Data Shapley in One Training Run

0

Sign in to get full access
Overview
- Introduces a new technique called "Data Shapley in One Training Run" for efficiently calculating the Shapley value of each training data point in a machine learning model
- Demonstrates how this method can be used to identify the most influential data points and efficiently update the model during training
- Provides experimental results showing the effectiveness of the proposed approach compared to existing techniques
Plain English Explanation
Data Shapley is a way to measure how much each individual data point in a machine learning dataset contributes to the model's performance. The traditional approach to calculating Data Shapley is computationally expensive, as it requires training the model multiple times.
The researchers in this paper propose a new technique called "Data Shapley in One Training Run" that can calculate the Shapley value of each data point during a single training run. This makes the process much more efficient and practical for real-world applications.
The key idea is to use a technique called influence functions to estimate how the model would change if a particular data point was removed or modified. By tracking these influence estimates during training, the researchers can calculate the Shapley value of each data point without needing to train multiple models.
The authors demonstrate the effectiveness of their approach through experiments on several machine learning benchmarks. They show that their method can identify the most influential data points and efficiently update the model during training, outperforming existing techniques.
Technical Explanation
The researchers propose a novel algorithm called "Data Shapley in One Training Run" that can efficiently compute the Shapley value of each training data point in a single training run. The key idea is to use influence functions to estimate how the model parameters would change if a particular data point was removed or modified.
The algorithm works as follows:
- During training, the model parameters are updated using stochastic gradient descent.
- After each gradient update, the algorithm computes the influence of each training data point on the current model parameters using the influence function.
- The Shapley value of each data point is then estimated based on these influence estimates, without the need to train multiple models.
The researchers prove that this approach provides an unbiased estimate of the true Shapley values, and they demonstrate its effectiveness on several machine learning benchmarks. Compared to existing techniques, their method is much more efficient, requiring only a single training run to compute the Shapley values for all data points.
Critical Analysis
The researchers provide a thorough theoretical analysis of their proposed method, including proofs of its unbiasedness and convergence properties. They also present extensive experimental results showing its effectiveness compared to existing techniques.
However, the paper does not address some potential limitations or areas for further research. For example, the algorithm assumes access to the full training dataset, which may not be feasible in some real-world scenarios where data is distributed or privacy-sensitive. Additionally, the paper does not explore the impact of hyperparameter choices or model architecture on the accuracy of the Shapley value estimates.
Further research could investigate techniques for applying Data Shapley in one training run to distributed or federated learning settings, or for handling datasets that are too large to fit in memory. It would also be interesting to see how the method performs on a wider range of machine learning tasks and model architectures.
Conclusion
The "Data Shapley in One Training Run" technique proposed in this paper represents a significant advancement in the field of data valuation for machine learning. By providing an efficient way to compute the Shapley value of each training data point during a single training run, the researchers have made this powerful technique much more practical for real-world applications.
The ability to identify the most influential data points can have important implications for model debugging, dataset curation, and active learning. As machine learning models become increasingly complex and reliant on large datasets, tools like Data Shapley will be crucial for understanding and improving the performance of these models.
Overall, this paper makes an important contribution to the growing body of research on data valuation and interpretability in machine learning, and the proposed method has the potential to have a significant impact on the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Shapley in One Training Run
Jiachen T. Wang, Prateek Mittal, Dawn Song, Ruoxi Jia
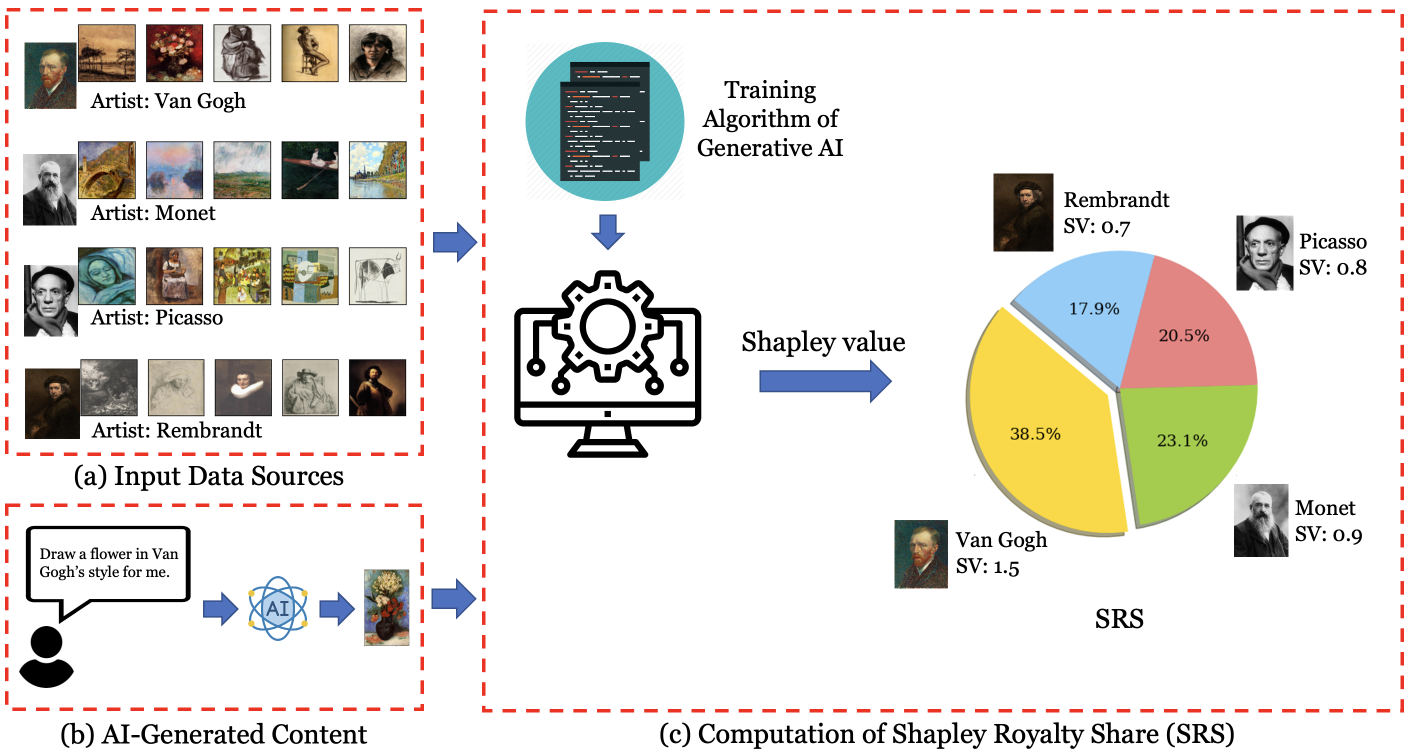
Data Shapley provides a principled framework for attributing data's contribution within machine learning contexts. However, existing approaches require re-training models on different data subsets, which is computationally intensive, foreclosing their application to large-scale models. Furthermore, they produce the same attribution score for any models produced by running the learning algorithm, meaning they cannot perform targeted attribution towards a specific model obtained from a single run of the algorithm. This paper introduces In-Run Data Shapley, which addresses these limitations by offering scalable data attribution for a target model of interest. In its most efficient implementation, our technique incurs negligible additional runtime compared to standard model training. This dramatic efficiency improvement makes it possible to perform data attribution for the foundation model pretraining stage for the first time. We present several case studies that offer fresh insights into pretraining data's contribution and discuss their implications for copyright in generative AI and pretraining data curation.
Read more7/2/2024
0
An Economic Solution to Copyright Challenges of Generative AI
Jiachen T. Wang, Zhun Deng, Hiroaki Chiba-Okabe, Boaz Barak, Weijie J. Su
Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Read more9/10/2024
📊
0
U Can't Gen This? A Survey of Intellectual Property Protection Methods for Data in Generative AI
Tanja v{S}arv{c}evi'c (SBA Research), Alicja Karlowicz (SBA Research), Rudolf Mayer (SBA Research), Ricardo Baeza-Yates (EAI, Northeastern University), Andreas Rauber (TU Wien)
Large Generative AI (GAI) models have the unparalleled ability to generate text, images, audio, and other forms of media that are increasingly indistinguishable from human-generated content. As these models often train on publicly available data, including copyrighted materials, art and other creative works, they inadvertently risk violating copyright and misappropriation of intellectual property (IP). Due to the rapid development of generative AI technology and pressing ethical considerations from stakeholders, protective mechanisms and techniques are emerging at a high pace but lack systematisation. In this paper, we study the concerns regarding the intellectual property rights of training data and specifically focus on the properties of generative models that enable misuse leading to potential IP violations. Then we propose a taxonomy that leads to a systematic review of technical solutions for safeguarding the data from intellectual property violations in GAI.
Read more6/26/2024
✅
0
Copyright Protection in Generative AI: A Technical Perspective
Jie Ren, Han Xu, Pengfei He, Yingqian Cui, Shenglai Zeng, Jiankun Zhang, Hongzhi Wen, Jiayuan Ding, Pei Huang, Lingjuan Lyu, Hui Liu, Yi Chang, Jiliang Tang
Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Read more7/25/2024