Real-time Speech Summarization for Medical Conversations

0

Sign in to get full access
Overview
- This paper proposes a real-time speech summarization system for medical conversations.
- The system aims to provide concise, accurate summaries of doctor-patient interactions in real-time to assist clinicians and improve patient care.
- Key components include automatic speech recognition, natural language processing, and summarization algorithms.
- The system was evaluated on a medical conversation dataset, showing promising results in terms of summary quality and latency.
Plain English Explanation
The researchers developed a system that can listen to conversations between doctors and patients in real-time and automatically generate brief, informative summaries. The goal is to help clinicians stay on top of important details during medical appointments without having to take extensive notes.
The system works by first using AI models to convert the spoken words into written text. It then analyzes this text using natural language processing techniques to identify the key points, such as the patient's main concerns, the doctor's recommendations, and any next steps. Finally, the system condenses this information into a concise summary that can be displayed to the clinician.
This technology could be particularly useful in busy medical settings, where doctors often need to juggle multiple patients and remember a lot of details. By providing real-time summaries, the system helps ensure that critical information isn't overlooked and that the doctor can focus on guiding the patient through their care.
Technical Explanation
The real-time speech summarization system proposed in this paper consists of several key components:
- Automatic Speech Recognition (ASR): The system uses an ASR model to convert the spoken conversations into text transcripts in real-time.
- Natural Language Processing (NLP): The text transcripts are then processed using NLP techniques to extract relevant information, such as named entities and salient topics.
- Summarization: A summarization algorithm is applied to condense the extracted information into a concise summary, preserving the key points of the conversation.
The researchers evaluated their system on a medical conversation dataset, measuring both the quality of the generated summaries and the latency of the system. The results showed that the system was able to produce accurate, readable summaries with relatively low latency, suggesting its potential usefulness in real-world medical settings.
Critical Analysis
The paper presents a well-designed and promising approach to real-time speech summarization for medical conversations. However, there are a few areas that could be explored further:
-
Generalizability: The system was evaluated on a single medical conversation dataset, so its performance on more diverse datasets or in different medical specialties is unclear. Expanding the evaluation could provide a better understanding of the system's robustness.
-
User Feedback: The paper does not report on feedback from clinicians or patients regarding the usefulness and usability of the system in practice. Incorporating user input could help refine the system's design and features to better meet the needs of its target audience.
-
Ethical Considerations: The use of real-time speech summarization in medical settings raises important ethical questions around privacy, data security, and the potential for bias or errors that could impact patient care. These concerns should be carefully addressed.
Conclusion
The proposed real-time speech summarization system represents a promising step towards improving the efficiency and quality of medical conversations. By providing clinicians with concise, accurate summaries in real-time, the system has the potential to enhance patient care, reduce clinician workload, and ultimately lead to better health outcomes. However, further research is needed to assess the system's generalizability, incorporate user feedback, and address ethical considerations before it can be widely deployed in clinical settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Real-time Speech Summarization for Medical Conversations
Khai Le-Duc, Khai-Nguyen Nguyen, Long Vo-Dang, Truong-Son Hy
In doctor-patient conversations, identifying medically relevant information is crucial, posing the need for conversation summarization. In this work, we propose the first deployable real-time speech summarization system for real-world applications in industry, which generates a local summary after every N speech utterances within a conversation and a global summary after the end of a conversation. Our system could enhance user experience from a business standpoint, while also reducing computational costs from a technical perspective. Secondly, we present VietMed-Sum which, to our knowledge, is the first speech summarization dataset for medical conversations. Thirdly, we are the first to utilize LLM and human annotators collaboratively to create gold standard and synthetic summaries for medical conversation summarization. Finally, we present baseline results of state-of-the-art models on VietMed-Sum. All code, data (English-translated and Vietnamese) and models are available online: https://github.com/leduckhai/MultiMed
Read more6/26/2024
0
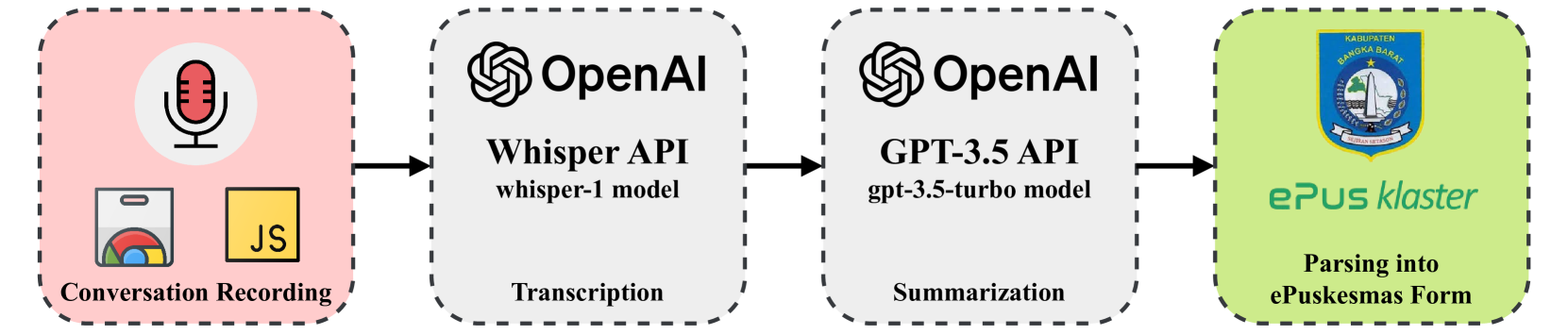
Using LLM for Real-Time Transcription and Summarization of Doctor-Patient Interactions into ePuskesmas in Indonesia
Azmul Asmar Irfan, Nur Ahmad Khatim, Mansur M. Arief
One of the key issues contributing to inefficiency in Puskesmas is the time-consuming nature of doctor-patient interactions. Doctors need to conduct thorough consultations, which include diagnosing the patient's condition, providing treatment advice, and transcribing detailed notes into medical records. In regions with diverse linguistic backgrounds, doctors often have to ask clarifying questions, further prolonging the process. While diagnosing is essential, transcription and summarization can often be automated using AI to improve time efficiency and help doctors enhance care quality and enable early diagnosis and intervention. This paper proposes a solution using a localized large language model (LLM) to transcribe, translate, and summarize doctor-patient conversations. We utilize the Whisper model for transcription and GPT-3 to summarize them into the ePuskemas medical records format. This system is implemented as an add-on to an existing web browser extension, allowing doctors to fill out patient forms while talking. By leveraging this solution for real-time transcription, translation, and summarization, doctors can improve the turnaround time for patient care while enhancing the quality of records, which become more detailed and insightful for future visits. This innovation addresses challenges like overcrowded facilities and the administrative burden on healthcare providers in Indonesia. We believe this solution will help doctors save time, provide better care, and produce more accurate medical records, representing a significant step toward modernizing healthcare and ensuring patients receive timely, high-quality care, even in resource-constrained settings.
Read more9/26/2024
🗣️
0
VietMed: A Dataset and Benchmark for Automatic Speech Recognition of Vietnamese in the Medical Domain
Khai Le-Duc
Due to privacy restrictions, there's a shortage of publicly available speech recognition datasets in the medical domain. In this work, we present VietMed - a Vietnamese speech recognition dataset in the medical domain comprising 16h of labeled medical speech, 1000h of unlabeled medical speech and 1200h of unlabeled general-domain speech. To our best knowledge, VietMed is by far the world's largest public medical speech recognition dataset in 7 aspects: total duration, number of speakers, diseases, recording conditions, speaker roles, unique medical terms and accents. VietMed is also by far the largest public Vietnamese speech dataset in terms of total duration. Additionally, we are the first to present a medical ASR dataset covering all ICD-10 disease groups and all accents within a country. Moreover, we release the first public large-scale pre-trained models for Vietnamese ASR, w2v2-Viet and XLSR-53-Viet, along with the first public large-scale fine-tuned models for medical ASR. Even without any medical data in unsupervised pre-training, our best pre-trained model XLSR-53-Viet generalizes very well to the medical domain by outperforming state-of-the-art XLSR-53, from 51.8% to 29.6% WER on test set (a relative reduction of more than 40%). All code, data and models are made publicly available: https://github.com/leduckhai/MultiMed.
Read more5/29/2024
0
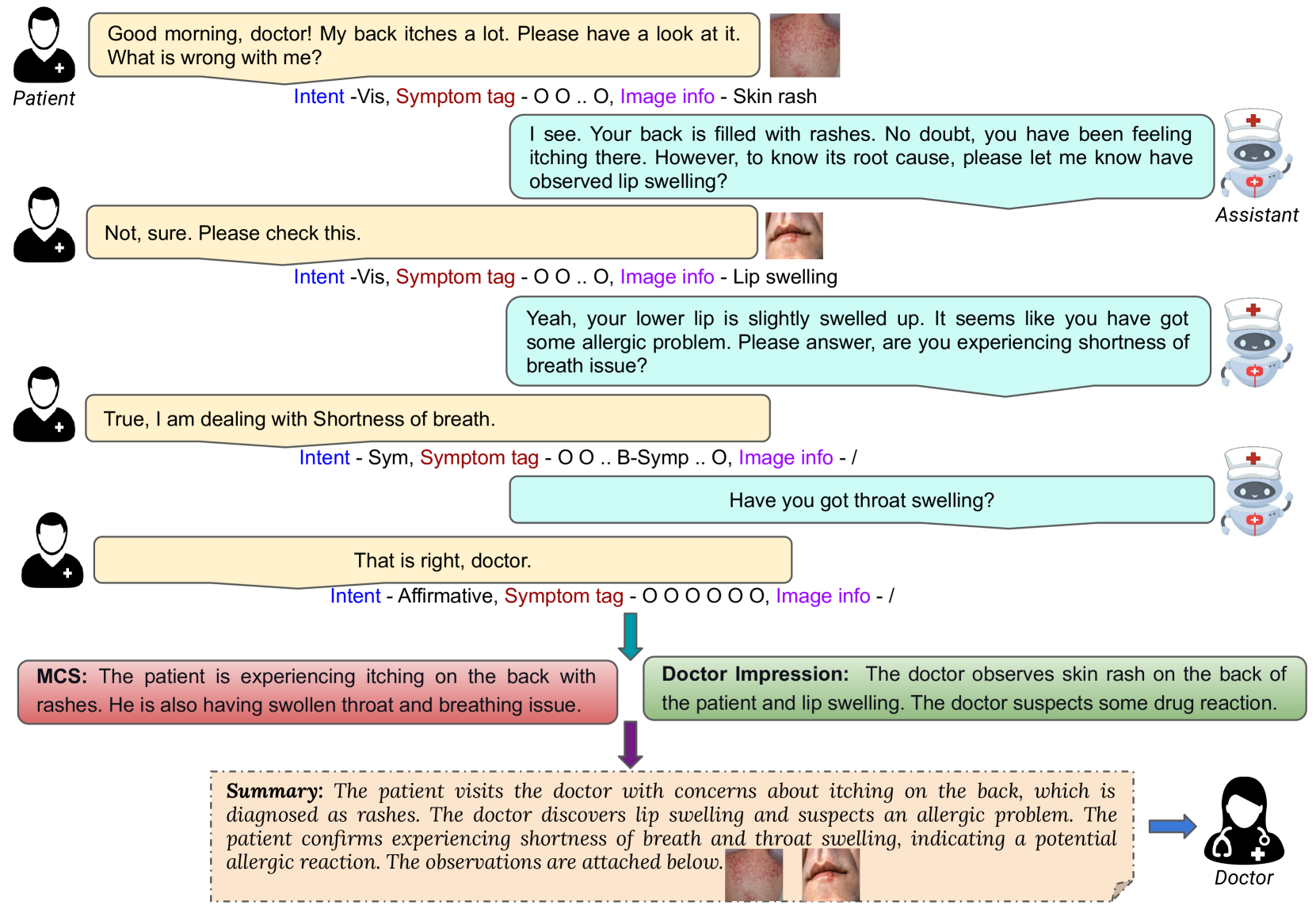
Two eyes, Two views, and finally, One summary! Towards Multi-modal Multi-tasking Knowledge-Infused Medical Dialogue Summarization
Anisha Saha, Abhisek Tiwari, Sai Ruthvik, Sriparna Saha
We often summarize a multi-party conversation in two stages: chunking with homogeneous units and summarizing the chunks. Thus, we hypothesize that there exists a correlation between homogeneous speaker chunking and overall summarization tasks. In this work, we investigate the effectiveness of a multi-faceted approach that simultaneously produces summaries of medical concerns, doctor impressions, and an overall view. We introduce a multi-modal, multi-tasking, knowledge-infused medical dialogue summary generation (MMK-Summation) model, which is incorporated with adapter-based fine-tuning through a gated mechanism for multi-modal information integration. The model, MMK-Summation, takes dialogues as input, extracts pertinent external knowledge based on the context, integrates the knowledge and visual cues from the dialogues into the textual content, and ultimately generates concise summaries encompassing medical concerns, doctor impressions, and a comprehensive overview. The introduced model surpasses multiple baselines and traditional summarization models across all evaluation metrics (including human evaluation), which firmly demonstrates the efficacy of the knowledge-guided multi-tasking, multimodal medical conversation summarization. The code is available at https://github.com/NLP-RL/MMK-Summation.
Read more7/23/2024