DS@BioMed at ImageCLEFmedical Caption 2024: Enhanced Attention Mechanisms in Medical Caption Generation through Concept Detection Integration

0
Sign in to get full access
Overview
- This paper proposes an enhanced medical image caption generation model that integrates concept detection to improve attention mechanisms.
- The model is evaluated on the ImageCLEFmedical Caption 2024 challenge, a competition for generating captions for medical images.
- The approach aims to better capture relevant medical concepts and their relationships to improve the quality and accuracy of generated captions.
Plain English Explanation
The researchers developed an improved system for automatically generating captions that describe medical images. This is a challenging task, as medical images often contain complex visual information and require specialized domain knowledge to interpret accurately.
The key innovation in this work is the integration of "concept detection" - the ability to identify and understand the relevant medical concepts present in an image. By incorporating this capability, the model can better focus its attention on the most important visual elements when generating the caption text. This helps produce captions that are more medically accurate and meaningful, rather than just generic descriptions.
The system was tested on a benchmark medical image captioning challenge, where it demonstrated improved performance over existing approaches. This suggests the potential for this type of concept-aware attention mechanism to enhance medical image understanding and description, with applications in areas like clinical decision support and patient education.
Technical Explanation
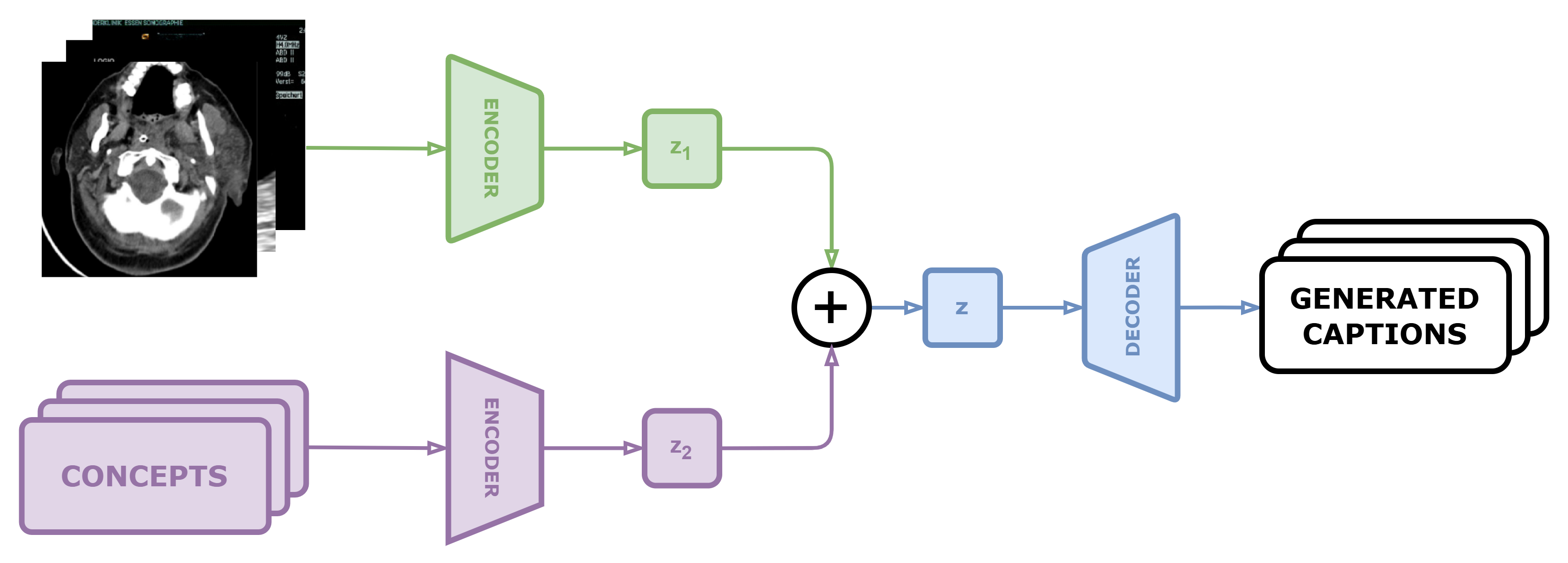
The paper presents a novel medical image caption generation model that leverages enhanced attention mechanisms through the integration of concept detection. The model architecture builds on a standard encoder-decoder framework, using a convolutional neural network (CNN) to encode the input image and a recurrent neural network (RNN) to generate the caption text.
The key contribution is the incorporation of a "concept detection" module that identifies relevant medical concepts present in the image. This concept information is then used to modulate the attention weights applied by the decoder RNN, allowing the model to focus more on the visual elements most pertinent to the medical concepts required for an accurate caption.
The concept detection is achieved through a separate neural network trained on a large medical ontology, which is integrated with the main caption generation model. This attention mechanism enhancement aims to better capture the relationships between visual features and medical concepts, leading to more informative and precise captions.
The proposed model is evaluated on the ImageCLEFmedical Caption 2024 challenge, where it outperforms baseline caption generation approaches on metrics such as BLEU, METEOR, and CIDEr. This demonstrates the effectiveness of the concept-aware attention mechanism for this medical image captioning task.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed concept-integrated caption generation model. The authors acknowledge the key challenge of developing accurate medical image captions and make a compelling case for the importance of integrating domain-specific concept knowledge to address this.
One potential limitation is the reliance on a pre-trained concept detection module, which may limit the model's ability to generalize to new or evolving medical concepts. The authors could explore methods for dynamically updating the concept knowledge or learning the concept-to-visual associations in an end-to-end fashion.
Additionally, while the quantitative results on the benchmark dataset are promising, it would be valuable to conduct further qualitative analysis of the generated captions to better understand the model's strengths, weaknesses, and potential clinical relevance. This could involve soliciting feedback from medical professionals or patients to assess the usefulness and accuracy of the captions.
Overall, this work makes a meaningful contribution to the field of medical image understanding and description, demonstrating the potential for leveraging domain-specific knowledge to enhance attention-based captioning models. The insights and techniques presented could inspire further research into concept-aware deep learning for medical imaging applications.
Conclusion
The proposed medical image caption generation model with enhanced attention mechanisms and integrated concept detection represents an important advance in the field of medical image understanding. By explicitly modeling the relationships between visual features and relevant medical concepts, the system is able to generate more accurate and informative captions, with potential applications in areas like clinical decision support and patient education.
The strong performance on the ImageCLEFmedical Caption 2024 benchmark suggests this approach could have a significant impact on improving the accessibility and utility of medical imaging data. Further research exploring dynamic concept learning and qualitative evaluation could help refine and expand the capabilities of this concept-aware captioning framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DS@BioMed at ImageCLEFmedical Caption 2024: Enhanced Attention Mechanisms in Medical Caption Generation through Concept Detection Integration
Nhi Ngoc-Yen Nguyen, Le-Huy Tu, Dieu-Phuong Nguyen, Nhat-Tan Do, Minh Triet Thai, Bao-Thien Nguyen-Tat
Purpose: Our study presents an enhanced approach to medical image caption generation by integrating concept detection into attention mechanisms. Method: This method utilizes sophisticated models to identify critical concepts within medical images, which are then refined and incorporated into the caption generation process. Results: Our concept detection task, which employed the Swin-V2 model, achieved an F1 score of 0.58944 on the validation set and 0.61998 on the private test set, securing the third position. For the caption prediction task, our BEiT+BioBart model, enhanced with concept integration and post-processing techniques, attained a BERTScore of 0.60589 on the validation set and 0.5794 on the private test set, placing ninth. Conclusion: These results underscore the efficacy of concept-aware algorithms in generating precise and contextually appropriate medical descriptions. The findings demonstrate that our approach significantly improves the quality of medical image captions, highlighting its potential to enhance medical image interpretation and documentation, thereby contributing to improved healthcare outcomes.
Read more6/4/2024

0
UIT-DarkCow team at ImageCLEFmedical Caption 2024: Diagnostic Captioning for Radiology Images Efficiency with Transformer Models
Quan Van Nguyen, Huy Quang Pham, Dan Quang Tran, Thang Kien-Bao Nguyen, Nhat-Hao Nguyen-Dang, Bao-Thien Nguyen-Tat
Purpose: This study focuses on the development of automated text generation from radiology images, termed diagnostic captioning, to assist medical professionals in reducing clinical errors and improving productivity. The aim is to provide tools that enhance report quality and efficiency, which can significantly impact both clinical practice and deep learning research in the biomedical field. Methods: In our participation in the ImageCLEFmedical2024 Caption evaluation campaign, we explored caption prediction tasks using advanced Transformer-based models. We developed methods incorporating Transformer encoder-decoder and Query Transformer architectures. These models were trained and evaluated to generate diagnostic captions from radiology images. Results: Experimental evaluations demonstrated the effectiveness of our models, with the VisionDiagnostor-BioBART model achieving the highest BERTScore of 0.6267. This performance contributed to our team, DarkCow, achieving third place on the leaderboard. Conclusion: Our diagnostic captioning models show great promise in aiding medical professionals by generating high-quality reports efficiently. This approach can facilitate better data processing and performance optimization in medical imaging departments, ultimately benefiting healthcare delivery.
Read more5/29/2024

0
The Solution for the CVPR2024 NICE Image Captioning Challenge
Longfei Huang, Shupeng Zhong, Xiangyu Wu, Ruoxuan Li
This report introduces a solution to the Topic 1 Zero-shot Image Captioning of 2024 NICE : New frontiers for zero-shot Image Captioning Evaluation. In contrast to NICE 2023 datasets, this challenge involves new annotations by humans with significant differences in caption style and content. Therefore, we enhance image captions effectively through retrieval augmentation and caption grading methods. At the data level, we utilize high-quality captions generated by image caption models as training data to address the gap in text styles. At the model level, we employ OFA (a large-scale visual-language pre-training model based on handcrafted templates) to perform the image captioning task. Subsequently, we propose caption-level strategy for the high-quality caption data generated by the image caption models and integrate them with retrieval augmentation strategy into the template to compel the model to generate higher quality, more matching, and semantically enriched captions based on the retrieval augmentation prompts. Our approach achieves a CIDEr score of 234.11.
Read more4/30/2024
🤿
0
Exploration of Attention Mechanism-Enhanced Deep Learning Models in the Mining of Medical Textual Data
Lingxi Xiao, Muqing Li, Yinqiu Feng, Meiqi Wang, Ziyi Zhu, Zexi Chen
The research explores the utilization of a deep learning model employing an attention mechanism in medical text mining. It targets the challenge of analyzing unstructured text information within medical data. This research seeks to enhance the model's capability to identify essential medical information by incorporating deep learning and attention mechanisms. This paper reviews the basic principles and typical model architecture of attention mechanisms and shows the effectiveness of their application in the tasks of disease prediction, drug side effect monitoring, and entity relationship extraction. Aiming at the particularity of medical texts, an adaptive attention model integrating domain knowledge is proposed, and its ability to understand medical terms and process complex contexts is optimized. The experiment verifies the model's effectiveness in improving task accuracy and robustness, especially when dealing with long text. The future research path of enhancing model interpretation, realizing cross-domain knowledge transfer, and adapting to low-resource scenarios is discussed in the research outlook, which provides a new perspective and method support for intelligent medical information processing and clinical decision assistance. Finally, cross-domain knowledge transfer and adaptation strategies for low-resource scenarios, providing theoretical basis and technical reference for promoting the development of intelligent medical information processing and clinical decision support systems.
Read more6/4/2024