UDKAG: Augmenting Large Vision-Language Models with Up-to-Date Knowledge
2405.14554
0
0
🛠️
Abstract
Large vision-language models (LVLMs) are ignorant of the up-to-date knowledge, such as LLaVA series, because they cannot be updated frequently due to the large amount of resources required, and therefore fail in many cases. For example, if a LVLM was released on January 2024, and it wouldn't know the detailed plot of the new movie Dune 2, which wasn't released until February 2024. To solve the problem, a promising solution is to provide LVLMs with up-to-date knowledge via internet search during inference, i.e., internet-augmented generation (IAG), which is already integrated in some closed-source commercial LVLMs such as GPT-4V. However, the specific mechanics underpinning them remain a mystery. In this paper, we propose a plug-and-play framework, for augmenting existing LVLMs in handling visual question answering (VQA) about up-to-date knowledge, dubbed UDKAG. A hierarchical filtering model is trained to effectively and efficiently find the most helpful content from the websites returned by a search engine to prompt LVLMs with up-to-date knowledge. To train the model and evaluate our framework's performance, we propose a pipeline to automatically generate news-related VQA samples to construct a dataset, dubbed UDK-VQA. A multi-model voting mechanism is introduced to label the usefulness of website/content for VQA samples to construct the training set. Experimental results demonstrate the effectiveness of our framework, outperforming GPT-4V by about 25% in accuracy.
Create account to get full access
Overview
- Large vision-language models (LVLMs) struggle to stay up-to-date with the latest information, like the plot of a new movie, because they cannot be updated frequently due to their resource-intensive nature.
- A potential solution is to provide LVLMs with up-to-date knowledge by searching the internet during inference, a process known as internet-augmented generation (IAG).
- However, the specifics of how IAG works in commercial LVLMs like GPT-4V remain unclear.
- This paper proposes a framework called UDKAG (Up-to-Date Knowledge Augmented Generation) to enhance LVLMs' ability to answer visual questions about current events and news.
Plain English Explanation
Large language models like GPT-3 are impressive, but they have a significant limitation: they can't easily stay up-to-date with the latest information. For example, if a language model was trained before a new movie came out, it wouldn't know the details of the plot.
To address this issue, the researchers propose a system that allows language models to access the internet during use and find the most relevant information to include in their responses. This is called internet-augmented generation (IAG).
Some companies, like OpenAI, have already integrated IAG into their commercial models, like GPT-4V. However, the inner workings of these systems are not publicly known.
In this paper, the researchers develop a new framework called UDKAG (Up-to-Date Knowledge Augmented Generation) that uses a hierarchical filtering model to quickly find the most helpful information from the web to supplement a language model's responses, specifically for answering visual questions about current events and news.
The researchers also create a dataset of news-related visual questions to train and evaluate their system. Their experiments show that UDKAG can outperform GPT-4V by about 25% in accuracy, demonstrating the potential of this approach.
Technical Explanation
The paper proposes a framework called UDKAG (Up-to-Date Knowledge Augmented Generation) to enhance large vision-language models' (LVLMs) ability to answer visual questions about current events and news.
The key components of UDKAG are:
-
Hierarchical Filtering Model: This is a machine learning model trained to efficiently find the most relevant information from websites returned by a search engine to supplement the LVLM's response to a visual question.
-
Automatically Generated Dataset: The researchers created a dataset called UDK-VQA, which contains visual questions related to news and current events. This dataset is used to train and evaluate the UDKAG framework.
-
Multi-Model Voting Mechanism: To label the usefulness of website content for answering the VQA samples in the UDK-VQA dataset, the researchers used a voting system that combines multiple models.
The key insight behind UDKAG is that by using a targeted search and filtering process, the system can quickly find the most helpful information to improve the LVLM's responses, even for questions about very recent events that the model may not have been trained on.
The researchers evaluated UDKAG on the UDK-VQA dataset and found that it outperformed the commercial GPT-4V model by about 25% in accuracy, demonstrating the potential of this approach for enhancing the capabilities of large language models.
Critical Analysis
The paper presents a promising approach to addressing the challenge of keeping large language models up-to-date with the latest information. The UDKAG framework's ability to outperform a commercially available model like GPT-4V is an impressive result.
However, the paper does not provide much detail on the specific mechanics of the hierarchical filtering model or the multi-model voting mechanism used to label the dataset. More information on these key components would be helpful for understanding the full scope of the technical contribution.
Additionally, the paper does not discuss the potential limitations or caveats of the UDKAG approach. For example, it's unclear how the system would perform on more open-ended or complex questions, or how it would handle cases where the search results do not contain the necessary information to answer the question.
Further research could also explore ways to more tightly integrate the search and filtering components with the language model, potentially leading to even greater performance improvements. Surgical LVLM is one example of a similar approach that could provide useful insights.
Overall, the UDKAG framework represents an interesting and potentially valuable contribution to the field of enhancing question answering with external knowledge, and the results warrant further exploration and refinement.
Conclusion
This paper proposes a framework called UDKAG (Up-to-Date Knowledge Augmented Generation) to enhance large vision-language models' (LVLMs) ability to answer visual questions about current events and news. The key innovation is a hierarchical filtering model that can quickly find the most relevant information from the web to supplement the LVLM's responses.
By creating a dataset of news-related visual questions (UDK-VQA) and using a multi-model voting system to label the usefulness of website content, the researchers were able to demonstrate that UDKAG outperforms the commercial GPT-4V model by about 25% in accuracy.
This work highlights the potential of internet-augmented generation (IAG) approaches to address the challenge of keeping large language models up-to-date with the latest information. Further research could explore ways to more tightly integrate the search and filtering components with the language model, as well as investigate the system's performance on more open-ended or complex questions.
Overall, the UDKAG framework represents a promising step forward in enhancing question answering with external knowledge and improving interactive image retrieval, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Towards Retrieval Augmented Generation over Large Video Libraries
Yannis Tevissen, Khalil Guetari, Fr'ed'eric Petitpont
0
0
Video content creators need efficient tools to repurpose content, a task that often requires complex manual or automated searches. Crafting a new video from large video libraries remains a challenge. In this paper we introduce the task of Video Library Question Answering (VLQA) through an interoperable architecture that applies Retrieval Augmented Generation (RAG) to video libraries. We propose a system that uses large language models (LLMs) to generate search queries, retrieving relevant video moments indexed by speech and visual metadata. An answer generation module then integrates user queries with this metadata to produce responses with specific video timestamps. This approach shows promise in multimedia content retrieval, and AI-assisted video content creation.
6/24/2024
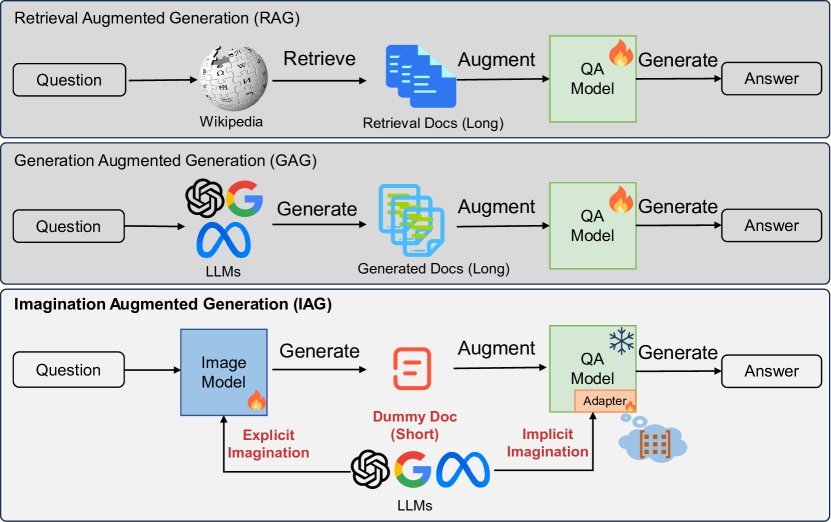
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Huanxuan Liao, Shizhu He, Yao Xu, Yuanzhe Zhang, Kang Liu, Shengping Liu, Jun Zhao
0
0
Retrieval-Augmented-Generation and Gener-ation-Augmented-Generation have been proposed to enhance the knowledge required for question answering over Large Language Models (LLMs). However, the former relies on external resources, and both require incorporating explicit documents into the context, which increases execution costs and susceptibility to noise data. Recent works indicate that LLMs have modeled rich knowledge, albeit not effectively triggered or awakened. Inspired by this, we propose a novel knowledge-augmented framework, Imagination-Augmented-Generation (IAG), which simulates the human capacity to compensate for knowledge deficits while answering questions solely through imagination, thereby awakening relevant knowledge in LLMs without relying on external resources. Guided by IAG, we propose an imagine richer context method for question answering (IMcQA). IMcQA consists of two modules: explicit imagination, which generates a short dummy document by learning from long context compression, and implicit imagination, which creates flexible adapters by distilling from a teacher model with a long context. Experimental results on three datasets demonstrate that IMcQA exhibits significant advantages in both open-domain and closed-book settings, as well as in out-of-distribution generalization. Our code will be available at https://github.com/Xnhyacinth/IAG.
6/19/2024
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
0
0
Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
5/24/2024
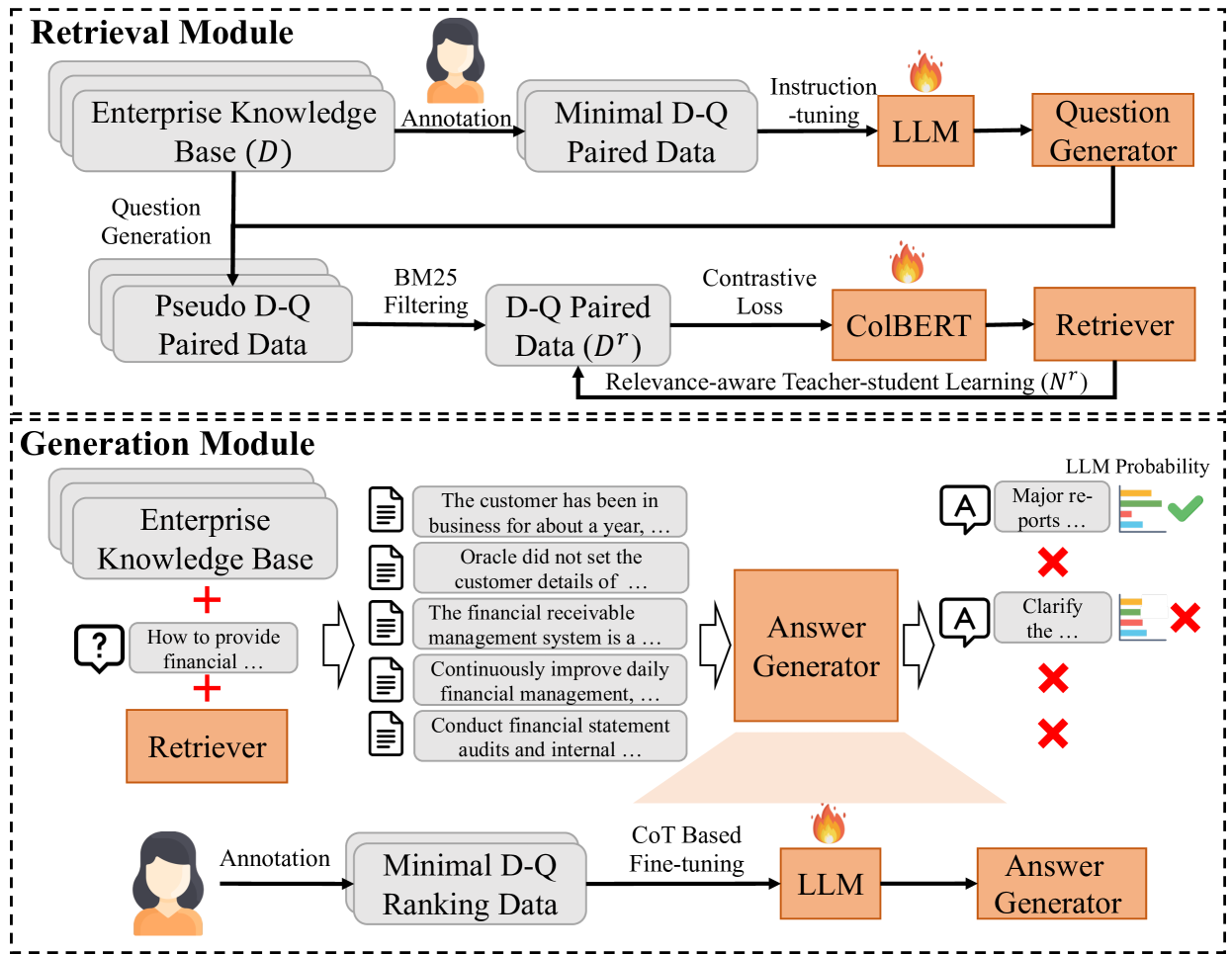
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024