Synthetic Thermal and RGB Videos for Automatic Pain Assessment utilizing a Vision-MLP Architecture

0

Sign in to get full access
Overview
- This paper presents a novel approach for automatically assessing pain using a combination of synthetic thermal and RGB videos and a Vision-MLP architecture.
- The researchers developed a data generation pipeline to create realistic synthetic thermal and RGB videos of people experiencing pain, which were then used to train an AI model.
- The proposed Vision-MLP architecture outperformed existing methods for pain assessment, demonstrating the potential of this approach.
Plain English Explanation
The paper discusses a new way to automatically detect and measure a person's pain level using artificial intelligence (AI). The researchers created a system that can analyze videos of people and determine how much pain they are experiencing.
To train the AI model, the researchers generated synthetic data - realistic computer-generated videos of people showing different levels of pain. These videos combined thermal camera footage (which captures heat patterns) and regular RGB video.
The researchers then used this synthetic data to train a multi-task learning model called Vision-MLP. This model was able to look at the video and identify signs of pain, such as facial expressions and body movements.
Compared to other pain assessment methods, the Vision-MLP approach performed better at accurately measuring a person's level of pain. This suggests that combining synthetic thermal and RGB data with advanced AI models could be a powerful tool for automatically and objectively assessing pain.
Technical Explanation
The paper introduces a novel approach for automatic pain assessment that combines synthetic thermal and RGB videos with a Vision-MLP architecture.
The researchers first developed a data generation pipeline to create realistic synthetic thermal and RGB videos of people experiencing different levels of pain. This allowed them to overcome the challenge of collecting large, diverse datasets of real-world pain expression.
They then trained a multi-task learning model, Vision-MLP, to jointly predict pain intensity, pain location, and pain expression from the synthetic video data. The Vision-MLP architecture leverages both convolutional and multi-layer perceptron components to capture spatial and temporal patterns related to pain.
Experiments showed that the Vision-MLP model outperformed existing methods for pain assessment, including approaches based on domain adaptation and modality-specific models. This demonstrates the value of the synthetic data generation pipeline and the effectiveness of the proposed multi-modal, multi-task learning approach.
Critical Analysis
The paper presents a promising approach, but also acknowledges several limitations and areas for future work. For example, the synthetic data, while realistic, may not fully capture the nuances of real-world pain expression. Additionally, the model was trained and evaluated on a single database, so its generalization to more diverse populations and settings remains to be tested.
Another potential concern is the ethical implications of automated pain assessment systems. While the technology could provide objective and consistent measurement, there are risks around privacy, bias, and the potential for misuse. The authors do not deeply explore these issues, which would be an important consideration for real-world deployment.
Overall, the research presented in this paper is a valuable contribution to the field of automatic pain assessment, demonstrating the power of synthetic data and multi-modal, multi-task learning. However, further work is needed to address the limitations and ensure the responsible development of such systems.
Conclusion
This paper introduces a novel approach for automatic pain assessment that combines synthetic thermal and RGB video data with a Vision-MLP architecture. The results show that this method outperforms existing techniques, highlighting the potential of synthetic data generation and multi-modal, multi-task learning for this challenging problem.
While the research represents an important step forward, there are still several areas that require further exploration, such as addressing the limitations of the synthetic data and exploring the ethical implications of automated pain assessment. Nevertheless, this work contributes valuable insights and lays the groundwork for future advancements in this important field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synthetic Thermal and RGB Videos for Automatic Pain Assessment utilizing a Vision-MLP Architecture
Stefanos Gkikas, Manolis Tsiknakis
Pain assessment is essential in developing optimal pain management protocols to alleviate suffering and prevent functional decline in patients. Consequently, reliable and accurate automatic pain assessment systems are essential for continuous and effective patient monitoring. This study presents synthetic thermal videos generated by Generative Adversarial Networks integrated into the pain recognition pipeline and evaluates their efficacy. A framework consisting of a Vision-MLP and a Transformer-based module is utilized, employing RGB and synthetic thermal videos in unimodal and multimodal settings. Experiments conducted on facial videos from the BioVid database demonstrate the effectiveness of synthetic thermal videos and underline the potential advantages of it.
Read more7/30/2024
0
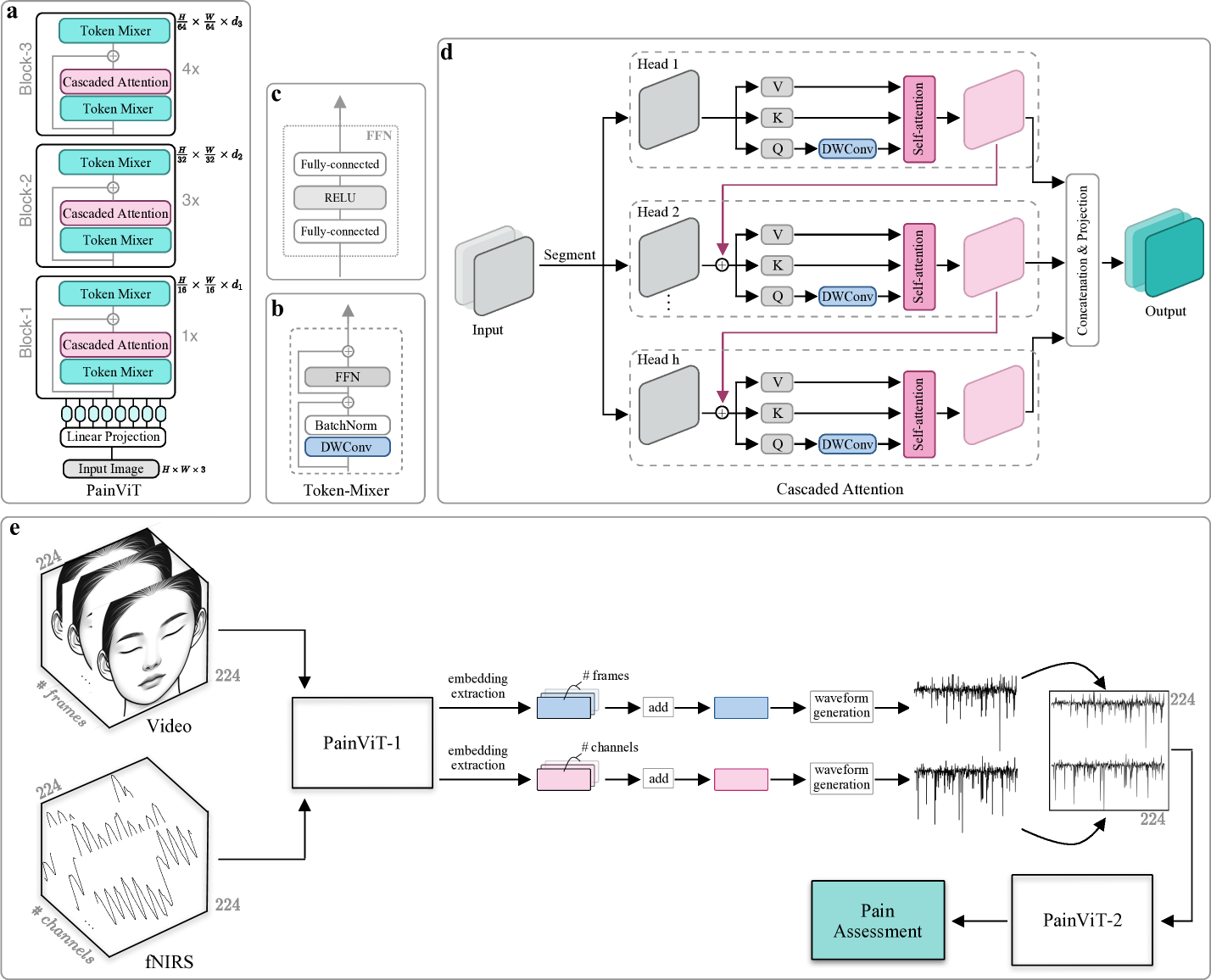
Twins-PainViT: Towards a Modality-Agnostic Vision Transformer Framework for Multimodal Automatic Pain Assessment using Facial Videos and fNIRS
Stefanos Gkikas, Manolis Tsiknakis
Automatic pain assessment plays a critical role for advancing healthcare and optimizing pain management strategies. This study has been submitted to the First Multimodal Sensing Grand Challenge for Next-Gen Pain Assessment (AI4PAIN). The proposed multimodal framework utilizes facial videos and fNIRS and presents a modality-agnostic approach, alleviating the need for domain-specific models. Employing a dual ViT configuration and adopting waveform representations for the fNIRS, as well as for the extracted embeddings from the two modalities, demonstrate the efficacy of the proposed method, achieving an accuracy of 46.76% in the multilevel pain assessment task.
Read more7/30/2024
0
Transformer with Leveraged Masked Autoencoder for video-based Pain Assessment
Minh-Duc Nguyen, Hyung-Jeong Yang, Soo-Hyung Kim, Ji-Eun Shin, Seung-Won Kim
Accurate pain assessment is crucial in healthcare for effective diagnosis and treatment; however, traditional methods relying on self-reporting are inadequate for populations unable to communicate their pain. Cutting-edge AI is promising for supporting clinicians in pain recognition using facial video data. In this paper, we enhance pain recognition by employing facial video analysis within a Transformer-based deep learning model. By combining a powerful Masked Autoencoder with a Transformers-based classifier, our model effectively captures pain level indicators through both expressions and micro-expressions. We conducted our experiment on the AI4Pain dataset, which produced promising results that pave the way for innovative healthcare solutions that are both comprehensive and objective.
Read more9/10/2024

0
T-FAKE: Synthesizing Thermal Images for Facial Landmarking
Philipp Flotho (Systems Neuroscience & Neurotechnology Unit, Faculty of Medicine, Saarland University & htw saar), Moritz Piening (Institute of Mathematics, Technische Universitat Berlin), Anna Kukleva (Max Planck Institute for Informatics, Saarland Informatics Campus), Gabriele Steidl (Institute of Mathematics, Technische Universitat Berlin)
Facial analysis is a key component in a wide range of applications such as security, autonomous driving, entertainment, and healthcare. Despite the availability of various facial RGB datasets, the thermal modality, which plays a crucial role in life sciences, medicine, and biometrics, has been largely overlooked. To address this gap, we introduce the T-FAKE dataset, a new large-scale synthetic thermal dataset with sparse and dense landmarks. To facilitate the creation of the dataset, we propose a novel RGB2Thermal loss function, which enables the transfer of thermal style to RGB faces. By utilizing the Wasserstein distance between thermal and RGB patches and the statistical analysis of clinical temperature distributions on faces, we ensure that the generated thermal images closely resemble real samples. Using RGB2Thermal style transfer based on our RGB2Thermal loss function, we create the T-FAKE dataset, a large-scale synthetic thermal dataset of faces. Leveraging our novel T-FAKE dataset, probabilistic landmark prediction, and label adaptation networks, we demonstrate significant improvements in landmark detection methods on thermal images across different landmark conventions. Our models show excellent performance with both sparse 70-point landmarks and dense 478-point landmark annotations. Our code and models are available at https://github.com/phflot/tfake.
Read more8/28/2024