Two eyes, Two views, and finally, One summary! Towards Multi-modal Multi-tasking Knowledge-Infused Medical Dialogue Summarization

0
Sign in to get full access
Overview
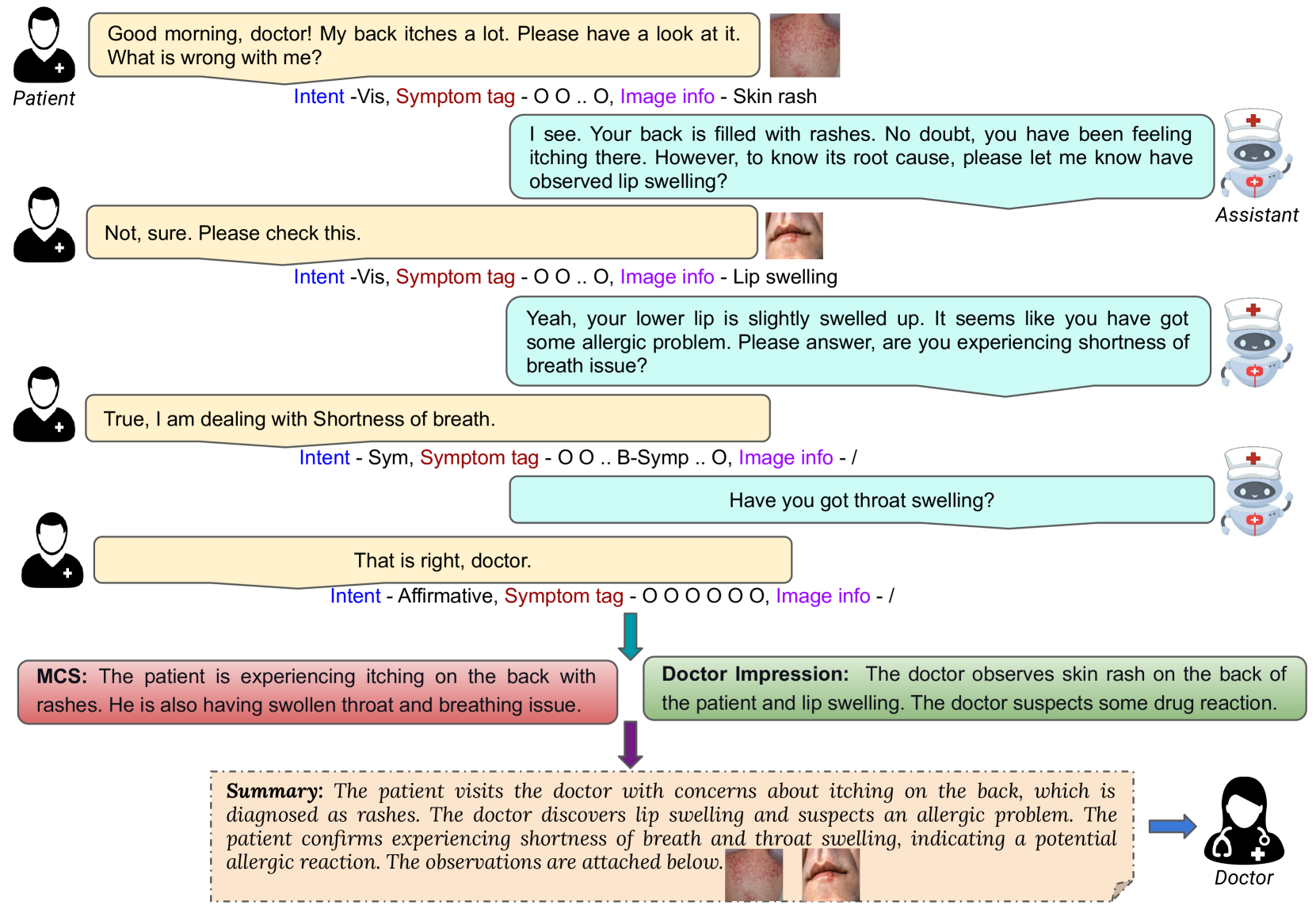
- This paper proposes a new approach for summarizing medical dialogues, which combines multiple modalities (text, images, knowledge) and multiple tasks (dialogue summarization, question answering, medical entity extraction).
- The key innovation is the integration of external medical knowledge to enhance the summarization process, making it more comprehensive and accurate.
- The authors develop a multi-modal, multi-task model called "MedSum" that can handle diverse inputs and produce high-quality summaries, entity extractions, and question-answering capabilities.
Plain English Explanation
The researchers in this paper are tackling the challenge of summarizing medical conversations between doctors and patients. <a href="https://aimodels.fyi/papers/arxiv/real-time-speech-summarization-medical-conversations">Medical conversations</a> can be complex, with a lot of technical language and information exchanged. The goal is to create a system that can accurately capture the key points of these dialogues in a concise summary.
The novel aspect of this work is the use of multiple sources of information to aid the summarization process. In addition to the dialogue text, the system also incorporates <a href="https://aimodels.fyi/papers/arxiv/converging-dimensions-information-extraction-summarization-through-multisource">external medical knowledge</a> and <a href="https://aimodels.fyi/papers/arxiv/modular-approach-multimodal-summarization-tv-shows">visual information</a> (such as medical images) to create a more comprehensive understanding.
The model, called "MedSum," is designed to not only generate summaries but also perform additional tasks like <a href="https://aimodels.fyi/papers/arxiv/metasumperceiver-multimodal-multi-document-evidence-summarization-fact">extracting medical entities</a> and answering questions about the dialogue. By combining these different capabilities, the researchers aim to create a more powerful and versatile system for summarizing complex medical conversations.
Technical Explanation
The MedSum model uses a multi-modal, multi-task architecture to handle the various components of the medical dialogue summarization task. The main elements of the system include:
- Text Encoder: This module takes the dialogue transcript as input and encodes the text using a transformer-based language model.
- Image Encoder: For dialogues that include medical images, this component processes the visual information using a convolutional neural network.
- Knowledge Encoder: This module ingests relevant medical knowledge from external sources (e.g., clinical guidelines, medical textbooks) to provide context for the dialogue.
- Multi-Task Decoder: The encoded text, images, and knowledge are then fed into a shared decoder that generates the summary, extracts medical entities, and answers questions about the dialogue.
The key innovation is the integration of the external medical knowledge, which helps the model better understand the technical medical concepts and produce more accurate and comprehensive summaries. The multi-task training also allows the model to leverage the synergies between the different sub-tasks, further enhancing its performance.
Critical Analysis
The researchers acknowledge several limitations of their work. For example, the medical knowledge base used in the experiments is relatively small, and the model may struggle with dialogues covering rare or specialized medical topics not covered in the knowledge base.
Additionally, the evaluation of the system's performance is primarily focused on quantitative metrics, such as ROUGE scores for summarization and F1 scores for entity extraction. While these metrics provide a useful benchmark, they may not fully capture the nuances of human-generated summaries or the practical usefulness of the system in real-world medical settings.
Further research could explore ways to expand the knowledge base, potentially through <a href="https://aimodels.fyi/papers/arxiv/multimodal-language-models-domain-specific-procedural-video">dynamic knowledge integration</a> or <a href="https://aimodels.fyi/papers/arxiv/metasumperceiver-multimodal-multi-document-evidence-summarization-fact">multi-document evidence gathering</a>. Additionally, user studies or qualitative evaluations could provide valuable insights into the system's usability and the quality of the generated outputs from the perspective of medical professionals and patients.
Conclusion
This paper presents a novel approach to medical dialogue summarization that leverages multiple modalities and multiple tasks to create a more comprehensive and accurate summarization system. By incorporating external medical knowledge, the MedSum model demonstrates the potential for improving the understanding and summarization of complex medical conversations.
While there are still areas for further research and refinement, this work represents a significant step forward in the development of AI-powered tools to support medical communication and decision-making. As the field of medical dialogue summarization continues to evolve, this paper's insights and contributions will likely inform and inspire future advancements in the domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Two eyes, Two views, and finally, One summary! Towards Multi-modal Multi-tasking Knowledge-Infused Medical Dialogue Summarization
Anisha Saha, Abhisek Tiwari, Sai Ruthvik, Sriparna Saha
We often summarize a multi-party conversation in two stages: chunking with homogeneous units and summarizing the chunks. Thus, we hypothesize that there exists a correlation between homogeneous speaker chunking and overall summarization tasks. In this work, we investigate the effectiveness of a multi-faceted approach that simultaneously produces summaries of medical concerns, doctor impressions, and an overall view. We introduce a multi-modal, multi-tasking, knowledge-infused medical dialogue summary generation (MMK-Summation) model, which is incorporated with adapter-based fine-tuning through a gated mechanism for multi-modal information integration. The model, MMK-Summation, takes dialogues as input, extracts pertinent external knowledge based on the context, integrates the knowledge and visual cues from the dialogues into the textual content, and ultimately generates concise summaries encompassing medical concerns, doctor impressions, and a comprehensive overview. The introduced model surpasses multiple baselines and traditional summarization models across all evaluation metrics (including human evaluation), which firmly demonstrates the efficacy of the knowledge-guided multi-tasking, multimodal medical conversation summarization. The code is available at https://github.com/NLP-RL/MMK-Summation.
Read more7/23/2024

0
MetaSumPerceiver: Multimodal Multi-Document Evidence Summarization for Fact-Checking
Ting-Chih Chen, Chia-Wei Tang, Chris Thomas
Fact-checking real-world claims often requires reviewing multiple multimodal documents to assess a claim's truthfulness, which is a highly laborious and time-consuming task. In this paper, we present a summarization model designed to generate claim-specific summaries useful for fact-checking from multimodal, multi-document datasets. The model takes inputs in the form of documents, images, and a claim, with the objective of assisting in fact-checking tasks. We introduce a dynamic perceiver-based model that can handle inputs from multiple modalities of arbitrary lengths. To train our model, we leverage a novel reinforcement learning-based entailment objective to generate summaries that provide evidence distinguishing between different truthfulness labels. To assess the efficacy of our approach, we conduct experiments on both an existing benchmark and a new dataset of multi-document claims that we contribute. Our approach outperforms the SOTA approach by 4.6% in the claim verification task on the MOCHEG dataset and demonstrates strong performance on our new Multi-News-Fact-Checking dataset.
Read more7/19/2024

0
uMedSum: A Unified Framework for Advancing Medical Abstractive Summarization
Aishik Nagar, Yutong Liu, Andy T. Liu, Viktor Schlegel, Vijay Prakash Dwivedi, Arun-Kumar Kaliya-Perumal, Guna Pratheep Kalanchiam, Yili Tang, Robby T. Tan
Medical abstractive summarization faces the challenge of balancing faithfulness and informativeness. Current methods often sacrifice key information for faithfulness or introduce confabulations when prioritizing informativeness. While recent advancements in techniques like in-context learning (ICL) and fine-tuning have improved medical summarization, they often overlook crucial aspects such as faithfulness and informativeness without considering advanced methods like model reasoning and self-improvement. Moreover, the field lacks a unified benchmark, hindering systematic evaluation due to varied metrics and datasets. This paper addresses these gaps by presenting a comprehensive benchmark of six advanced abstractive summarization methods across three diverse datasets using five standardized metrics. Building on these findings, we propose uMedSum, a modular hybrid summarization framework that introduces novel approaches for sequential confabulation removal followed by key missing information addition, ensuring both faithfulness and informativeness. Our work improves upon previous GPT-4-based state-of-the-art (SOTA) medical summarization methods, significantly outperforming them in both quantitative metrics and qualitative domain expert evaluations. Notably, we achieve an average relative performance improvement of 11.8% in reference-free metrics over the previous SOTA. Doctors prefer uMedSum's summaries 6 times more than previous SOTA in difficult cases where there are chances of confabulations or missing information. These results highlight uMedSum's effectiveness and generalizability across various datasets and metrics, marking a significant advancement in medical summarization.
Read more8/27/2024

0
Real-time Speech Summarization for Medical Conversations
Khai Le-Duc, Khai-Nguyen Nguyen, Long Vo-Dang, Truong-Son Hy
In doctor-patient conversations, identifying medically relevant information is crucial, posing the need for conversation summarization. In this work, we propose the first deployable real-time speech summarization system for real-world applications in industry, which generates a local summary after every N speech utterances within a conversation and a global summary after the end of a conversation. Our system could enhance user experience from a business standpoint, while also reducing computational costs from a technical perspective. Secondly, we present VietMed-Sum which, to our knowledge, is the first speech summarization dataset for medical conversations. Thirdly, we are the first to utilize LLM and human annotators collaboratively to create gold standard and synthetic summaries for medical conversation summarization. Finally, we present baseline results of state-of-the-art models on VietMed-Sum. All code, data (English-translated and Vietnamese) and models are available online: https://github.com/leduckhai/MultiMed
Read more6/26/2024