UIT-DarkCow team at ImageCLEFmedical Caption 2024: Diagnostic Captioning for Radiology Images Efficiency with Transformer Models

0

Sign in to get full access
Overview
• This paper describes the contributions of the UIT-DarkCow team at the ImageCLEFmedical Caption 2024 competition, which focused on diagnostic captioning for radiology images using transformer models. • The team developed an efficient transformer-based approach to generate accurate captions for medical images, aiming to assist radiologists in reporting and diagnosis. • The research builds on recent advancements in self-supervised text-vision frameworks and compressed image captioning using CNN-based encoders.
Plain English Explanation
The UIT-DarkCow team participated in the ImageCLEFmedical Caption 2024 competition, which challenged researchers to create AI systems that can automatically generate descriptive captions for medical images, such as X-rays and CT scans. The team developed a specialized transformer-based model that can efficiently analyze these images and produce detailed, accurate captions to help radiologists in their work.
This builds on recent progress in AI techniques that can learn to understand the relationship between images and text, allowing the system to describe what it sees in a way that is useful for medical professionals. By automating the captioning process, the goal is to save radiologists time and improve the consistency and quality of their reporting.
Technical Explanation
The UIT-DarkCow team's approach leverages the power of transformer models, a type of neural network architecture that has shown great success in natural language processing and, more recently, in multimodal tasks involving both images and text.
The team's system takes a medical image as input and uses a CNN-based encoder to efficiently compress the visual information. This compressed representation is then fed into a transformer-based decoder that generates the corresponding diagnostic caption. The researchers optimized the model architecture and training process to maximize the efficiency and accuracy of the captioning, drawing on insights from prior work in compressed image captioning and summarizing radiology reports.
Critical Analysis
The paper provides a thorough evaluation of the UIT-DarkCow team's approach, demonstrating its effectiveness on the ImageCLEFmedical Caption 2024 dataset. However, the researchers acknowledge that their method still has room for improvement, particularly in generating more nuanced and comprehensive captions that better capture the clinical significance of the findings.
Additionally, the paper does not address potential biases or limitations in the training data, which could lead to the model reproducing existing disparities or blind spots in radiological practice. Further work is needed to ensure the fairness and robustness of such AI-powered captioning systems.
Conclusion
The UIT-DarkCow team's research represents an important step towards automating the diagnostic captioning of medical images, with the potential to streamline radiologists' workflow and improve the consistency and quality of reporting. By leveraging the power of transformer models and building on recent advancements in multimodal AI and report summarization, the team has developed an efficient and effective approach that could have significant practical applications in the field of radiology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UIT-DarkCow team at ImageCLEFmedical Caption 2024: Diagnostic Captioning for Radiology Images Efficiency with Transformer Models
Quan Van Nguyen, Huy Quang Pham, Dan Quang Tran, Thang Kien-Bao Nguyen, Nhat-Hao Nguyen-Dang, Bao-Thien Nguyen-Tat
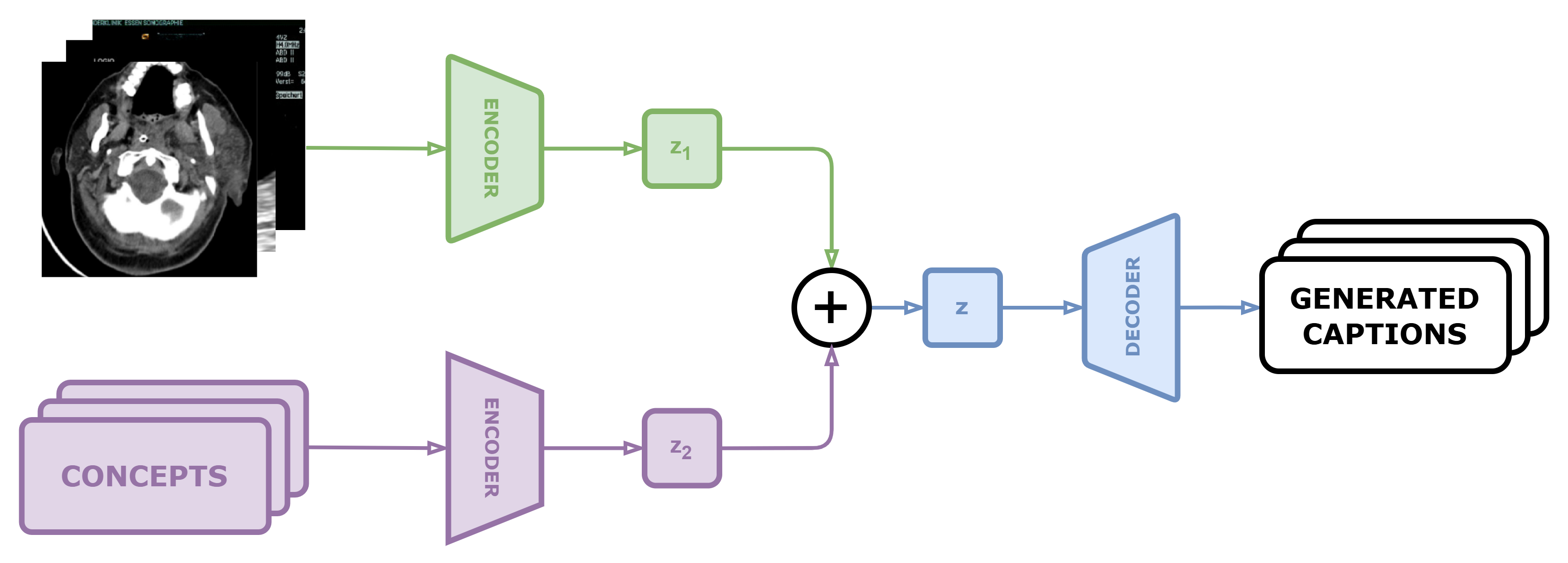
Purpose: This study focuses on the development of automated text generation from radiology images, termed diagnostic captioning, to assist medical professionals in reducing clinical errors and improving productivity. The aim is to provide tools that enhance report quality and efficiency, which can significantly impact both clinical practice and deep learning research in the biomedical field. Methods: In our participation in the ImageCLEFmedical2024 Caption evaluation campaign, we explored caption prediction tasks using advanced Transformer-based models. We developed methods incorporating Transformer encoder-decoder and Query Transformer architectures. These models were trained and evaluated to generate diagnostic captions from radiology images. Results: Experimental evaluations demonstrated the effectiveness of our models, with the VisionDiagnostor-BioBART model achieving the highest BERTScore of 0.6267. This performance contributed to our team, DarkCow, achieving third place on the leaderboard. Conclusion: Our diagnostic captioning models show great promise in aiding medical professionals by generating high-quality reports efficiently. This approach can facilitate better data processing and performance optimization in medical imaging departments, ultimately benefiting healthcare delivery.
Read more5/29/2024
0
DS@BioMed at ImageCLEFmedical Caption 2024: Enhanced Attention Mechanisms in Medical Caption Generation through Concept Detection Integration
Nhi Ngoc-Yen Nguyen, Le-Huy Tu, Dieu-Phuong Nguyen, Nhat-Tan Do, Minh Triet Thai, Bao-Thien Nguyen-Tat
Purpose: Our study presents an enhanced approach to medical image caption generation by integrating concept detection into attention mechanisms. Method: This method utilizes sophisticated models to identify critical concepts within medical images, which are then refined and incorporated into the caption generation process. Results: Our concept detection task, which employed the Swin-V2 model, achieved an F1 score of 0.58944 on the validation set and 0.61998 on the private test set, securing the third position. For the caption prediction task, our BEiT+BioBart model, enhanced with concept integration and post-processing techniques, attained a BERTScore of 0.60589 on the validation set and 0.5794 on the private test set, placing ninth. Conclusion: These results underscore the efficacy of concept-aware algorithms in generating precise and contextually appropriate medical descriptions. The findings demonstrate that our approach significantly improves the quality of medical image captions, highlighting its potential to enhance medical image interpretation and documentation, thereby contributing to improved healthcare outcomes.
Read more6/4/2024

0
Clinical Context-aware Radiology Report Generation from Medical Images using Transformers
Sonit Singh
Recent developments in the field of Natural Language Processing, especially language models such as the transformer have brought state-of-the-art results in language understanding and language generation. In this work, we investigate the use of the transformer model for radiology report generation from chest X-rays. We also highlight limitations in evaluating radiology report generation using only the standard language generation metrics. We then applied a transformer based radiology report generation architecture, and also compare the performance of a transformer based decoder with the recurrence based decoder. Experiments were performed using the IU-CXR dataset, showing superior results to its LSTM counterpart and being significantly faster. Finally, we identify the need of evaluating radiology report generation system using both language generation metrics and classification metrics, which helps to provide robust measure of generated reports in terms of their coherence and diagnostic value.
Read more8/22/2024

0
A Data-Driven Guided Decoding Mechanism for Diagnostic Captioning
Panagiotis Kaliosis, John Pavlopoulos, Foivos Charalampakos, Georgios Moschovis, Ion Androutsopoulos
Diagnostic Captioning (DC) automatically generates a diagnostic text from one or more medical images (e.g., X-rays, MRIs) of a patient. Treated as a draft, the generated text may assist clinicians, by providing an initial estimation of the patient's condition, speeding up and helping safeguard the diagnostic process. The accuracy of a diagnostic text, however, strongly depends on how well the key medical conditions depicted in the images are expressed. We propose a new data-driven guided decoding method that incorporates medical information, in the form of existing tags capturing key conditions of the image(s), into the beam search of the diagnostic text generation process. We evaluate the proposed method on two medical datasets using four DC systems that range from generic image-to-text systems with CNN encoders and RNN decoders to pre-trained Large Language Models. The latter can also be used in few- and zero-shot learning scenarios. In most cases, the proposed mechanism improves performance with respect to all evaluation measures. We provide an open-source implementation of the proposed method at https://github.com/nlpaueb/dmmcs.
Read more6/21/2024