A Two-Stage Band-Split Mamba-2 Network for Music Separation

0
Sign in to get full access
Overview
- Presents a two-stage band-split Mamba-2 network for music source separation
- Aims to improve separation performance by dividing the frequency spectrum into multiple bands
- Uses a two-stage network architecture to process each frequency band separately
Plain English Explanation
The paper introduces a new approach for separating different instruments or vocals from a mixed audio recording. The key idea is to split the full frequency range into multiple smaller bands and process each band independently using a neural network. This allows the model to focus on specific frequency regions rather than trying to separate the entire spectrum at once.
The two-stage network architecture first extracts features from each frequency band, then combines the band-specific features to produce the final separated sources. This staged approach aims to improve the separation performance compared to processing the full spectrum at once.
The authors call their model the "Two-Stage Band-Split Mamba-2 Network" or TS-BSMAMBA2 for short. The "Mamba" part refers to a neural network architecture they've used in previous work on music source separation and image denoising.
Technical Explanation
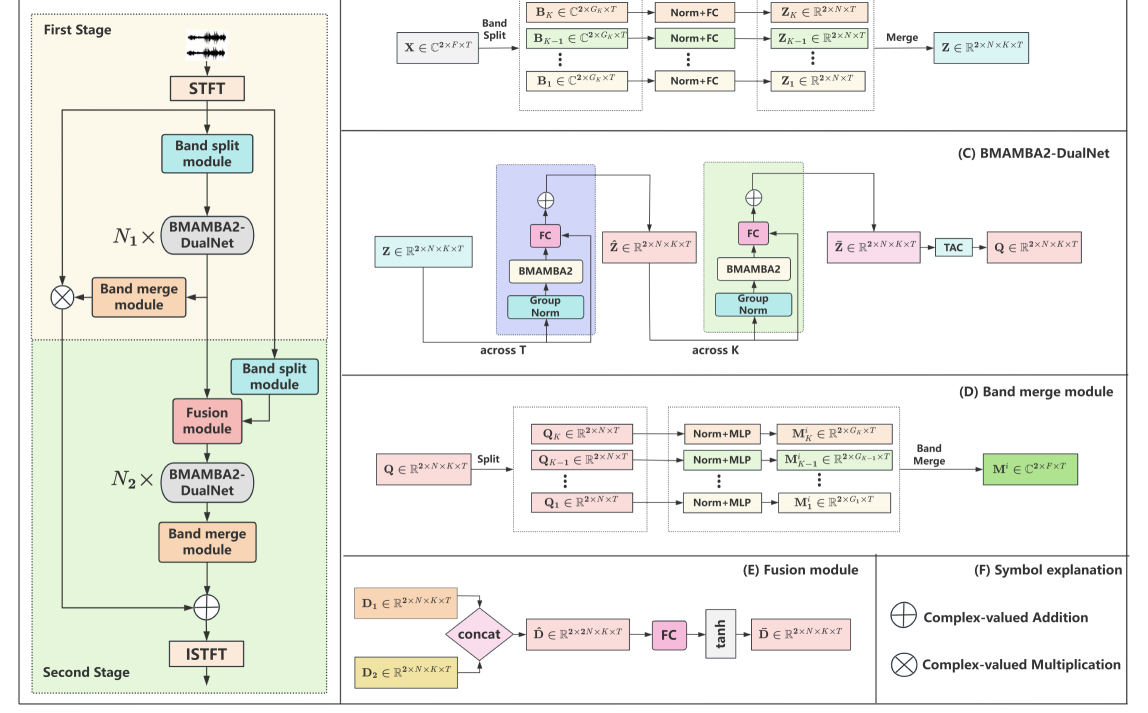
The TS-BSMAMBA2 model consists of two main stages:
-
Band-Split Feature Extraction: The input audio is first split into multiple frequency bands. Each band is then processed by a separate neural network sub-module to extract relevant features.
-
Band-Wise Source Separation: The band-specific features are concatenated and fed into another neural network sub-module that produces the final separated sources for each instrument or vocal.
The key innovation is this two-stage band-split architecture, which allows the model to focus on processing specific frequency regions in isolation before combining the results. This is in contrast to previous approaches that tried to separate the full spectrum at once.
The authors evaluate the TS-BSMAMBA2 model on standard music separation benchmark datasets and show that it outperforms existing state-of-the-art methods. They attribute the performance gains to the band-split design, which enables more effective feature extraction and source separation.
Critical Analysis
The paper provides a strong technical contribution by introducing a novel band-split architecture for music source separation. The two-stage approach seems well-justified and the experimental results demonstrate its effectiveness.
However, the authors do not discuss any potential limitations or drawbacks of their approach. For example, it's unclear how the model would perform on more complex musical mixtures with a larger number of sources or a wider frequency range. There may also be computational efficiency trade-offs in splitting the spectrum into multiple bands.
Additionally, the paper lacks a deeper analysis of the types of errors or failure cases the model exhibits. Understanding these failure modes could provide valuable insights for further improving music separation systems.
Overall, the TS-BSMAMBA2 model represents a promising step forward in music source separation, but more comprehensive evaluation and analysis would help strengthen the claims and provide a clearer picture of its capabilities and limitations.
Conclusion
This paper presents a novel two-stage band-split Mamba-2 network for music source separation. The key innovation is the use of a band-split architecture that processes different frequency regions independently before combining the results. This approach aims to improve separation performance compared to previous methods that process the full spectrum at once.
The authors demonstrate the effectiveness of their TS-BSMAMBA2 model on standard music separation benchmarks, outperforming existing state-of-the-art techniques. While the paper makes a strong technical contribution, it would benefit from a more thorough analysis of the model's limitations and failure cases.
Overall, the TS-BSMAMBA2 represents an interesting and promising development in the field of music source separation, with potential applications in areas like music production, audio editing, and music information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Two-Stage Band-Split Mamba-2 Network for Music Separation
Jinglin Bai, Yuan Fang, Jiajie Wang, Xueliang Zhang
Music source separation (MSS) aims to separate mixed music into its distinct tracks, such as vocals, bass, drums, and more. MSS is considered to be a challenging audio separation task due to the complexity of music signals. Although the RNN and Transformer architecture are not perfect, they are commonly used to model the music sequence for MSS. Recently, Mamba-2 has already demonstrated high efficiency in various sequential modeling tasks, but its superiority has not been investigated in MSS. This paper applies Mamba-2 with a two-stage strategy, which introduces residual mapping based on the mask method, effectively compensating for the details absent in the mask and further improving separation performance. Experiments confirm the superiority of bidirectional Mamba-2 and the effectiveness of the two-stage network in MSS. The source code is publicly accessible at https://github.com/baijinglin/TS-BSmamba2.
Read more9/16/2024
0
SPMamba: State-space model is all you need in speech separation
Kai Li, Guo Chen, Runxuan Yang, Xiaolin Hu
Existing CNN-based speech separation models face local receptive field limitations and cannot effectively capture long time dependencies. Although LSTM and Transformer-based speech separation models can avoid this problem, their high complexity makes them face the challenge of computational resources and inference efficiency when dealing with long audio. To address this challenge, we introduce an innovative speech separation method called SPMamba. This model builds upon the robust TF-GridNet architecture, replacing its traditional BLSTM modules with bidirectional Mamba modules. These modules effectively model the spatiotemporal relationships between the time and frequency dimensions, allowing SPMamba to capture long-range dependencies with linear computational complexity. Specifically, the bidirectional processing within the Mamba modules enables the model to utilize both past and future contextual information, thereby enhancing separation performance. Extensive experiments conducted on public datasets, including WSJ0-2Mix, WHAM!, and Libri2Mix, as well as the newly constructed Echo2Mix dataset, demonstrated that SPMamba significantly outperformed existing state-of-the-art models, achieving superior results while also reducing computational complexity. These findings highlighted the effectiveness of SPMamba in tackling the intricate challenges of speech separation in complex environments.
Read more9/11/2024
0
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
Read more5/2/2024

0
MusicMamba: A Dual-Feature Modeling Approach for Generating Chinese Traditional Music with Modal Precision
Jiatao Chen, Tianming Xie, Xing Tang, Jing Wang, Wenjing Dong, Bing Shi
In recent years, deep learning has significantly advanced the MIDI domain, solidifying music generation as a key application of artificial intelligence. However, existing research primarily focuses on Western music and encounters challenges in generating melodies for Chinese traditional music, especially in capturing modal characteristics and emotional expression. To address these issues, we propose a new architecture, the Dual-Feature Modeling Module, which integrates the long-range dependency modeling of the Mamba Block with the global structure capturing capabilities of the Transformer Block. Additionally, we introduce the Bidirectional Mamba Fusion Layer, which integrates local details and global structures through bidirectional scanning, enhancing the modeling of complex sequences. Building on this architecture, we propose the REMI-M representation, which more accurately captures and generates modal information in melodies. To support this research, we developed FolkDB, a high-quality Chinese traditional music dataset encompassing various styles and totaling over 11 hours of music. Experimental results demonstrate that the proposed architecture excels in generating melodies with Chinese traditional music characteristics, offering a new and effective solution for music generation.
Read more9/5/2024