UMMAN: Unsupervised Multi-graph Merge Adversarial Network for Disease Prediction Based on Intestinal Flora

0
Sign in to get full access
Overview
- This paper introduces UMMAN, an Unsupervised Multi-graph Merge Adversarial Network for predicting diseases based on intestinal flora data.
- The key idea is to use an adversarial learning framework to merge multiple incomplete graphs of gut microbiome data and learn a unified representation for disease prediction.
- The approach aims to overcome the challenges of incomplete and heterogeneous data in gut microbiome studies.
Plain English Explanation
The human gut is home to trillions of microorganisms, collectively known as the gut microbiome. This diverse ecosystem plays a crucial role in our health, and imbalances in the gut microbiome have been linked to various diseases. Researchers have used graph neural networks to model the complex relationships within the gut microbiome and predict diseases.
However, real-world gut microbiome data is often incomplete and fragmented, coming from different sources and studies. This can make it challenging to develop accurate disease prediction models. The authors of this paper propose a novel approach called UMMAN, which stands for Unsupervised Multi-graph Merge Adversarial Network.
The key idea behind UMMAN is to use an adversarial learning framework to merge multiple incomplete graphs of gut microbiome data into a unified representation. This unified representation can then be used to predict diseases more accurately.
The adversarial learning framework consists of two main components: a generator and a discriminator. The generator tries to merge the incomplete graphs in a way that the discriminator cannot distinguish from a complete graph. Through this adversarial process, the model learns to create a comprehensive representation of the gut microbiome that can be used for disease prediction.
By overcoming the challenges of incomplete and heterogeneous data, UMMAN aims to improve the accuracy and reliability of disease prediction based on gut microbiome data.
Technical Explanation
The UMMAN model consists of three main components:
-
Graph Encoder: This module takes the incomplete input graphs and encodes them into a latent representation.
-
Graph Merger: This is the core of the model, where an adversarial learning process is used to merge the latent representations of the input graphs into a unified representation.
-
Prediction Head: This module takes the unified representation and uses it to predict the presence or absence of a particular disease.
The adversarial learning process works as follows:
- The Generator takes the latent representations of the input graphs and tries to merge them into a unified representation.
- The Discriminator takes the unified representation and tries to determine whether it is a real complete graph or a synthetic one generated by the Generator.
- The Generator and Discriminator are trained in an adversarial manner, with the Generator trying to fool the Discriminator and the Discriminator trying to detect the synthetic graphs.
Through this adversarial training, the Generator learns to create a unified representation that is indistinguishable from a real complete graph, effectively overcoming the challenges of incomplete and heterogeneous data.
The authors evaluate UMMAN on several real-world gut microbiome datasets and show that it outperforms other state-of-the-art methods for disease prediction.
Critical Analysis
The authors have addressed an important challenge in gut microbiome research, which is the prevalence of incomplete and fragmented data. By using an adversarial learning framework, UMMAN is able to merge multiple incomplete graphs into a unified representation that can be used for more accurate disease prediction.
However, the paper does not provide much insight into the limitations of the UMMAN approach. For example, it is unclear how the model performs when the input graphs are not only incomplete but also have different levels of heterogeneity or noise. Additionally, the paper does not discuss the computational complexity of the adversarial training process or the sensitivity of the model to hyperparameter settings.
Furthermore, the authors could have explored the interpretability of the learned unified representation. Understanding the key features or patterns in the merged graph that contribute to disease prediction could provide valuable insights for domain experts.
Overall, the UMMAN approach is a promising step towards addressing the challenges of incomplete and heterogeneous gut microbiome data, but further research is needed to fully understand its limitations and potential applications.
Conclusion
This paper introduces UMMAN, an Unsupervised Multi-graph Merge Adversarial Network for predicting diseases based on intestinal flora data. The key innovation is the use of an adversarial learning framework to merge multiple incomplete graphs of gut microbiome data into a unified representation, which can then be used for more accurate disease prediction.
By overcoming the challenges of incomplete and heterogeneous data, UMMAN represents a significant advancement in the field of gut microbiome-based disease prediction. The authors' evaluation on real-world datasets demonstrates the effectiveness of their approach, which could have important implications for early disease detection and personalized healthcare.
However, the paper also highlights the need for further research to address the limitations of the UMMAN approach, such as its sensitivity to data quality and model complexity. Exploring the interpretability of the learned representations could also lead to valuable insights for both researchers and clinicians.
Overall, the UMMAN model is a promising step towards leveraging the wealth of gut microbiome data for improved disease prediction and prevention, with the potential to have a significant impact on public health and personalized medicine.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UMMAN: Unsupervised Multi-graph Merge Adversarial Network for Disease Prediction Based on Intestinal Flora
Dingkun Liu, Hongjie Zhou, Yilu Qu, Huimei Zhang, Yongdong Xu
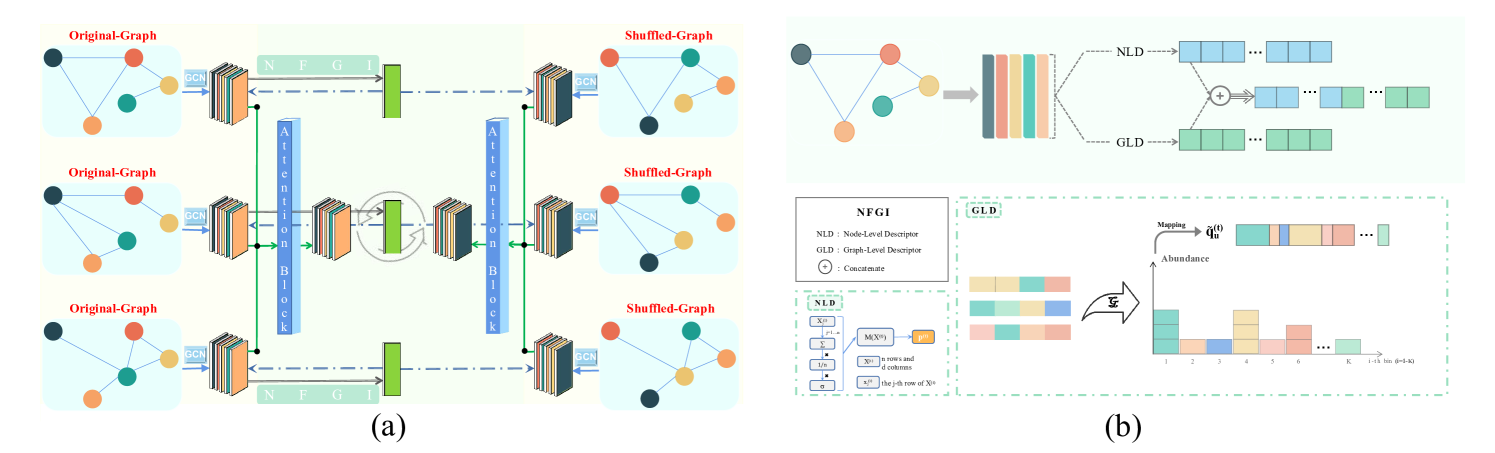
The abundance of intestinal flora is closely related to human diseases, but diseases are not caused by a single gut microbe. Instead, they result from the complex interplay of numerous microbial entities. This intricate and implicit connection among gut microbes poses a significant challenge for disease prediction using abundance information from OTU data. Recently, several methods have shown potential in predicting corresponding diseases. However, these methods fail to learn the inner association among gut microbes from different hosts, leading to unsatisfactory performance. In this paper, we present a novel architecture, Unsupervised Multi-graph Merge Adversarial Network (UMMAN). UMMAN can obtain the embeddings of nodes in the Multi-Graph in an unsupervised scenario, so that it helps learn the multiplex association. Our method is the first to combine Graph Neural Network with the task of intestinal flora disease prediction. We employ complex relation-types to construct the Original-Graph and disrupt the relationships among nodes to generate corresponding Shuffled-Graph. We introduce the Node Feature Global Integration (NFGI) module to represent the global features of the graph. Furthermore, we design a joint loss comprising adversarial loss and hybrid attention loss to ensure that the real graph embedding aligns closely with the Original-Graph and diverges from the Shuffled-Graph. Comprehensive experiments on five classical OTU gut microbiome datasets demonstrate the effectiveness and stability of our method. (We will release our code soon.)
Read more8/1/2024

0
Graph Neural Networks for Gut Microbiome Metaomic data: A preliminary work
Christopher Irwin, Flavio Mignone, Stefania Montani, Luigi Portinale
The gut microbiome, crucial for human health, presents challenges in analyzing its complex metaomic data due to high dimensionality and sparsity. Traditional methods struggle to capture its intricate relationships. We investigate graph neural networks (GNNs) for this task, aiming to derive meaningful representations of individual gut microbiomes. Unlike methods relying solely on taxa abundance, we directly leverage phylogenetic relationships, in order to obtain a generalized encoder for taxa networks. The representation learnt from the encoder are then used to train a model for phenotype prediction such as Inflammatory Bowel Disease (IBD).
Read more7/2/2024
0
Heterogeneous Causal Metapath Graph Neural Network for Gene-Microbe-Disease Association Prediction
Kexin Zhang, Feng Huang, Luotao Liu, Zhankun Xiong, Hongyu Zhang, Yuan Quan, Wen Zhang
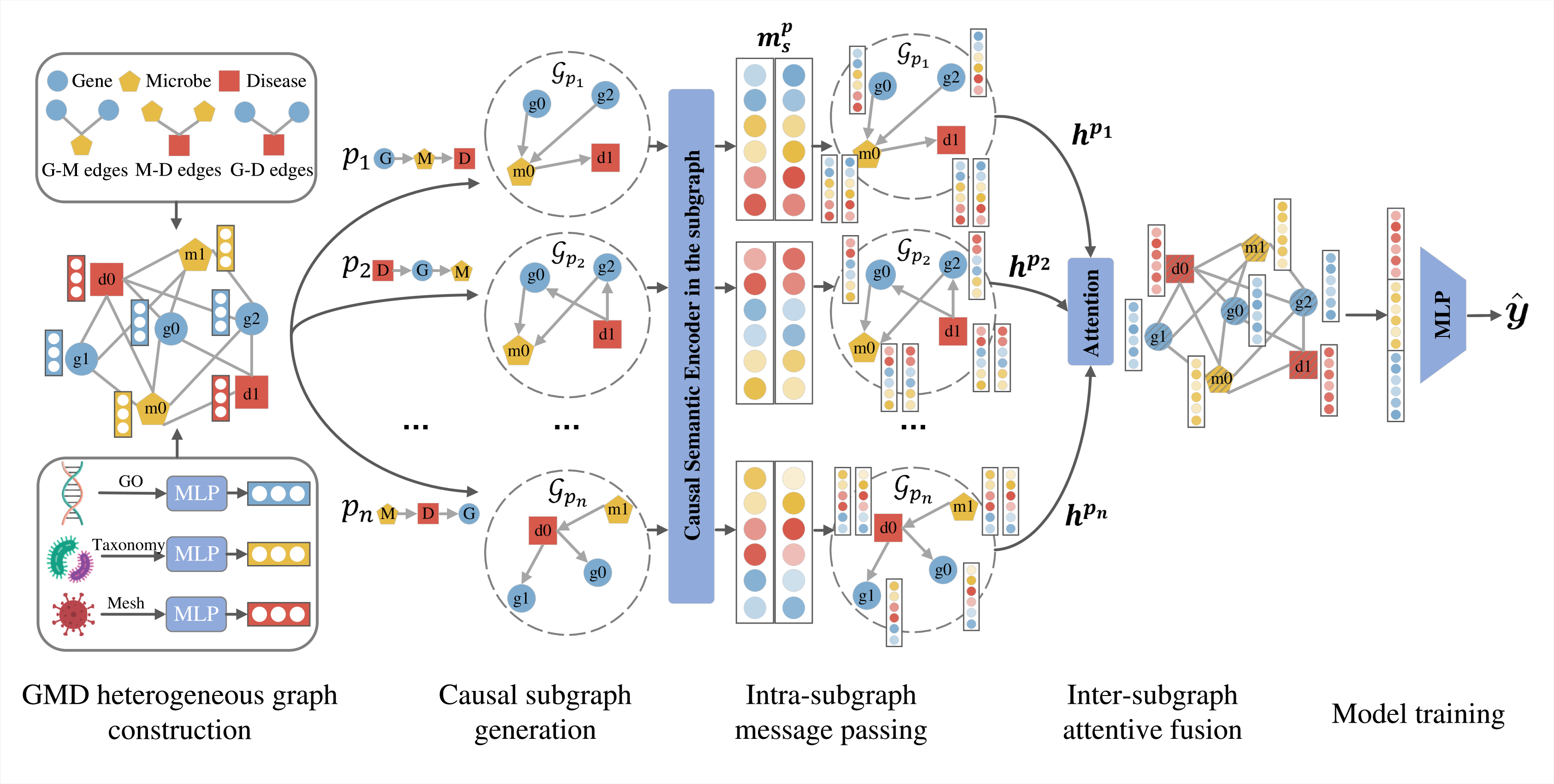
The recent focus on microbes in human medicine highlights their potential role in the genetic framework of diseases. To decode the complex interactions among genes, microbes, and diseases, computational predictions of gene-microbe-disease (GMD) associations are crucial. Existing methods primarily address gene-disease and microbe-disease associations, but the more intricate triple-wise GMD associations remain less explored. In this paper, we propose a Heterogeneous Causal Metapath Graph Neural Network (HCMGNN) to predict GMD associations. HCMGNN constructs a heterogeneous graph linking genes, microbes, and diseases through their pairwise associations, and utilizes six predefined causal metapaths to extract directed causal subgraphs, which facilitate the multi-view analysis of causal relations among three entity types. Within each subgraph, we employ a causal semantic sharing message passing network for node representation learning, coupled with an attentive fusion method to integrate these representations for predicting GMD associations. Our extensive experiments show that HCMGNN effectively predicts GMD associations and addresses association sparsity issue by enhancing the graph's semantics and structure.
Read more6/28/2024

0
Pretrained-Guided Conditional Diffusion Models for Microbiome Data Analysis
Xinyuan Shi, Fangfang Zhu, Wenwen Min
Emerging evidence indicates that human cancers are intricately linked to human microbiomes, forming an inseparable connection. However, due to limited sample sizes and significant data loss during collection for various reasons, some machine learning methods have been proposed to address the issue of missing data. These methods have not fully utilized the known clinical information of patients to enhance the accuracy of data imputation. Therefore, we introduce mbVDiT, a novel pre-trained conditional diffusion model for microbiome data imputation and denoising, which uses the unmasked data and patient metadata as conditional guidance for imputating missing values. It is also uses VAE to integrate the the other public microbiome datasets to enhance model performance. The results on the microbiome datasets from three different cancer types demonstrate the performance of our methods in comparison with existing methods.
Read more8/16/2024