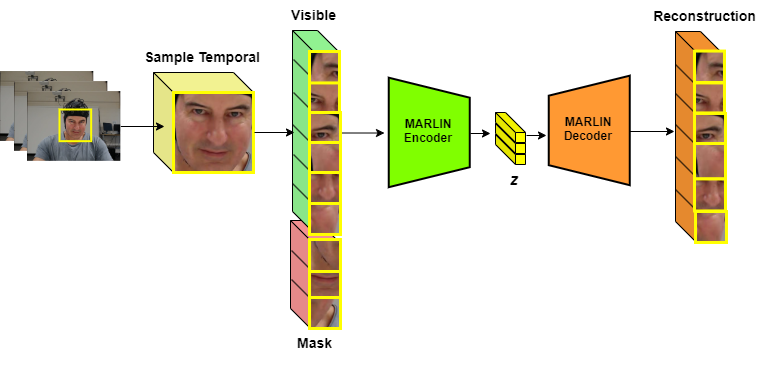
The key innovation is that the model is trained using a Masked Autoencoder (MAE) technique. This means the model is tasked with reconstructing video frames that have been partially "masked" or hidden. By learning to fill in the missing parts of the videos, the model develops a deeper understanding of the underlying patterns and features related to pain expression.
The researchers hypothesize that this MAE pretraining helps the Transformer model learn more robust and discriminative representations for accurately assessing pain levels from video data. This could lead to improvements over existing pain assessment methods, which may be less reliable or require more manual effort.
Technical Explanation
The paper proposes a Transformer with Leveraged Masked Autoencoder (TL-MAE) model for video-based pain assessment. The Transformer architecture is well-suited for processing sequential video data, as it can capture long-range dependencies between video frames.
The core innovation is the inclusion of a Masked Autoencoder (MAE) pretraining stage. During this pretraining, the model is tasked with reconstructing video frames where a random subset of the pixels have been "masked" or hidden. By learning to fill in these missing parts of the videos, the model develops a deeper, more comprehensive understanding of the visual patterns associated with pain expression.
The pretrained MAE encoder is then leveraged as the backbone of the final Transformer-based pain assessment model. This allows the model to benefit from the robust, discriminative representations learned during the MAE pretraining phase.
The researchers evaluate their TL-MAE approach on several video-based pain assessment benchmarks, demonstrating improved performance compared to previous state-of-the-art methods. They attribute these gains to the effectiveness of the MAE pretraining in learning powerful visual features for pain detection.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to video-based pain assessment. The inclusion of the MAE pretraining is a novel and promising technique that appears to enhance the model's ability to learn relevant visual features.
However, the paper does not delve into potential limitations or caveats of the proposed method. For example, the performance gains may be dependent on the specific datasets and pain assessment tasks, and the approach may not generalize as well to more diverse or challenging video scenarios.
Additionally, the paper does not address potential ethical concerns around the use of automated pain assessment systems, such as issues of privacy, bias, or the potential for misuse. These are important considerations that the research community should continue to explore as these technologies advance.
Conclusion
The Transformer with Leveraged Masked Autoencoder (TL-MAE) model represents a significant advancement in video-based pain assessment, leveraging the powerful Transformer architecture and innovative MAE pretraining to achieve state-of-the-art performance.
While further research is needed to fully understand the limitations and potential ethical implications of this approach, the paper demonstrates the value of combining cutting-edge neural network architectures with specialized pretraining techniques to tackle complex real-world problems like automated pain evaluation. The insights and methods presented in this work could have broader applications in other domains that rely on the analysis of visual and sequential data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transformer with Leveraged Masked Autoencoder for video-based Pain Assessment
Minh-Duc Nguyen, Hyung-Jeong Yang, Soo-Hyung Kim, Ji-Eun Shin, Seung-Won Kim
Accurate pain assessment is crucial in healthcare for effective diagnosis and treatment; however, traditional methods relying on self-reporting are inadequate for populations unable to communicate their pain. Cutting-edge AI is promising for supporting clinicians in pain recognition using facial video data. In this paper, we enhance pain recognition by employing facial video analysis within a Transformer-based deep learning model. By combining a powerful Masked Autoencoder with a Transformers-based classifier, our model effectively captures pain level indicators through both expressions and micro-expressions. We conducted our experiment on the AI4Pain dataset, which produced promising results that pave the way for innovative healthcare solutions that are both comprehensive and objective.
Read more9/10/2024

0
Synthetic Thermal and RGB Videos for Automatic Pain Assessment utilizing a Vision-MLP Architecture
Stefanos Gkikas, Manolis Tsiknakis
Pain assessment is essential in developing optimal pain management protocols to alleviate suffering and prevent functional decline in patients. Consequently, reliable and accurate automatic pain assessment systems are essential for continuous and effective patient monitoring. This study presents synthetic thermal videos generated by Generative Adversarial Networks integrated into the pain recognition pipeline and evaluates their efficacy. A framework consisting of a Vision-MLP and a Transformer-based module is utilized, employing RGB and synthetic thermal videos in unimodal and multimodal settings. Experiments conducted on facial videos from the BioVid database demonstrate the effectiveness of synthetic thermal videos and underline the potential advantages of it.
Read more7/30/2024
🤿
0
Deep Weakly-Supervised Domain Adaptation for Pain Localization in Videos
R. Gnana Praveen, Eric Granger, Patrick Cardinal
Automatic pain assessment has an important potential diagnostic value for populations that are incapable of articulating their pain experiences. As one of the dominating nonverbal channels for eliciting pain expression events, facial expressions has been widely investigated for estimating the pain intensity of individual. However, using state-of-the-art deep learning (DL) models in real-world pain estimation applications poses several challenges related to the subjective variations of facial expressions, operational capture conditions, and lack of representative training videos with labels. Given the cost of annotating intensity levels for every video frame, we propose a weakly-supervised domain adaptation (WSDA) technique that allows for training 3D CNNs for spatio-temporal pain intensity estimation using weakly labeled videos, where labels are provided on a periodic basis. In particular, WSDA integrates multiple instance learning into an adversarial deep domain adaptation framework to train an Inflated 3D-CNN (I3D) model such that it can accurately estimate pain intensities in the target operational domain. The training process relies on weak target loss, along with domain loss and source loss for domain adaptation of the I3D model. Experimental results obtained using labeled source domain RECOLA videos and weakly-labeled target domain UNBC-McMaster videos indicate that the proposed deep WSDA approach can achieve significantly higher level of sequence (bag)-level and frame (instance)-level pain localization accuracy than related state-of-the-art approaches.
Read more7/9/2024
0
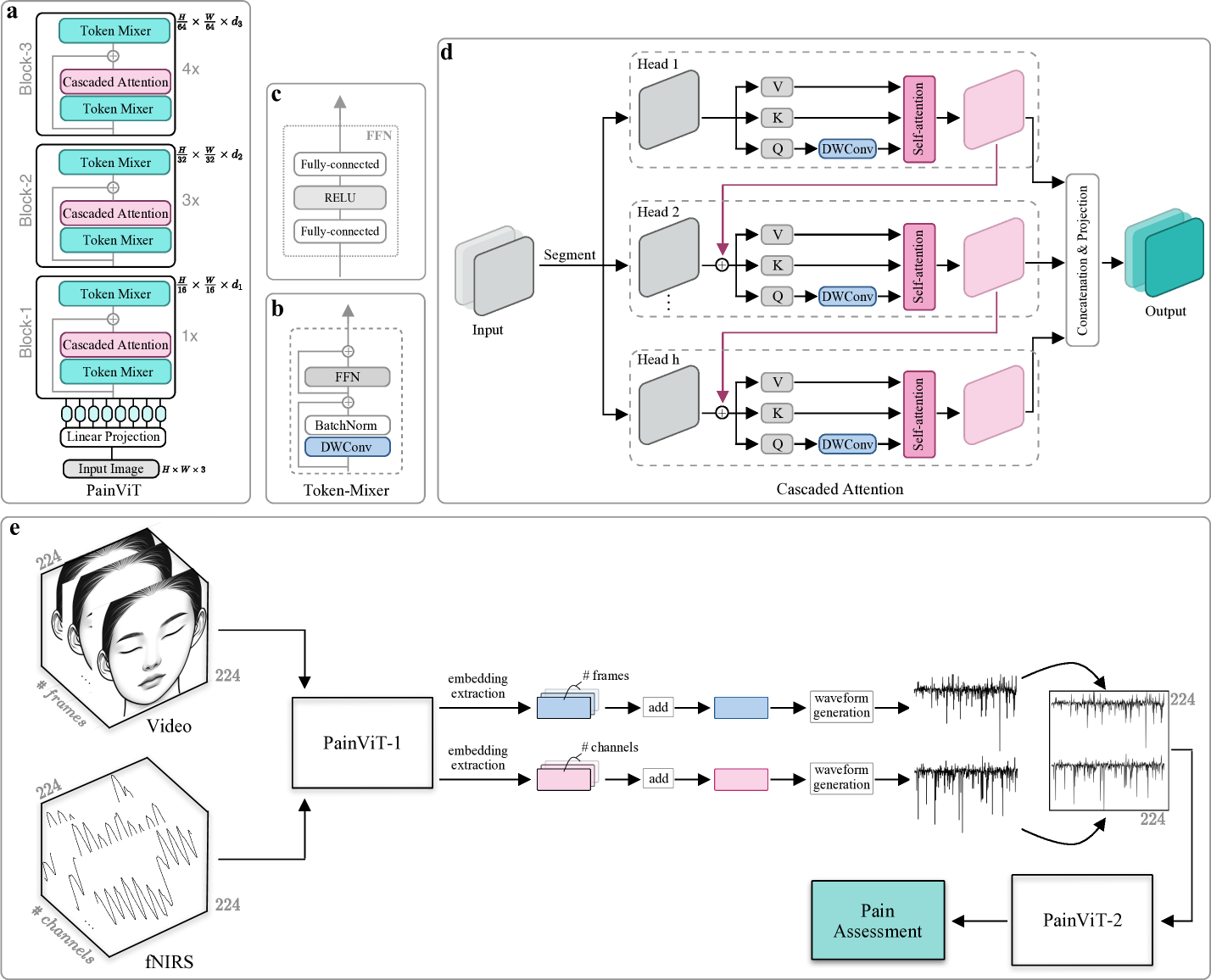
Twins-PainViT: Towards a Modality-Agnostic Vision Transformer Framework for Multimodal Automatic Pain Assessment using Facial Videos and fNIRS
Stefanos Gkikas, Manolis Tsiknakis
Automatic pain assessment plays a critical role for advancing healthcare and optimizing pain management strategies. This study has been submitted to the First Multimodal Sensing Grand Challenge for Next-Gen Pain Assessment (AI4PAIN). The proposed multimodal framework utilizes facial videos and fNIRS and presents a modality-agnostic approach, alleviating the need for domain-specific models. Employing a dual ViT configuration and adopting waveform representations for the fNIRS, as well as for the extracted embeddings from the two modalities, demonstrate the efficacy of the proposed method, achieving an accuracy of 46.76% in the multilevel pain assessment task.
Read more7/30/2024