U Can't Gen This? A Survey of Intellectual Property Protection Methods for Data in Generative AI
2406.15386
0
0
📊
Abstract
Large Generative AI (GAI) models have the unparalleled ability to generate text, images, audio, and other forms of media that are increasingly indistinguishable from human-generated content. As these models often train on publicly available data, including copyrighted materials, art and other creative works, they inadvertently risk violating copyright and misappropriation of intellectual property (IP). Due to the rapid development of generative AI technology and pressing ethical considerations from stakeholders, protective mechanisms and techniques are emerging at a high pace but lack systematisation. In this paper, we study the concerns regarding the intellectual property rights of training data and specifically focus on the properties of generative models that enable misuse leading to potential IP violations. Then we propose a taxonomy that leads to a systematic review of technical solutions for safeguarding the data from intellectual property violations in GAI.
Create account to get full access
Overview
- Large Generative AI (GAI) models can create text, images, audio, and other media that are hard to distinguish from human-made content.
- These models often train on publicly available data, including copyrighted materials, art, and other creative works, which risks violating intellectual property (IP) rights.
- As GAI technology rapidly develops, solutions to protect data from IP violations are emerging, but lack a systematic approach.
Plain English Explanation
Large Generative AI (GAI) models have an incredible ability to generate content like text, images, and audio that can be very difficult to tell apart from content created by humans. The problem is that these models often train on publicly available data, which can include copyrighted materials, artwork, and other creative works. This means they could inadvertently violate IP rights and misuse this intellectual property.
As GAI technology has been developing rapidly, there have been a lot of efforts to come up with ways to protect data from these IP violations. However, these solutions haven't been organized in a systematic way. This paper aims to study the concerns around IP rights for the data used to train GAI models, and then propose a way to categorize the different technical solutions that are emerging to help safeguard against IP infringement.
Technical Explanation
This paper focuses on the concerns around the intellectual property rights of the data used to train Generative AI (GAI) models. Specifically, it examines the properties of these models that enable potential misuse and IP violations.
The researchers then propose a taxonomy, or classification system, that allows for a systematic review of the technical solutions being developed to protect data from IP infringement in GAI. This taxonomy covers things like estimating the originality of generated content, mitigating IP violations in visual generative AI, and economic approaches to addressing copyright challenges. The taxonomy also includes ideas like data Shapley, which aims to quantify the contribution of different data points to a model's performance.
Critical Analysis
The paper provides a helpful overview of the IP issues surrounding Generative AI and the emerging technical solutions. However, it acknowledges that these solutions are still developing and lack a cohesive, systematic approach.
There are likely other important considerations and potential pitfalls that were not covered, such as the challenges of enforcing IP rights across international boundaries, or unintended consequences of some technical fixes. Additionally, the paper does not delve into the broader societal implications and ethical debates around Generative AI and IP.
Overall, this research is a valuable contribution, but further work is needed to fully address the complex, multifaceted nature of IP protection in the rapidly evolving field of Generative AI.
Conclusion
This paper examines the intellectual property concerns raised by Generative AI (GAI) models, which can inadvertently infringe on copyrights and misappropriate creative works during the training process. To address this issue, the researchers propose a taxonomy to systematically review the technical solutions being developed to safeguard data from IP violations in GAI.
While this is an important step forward, the paper acknowledges that the solutions are still emerging and lack a cohesive, comprehensive approach. Continued research and cross-disciplinary collaboration will be crucial to fully understand and mitigate the complex IP challenges posed by the rapid advancements in Generative AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Uncertain Boundaries: Multidisciplinary Approaches to Copyright Issues in Generative AI
Jocelyn Dzuong, Zichong Wang, Wenbin Zhang
0
0
In the rapidly evolving landscape of generative artificial intelligence (AI), the increasingly pertinent issue of copyright infringement arises as AI advances to generate content from scraped copyrighted data, prompting questions about ownership and protection that impact professionals across various careers. With this in mind, this survey provides an extensive examination of copyright infringement as it pertains to generative AI, aiming to stay abreast of the latest developments and open problems. Specifically, it will first outline methods of detecting copyright infringement in mediums such as text, image, and video. Next, it will delve an exploration of existing techniques aimed at safeguarding copyrighted works from generative models. Furthermore, this survey will discuss resources and tools for users to evaluate copyright violations. Finally, insights into ongoing regulations and proposals for AI will be explored and compared. Through combining these disciplines, the implications of AI-driven content and copyright are thoroughly illustrated and brought into question.
4/15/2024

Evaluating and Mitigating IP Infringement in Visual Generative AI
Zhenting Wang, Chen Chen, Vikash Sehwag, Minzhou Pan, Lingjuan Lyu
0
0
The popularity of visual generative AI models like DALL-E 3, Stable Diffusion XL, Stable Video Diffusion, and Sora has been increasing. Through extensive evaluation, we discovered that the state-of-the-art visual generative models can generate content that bears a striking resemblance to characters protected by intellectual property rights held by major entertainment companies (such as Sony, Marvel, and Nintendo), which raises potential legal concerns. This happens when the input prompt contains the character's name or even just descriptive details about their characteristics. To mitigate such IP infringement problems, we also propose a defense method against it. In detail, we develop a revised generation paradigm that can identify potentially infringing generated content and prevent IP infringement by utilizing guidance techniques during the diffusion process. It has the capability to recognize generated content that may be infringing on intellectual property rights, and mitigate such infringement by employing guidance methods throughout the diffusion process without retrain or fine-tune the pretrained models. Experiments on well-known character IPs like Spider-Man, Iron Man, and Superman demonstrate the effectiveness of the proposed defense method. Our data and code can be found at https://github.com/ZhentingWang/GAI_IP_Infringement.
6/10/2024
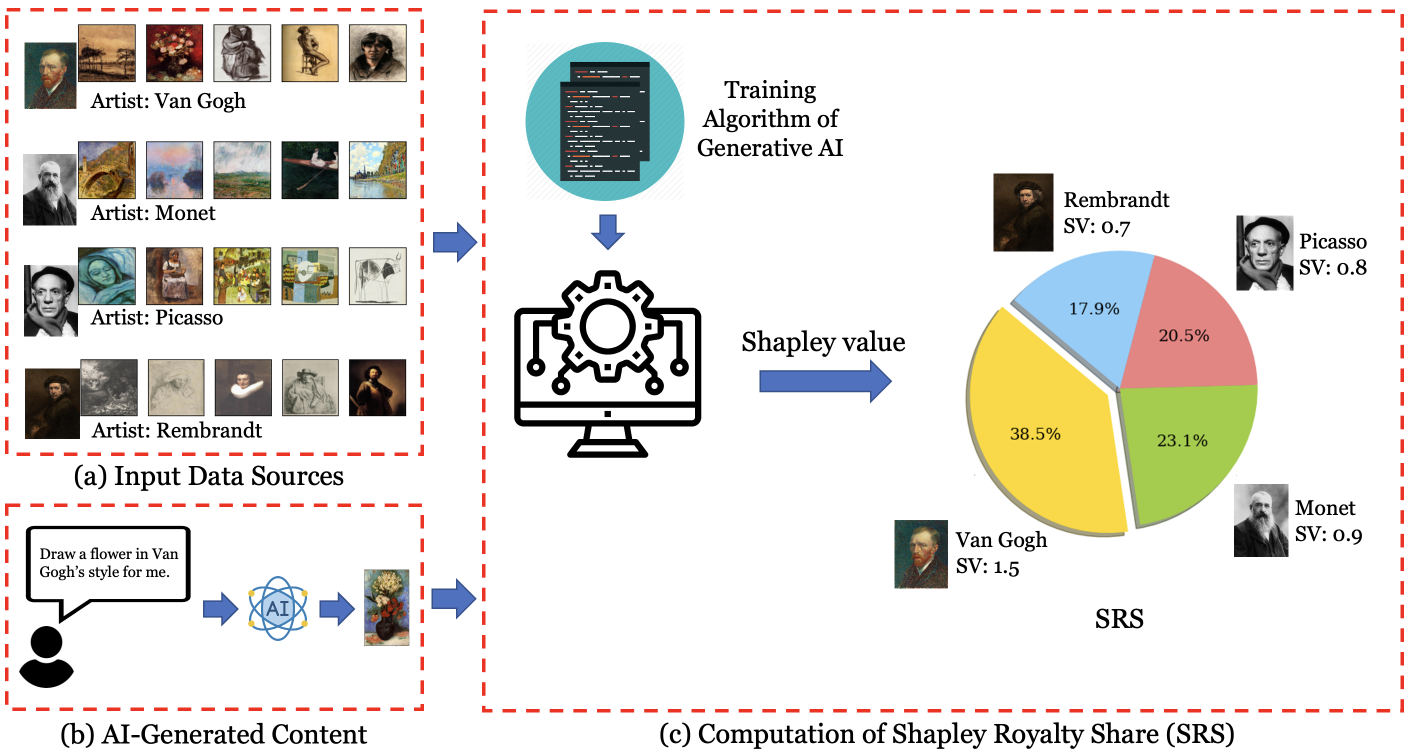
An Economic Solution to Copyright Challenges of Generative AI
Jiachen T. Wang, Zhun Deng, Hiroaki Chiba-Okabe, Boaz Barak, Weijie J. Su
0
0
Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
4/24/2024
🌀
Tackling GenAI Copyright Issues: Originality Estimation and Genericization
Hiroaki Chiba-Okabe, Weijie J. Su
0
0
The rapid progress of generative AI technology has sparked significant copyright concerns, leading to numerous lawsuits filed against AI developers. While some studies explore methods to mitigate copyright risks by steering the outputs of generative models away from those resembling copyrighted data, little attention has been paid to the question of how much of a resemblance is undesirable; more original or unique data are afforded stronger protection, and the threshold level of resemblance for constituting infringement correspondingly lower. Here, leveraging this principle, we propose a genericization method that modifies the outputs of a generative model to make them more generic and less likely to infringe copyright. To achieve this, we introduce a metric for quantifying the level of originality of data in a manner that is consistent with the legal framework. This metric can be practically estimated by drawing samples from a generative model, which is then used for the genericization process. Experiments demonstrate that our genericization method successfully modifies the output of a text-to-image generative model so that it produces more generic, copyright-compliant images.
6/24/2024